

![High Performance MySQL [Ch.6 | Part 2: Query Performance Optimization]](https://cdn.hashnode.com/res/hashnode/image/upload/v1621417400175/qyhIolXon.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


So in the last article, we discussed the first part of chapter 6 of High Performance MySQL where we talked about how schema design optimization and indexing are necessary for good performance but not solely enough as you still need to write optimized queries otherwise even with the best designed schema and indexes queries will not perform as well as expected.
In the last part we discussed slow queries and how they can be diagnosed and remedied by improving the data access type of certain columns or restructuring the query. In this part, we will discuss query execution basics and how the MySQL optimizes some of the most common queries.
The Query Optimization Process
In this section will skim through the life cycle of a SQL query where it gets turned into an execution plan. This cycle consists of other smaller steps such as, parsing, pre-processing, optimization, etc.
The parser and the pre-processor
The MySQL parser breaks down the query into a set of tokens and builds a parse tree, then it uses the SQL grammar rules to validate the query, i.e. make sure that it's using valid SQL tokens and that everything is in the correct order. The parser is responsible for raising grammar related errors.
The pre-processor then performs some semantic checks on the parse tree that the parser can't check, for example, validate that all mentioned tables and columns in a query do exist. It also resolves names and aliases to make sure that they query doesn't contain any ambiguous references. The pre-processor is also responsible for checking privileges to validate that the query could be run under the constraints of the user's privileges, so for example, there could be a valid DELETE query but the database user doesn't have a delete privilege on that particular table and thus the query is rejected.
The query optimizer
Once the parse tree is valid, the query optimizer initiates the processes of turning it into an execution plan. Because there are often multiple ways for a query to be performed and yet yield the same result, the optimizer tries to find the best way to perform a query.
A database optimizer in general can be either one of two types:
- A cost based optimizer: where the unit of comparing two execution plans is the cost of performing each. The cost can be anything that quantifies how expensive is an execution plan such as, time, data transfer, etc. And the optimizer simply choose the execution plan that scores the least cost.
- A rule based optimizer: where the optimizer has a predefined set of rules that instructs it to perform certain actions if certain preconditions are found. For example, if there is an index on a column, use it. This is a rule based optimization because the optimizer didn't have to do any cost measurements.
Modern optimizers can usually be a mix of both. The MySQL optimizer is mainly a cost based optimizer but it performs some rule based optimizations as well. The unit of cost for the MySQL optimizer was originally the random read of a \(4KB\) page but it has evolved a lot since then and now includes more sophisticated cost measures such as the estimated cost of performing a WHERE clause comparison.
The MySQL server keeps its cost measure of the last performed query in an variable called Last_query_cost which can be inspected by running:
SHOW STATUS LIKE 'Last_query_cost';
Note that the cost measure is just an estimate based on statistics: the number of pages per table or index, the cardinality (number of distinct values) of the indexes, the length of the rows and keys and the key distribution.
The optimizer might not always choose the best plan however, and this can happen for so many reasons such as:
- The statistics that the optimizer bases its estimates on could range from very accurate to wildly wrong. Most of the statistics that the optimizer uses are storage engine statistics that it obtains by communicating with the storage engine which vary in the type and the accuracy of the statistics they keep. For example, InnoDB doesn't have an accurate statistics about the number of rows in a table due to its MVCC architecture.
- The used metrics are not always equivalent to the true cost of executing the query because for example, an execution plan that reads more pages might perform better than that which reads less pages if the reads of the first plan are sequential I/Os or if it reads many pages that are cached and so on. There is no accurate 1:1 mapping between the estimated cost of an execution plan and the actual cost.
- The optimizer's idea of optimal might not be aligned with our perception of an optimal query because as we saw, MySQL tries to minimize random reads which would usually reflect into minimizing the execution time but not always as we mentioned in the previous point.
- The optimizer doesn't take into account the cost operations not under its control such as, executing stored functions or user-defined functions.
The optimizations performed by the query optimizer have two main types:
- Static optimizations: You can think of this type of optimizations as compile-time optimizations such as transforming a
WHEREclause into an equivalent but more efficient algebraic form. This type of optimizations is only performed once per query. - Dynamic optimizations: You can thin of this type of optimizations as runtime optimizations which depend on live statistics such as the values in the
WHEREclause or how many rows in the index, etc. It's obvious that this type of optimizations will have to be performed each time the query is executed to get the latest statistics.
Now let's take a look at some of the optimizations that the MySQL optimizer performs:
- Reordering joins: Tables can be joined in so many different ways than the way specified in the query and it often the case that one order of join would be much better than the rest. So MySQL re-orders the joins to be able to make use of a better join order the one mentioned in the query (we will talk more about this later on).
- Covering
OUTER JOINintoINNER JOIN: AnOUTER JOINdoesn't necessarily have to be executed as anOUTER JOINand can instead be turned intoINNER JOINSbased on some factors such as the table schema or aWHEREclause that disallows or filters outNULLvalues. AnINNER JOINis better because it doesn't try to produce rows that will later be filtered out. - Applying algebraic equivalence rules: MySQL is able to perform algebraic transformations to canonicalize expressions such as, the term \((5=5 \hspace{0.4cm} AND \hspace{0.4cm} a>5)\) will reduce to just \(a>5\).
COUNT(),MIN()andMAX()optimizations: Indexes and columns nullability can play a vital role in optimizing those types of queries. For example, to find theMIN()of a column, we just need to fetch the left-most node in the B-tree index and thus the server can read the first row in the index. Similarly, to find theMAX()value in a B-Tree index, the server reads the last row of the index. Likewise,COUNT(*)can also be optimized in some storage engines like MyISAM which keeps an accurate count of the number of rows in each table.- Evaluating and reducing constant expressions: When MySQL detects that an expression can be reduced into a constant it does so at the beginning of the query. This can range from very simple reduction of mathematical expressions to some fairly complex reductions such as, performing queries that would yields constants first and then propagate the constant value everywhere else in the query. So for example, if we performed the following query:
EXPLAIN SELECT films.film_id, film_actor.actor_id FROM films INNER JOIN film_actor USING(film_id) WHERE films.film_id = 1;EXPLAINcompacted result:
| table | type | key | ref | rows |
| films | const | PRIMARY | const | 1 |
| film_actor | ref | idx_fk_film_id | const | 10 |
Which indicates that MySQL chose to first perform the constant lookup on the films table to find the desired row with id = 1 then in the second step, MySQL treads the film_id found from the first step as a constant everywhere else in the query. It can do this because the optimizer knows that by the time the query reaches the second step, it will know all the values from the first step. Notice that the film_actor table’s ref type is const , just as the films table’s was.
- Covering indexes: MySQL would attempt to use covering indexes if available because as discussed in an earlier article, covering indexes would contain all the columns in the
SELECTstatement and it would help MySQL avoid reading rows. - Subquery optimization: MySQL can convert some types of subqueries into more efficient alternative forms, reducing them to index lookups instead of separate queries.
- Early termination: MySQL can detect impossible conditions such as,
WHERE a = 5 and a = 4and terminates the query quickly or even show a semantic error in the parsing and preprocessing phase. Queries can also be valid and get early terminated and an obvious example for this is theLIMITclause that terminates once the needed limit is achieved. Similar early termination techniques are used inDISTINCT,NOT EXISTS(), andLEFT JOINqueries. - Equality propagation: MySQL recognizes when a query holds two columns as equal, for example, in a
JOINcondition and propagatesWHEREclauses across equivalent columns. For instance in the following query:SELECT film.film_id FROM films INNER JOIN film_actor USING(film_id) WHERE films.film_id > 500;WHEREclause doesn't only apply to thefilmstable, but also to thefilm_actortable because thefilm_idcolumn is hold in equality in both tables via theUSINGclause. This can help scan less rows in thefilm_actortable than if we didn't have this optimization. IN()list comparisons: MySQL sorts values in theIN()list and performs binary search in \(O(log(n))\) instead of a linear search in \(O(n)\) where \(n\) is the size of theIN()list.
The preceding list is woefully incomplete because MySQL performs more optimizations than could be fit into a chapter in the book. It's meant to give a glimpse of how powerful is the MySQL optimizer.
The Join Optimizer
Now that we discussed some of the general optimizations that MySQL performs, let's discuss how MySQL performs JOINs and how it specifically optimizes them considering that they are one of the most expensive queries to perform.
The common notion that people have about JOINs is that they are performed to find matching rows in multiple tables. MySQL extends this definition to include all queries not just all tables which includes subqueries (whose results get stored in temporary tables) and this also applies to UNION clauses because virtually, it's performing a join.
As you may have heard before, a JOIN can be performed in two different ways:
- A nested loop join: where tables are scanned in a nested loop fashion to find matching rows.
- Hash join: Where some tables are scanned and equality conditions are performed against other tables but using a hash index that reduces the complexity of those
JOINs.
As you may already know, MySQL uses the nested loop join strategy because it's more general and doesn't require any special indexes to work. This means MySQL runs a loop to find a row from a table, then runs a nested loop to find a matching row in the next table. It continues until it has found a matching row in each table in the join. It then builds and returns a row from the columns named in the SELECT list. It tries to build the next row by looking for more matching rows in the last table. If it doesn’t find any, it backtracks one table and looks for more rows there. It keeps backtracking until it finds another row in some table, at which point it looks for a matching row in the next table and so on.
To understand this better, let's consider the following example:
SELECT tbl1.col1, tbl2.col2
FROM tbl1 INNER JOIN tbl2 USING(col3)
WHERE tbl1.col1 IN(5,6);
What MySQL does can be represented by the following pseudocode:
outer_iter = iterator over tbl1 where col1 IN(5,6)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
while inner_row
output [ outer_row.col1, inner_row.col2 ]
inner_row = inner_iter.next
end
outer_row = outer_iter.next
end
As we can see, the previous pseudocode can be easily applied on a single table as it it's on multiple tables. It can also be easily extended to perform OUTER LEFT joins as follows:
outer_iter = iterator over tbl1 where col1 IN(5,6)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
if inner_row
while inner_row
output [ outer_row.col1, inner_row.col2 ]
inner_row = inner_iter.next
end
else
output [ outer_row.col1, NULL ]
end
outer_row = outer_iter.next
end
The nested JOIN strategy can also be visualized by what's called a swim-lane diagram as follows:
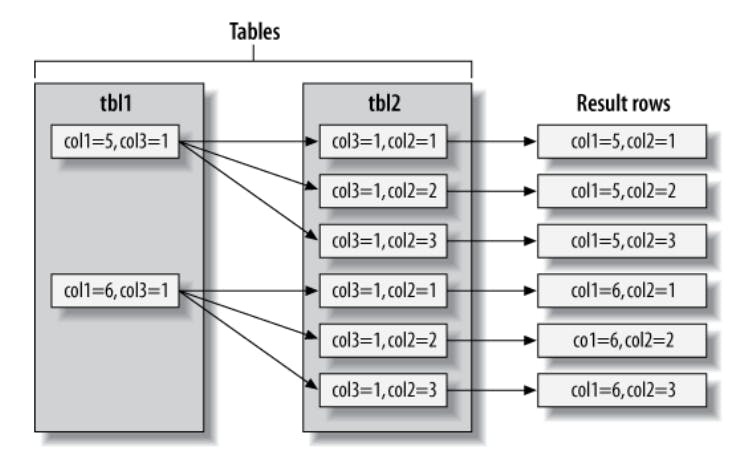
MySQL performs subqueries and UNION clauses on derived or temporary tables to be able to use the same JOIN strategy. It also coerces RIGHT OUTER JOINs into LEFT OUTER JOINs in order to use the same strategy in the pseudocode above.
It’s not possible to execute every legal SQL query this way, however. For example, a
FULL OUTER JOIN can’t be executed with nested loops and backtracking as soon as a table with no matching rows is found because it might begin with a table that has no
matching rows. This explains why MySQL doesn’t support FULL OUTER JOIN.
Now that we know how MySQL performs JOINs, let's take a look how the optimizer tries to make them more efficient, mainly by reordering them. Let's take the following query as an example:
SELECT films.film_id, films.title, films.release_year,
actors.actor_id, actors.first_name,
actors.last_name
FROM films
INNER JOIN film_actor USING(film_id)
INNER JOIN actors USING(actor_id);
We can think of many different ways the previous query might be executed, like for example, MySQL could start with the films table and use the index on film_id in the film_actor table to fetch the actor_id values which it will later use to probe into the actors table to fetch the actor data needed. But is that the best way to do this? Let's take a look at how MySQL chose to perform this JOIN:
| table | type | ref | rows |
| actors | ALL | NULL | 200 |
| film_actor | ref | actors.actor_id | 1 |
| films | eq_ref | film_actor.film_id | 1 |
We can quickly notice that is a very different execution plan that we may have thought would happen. In this optimal execution plan, MySQL chose to start with the actors table and go in the reverse order, but let's see why is this more efficient. Let's force MySQL to stick to the specified JOIN order in the query by using the STRAIGHT_JOIN keyword and let's inspect the EXPLAIN result of that. It will looks as follows:
| table | type | ref | rows |
| films | ALL | NULL | 951 |
| film_actor | ref | films.film_id | 1 |
| actors | eq_ref | film_actor.actor_id | 1 |
This shows why MySQL wants to reverse the join order: doing so will enable it to examine fewer rows in the first table. In both cases, it will be able to perform fast indexed lookups in the second and third tables. The difference is how many of these indexed lookups it will have to do:
- Placing film first will require about 951 probes into
film_actorandactors, one for each row in the first table. - If the server scans the
actorstable first, it will have to do only 200 index lookups into later tables.
It's obvious that MySQL will not be able to check all possible JOIN orders for any given query, but for example, a 20 table JOIN can be executed in up to \(3,628,800\) different ways. When the search space grows too large, it can take far too long to optimize the query, so the server stops doing a full analysis. Instead, it resorts to shortcuts such as greedy searches when the number of tables exceeds the limit specified by the optimizer_search_depth variable.
The Execution Plan
MySQL doesn’t generate byte-code to execute a query, as many other databases do. Instead, the query execution plan is actually a tree of instructions that the query execution engine follows to produce the query results. The final plan contains enough information to reconstruct the original query.
What's next?
In the next part of this article we will discuss the Query Execution Engine and go deeper into how to optimize certain types of queries such as JOIN, COUNT(), subqueries, GROUP BY, UNION, LIMIT and OFFSET, etc.
References
High Performance MySQL: Optimization, Backups, and Replication
Previous Articles
Checkout previous articles in this series here: