![High Performance MySQL [Ch.1: MySQL Architecture and History]](https://cdn.hashnode.com/res/hashnode/image/upload/v1618599673460/Y41Y0HJoS.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


So a couple of weeks ago, one of my colleagues at Instabug recommended this book called High Performance MySQL to me. I started reading and then I decided that I would write a form of summaries or personal notes so to speak based on the book. This article covers chapter 1 titled MySQL Architecture and History. This chapter doesn't really have that much new information but it's a good recap of the basics before it goes into more detailed discussions.
This chapter provides a high-level overview of the MySQL server architecture. It starts by a discussion of MySQL's logical server architecture, it proceeds to discuss topics such as connection management, query optimization and execution, concurrency control, transactions and finally a discussion of the different MySQL storage engines. Many of those topics have dedicated chapters to them so they will only be discussed briefly in this chapter.
MySQL's Logical Architecture
A MySQL setup consists of three layers as shown in the figure below:
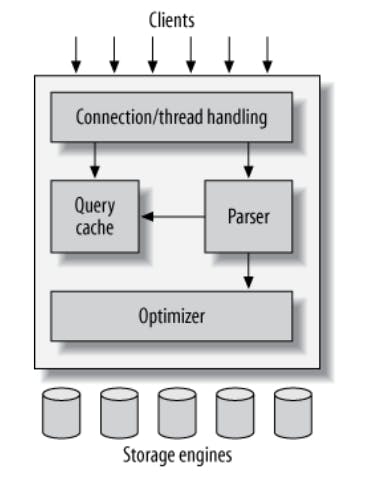
The topmost layer handles connection pooling, security, authentication and so on. This layer that's not really specific to MySQL or rather to any Database system, but a layer that any client/server system would probably need to implement.
The second layer is considered the brains of MySQL, this layer is responsible for query parsing, analysis, query optimization, caching, etc. It also houses any functionality that's available across all storage engines such as stored procedures, views, triggers and so on.
And the third layer is storage engine(s), this layer is responsible for storing/retrieving data. It basically acts the file system in the database. It's key here to notice that the storage engines layer is not considered part of the MySQL server as the server can communicate with a variety of storage engines via a storage engine API which allows the storage engine to receive explicit commands to perform certain operations, such as, fetch this record, insert this record without the need to parse queries (with a few exceptions). Another key insight here is that the server components are global to all databases within that server, but the storage engine is a per table configuration, meaning, that you can configure which table uses which storage engine based on the needs and the trade offs you are willing to take.
Connection Management and Security
A MySQL server is expected to process multiple queries from multiple clients. Each client gets its own thread within the server process through which all queries from that client are processed. So when a client initializes a database connection it's assigned a thread within the server process. Creating and destroying threads is an expensive process, that's why most systems that need to handle connections implement connection pooling where the system caches those threads in a pool of connections and re-uses the threads for multiple clients. This also helps limiting the number of concurrent clients at the system's desired capacity.
Any connection to MySQL needs to be authenticated via a variety of authentication methods including passwords, hosts, usernames, SSL certificates, etc. Once a connection is authenticated, that doesn't mean that all queries can be processed from that connection. MySQL implements a privileges system that allows database administrators to grant certain permissions to certain users, such as, preventing non-root users from deleting tables or giving a certain user a read-only access, etc.
Optimization and Execution
When a connection to MySQL sends a query, it gets parsed and internal structure called a parse tree is created. MySQL applies a wide range of optimizations to that structure including re-writing the query, re-arranging certain operations, deciding which indexes to use and much more. Query hints can be passed to MySQL to affects its decision making process, like forcing it to use an index and so on. Also the EXPLAIN instruction can be used to know how MySQL intends to execute a query.
The Query Optimizer is storage engine independent in the sense that it doesn't really care which storage engine is used, but it communicates with storage engines to ask for its capabilities and get metrics on how much certain operations cost which affects its decision making process. This guarantees that the Optimizer would generate a suitable execution plan for any storage engine. The book mention that there will be a detailed discussion in chapters 4, 5, 6.
MySQL also has a Query Cache that it refers to before executing the query. The cache can only have SELECT statements along with their corresponding result set and it can directly return that result without further steps (if the entry is in the cache, it means that it's still valid). Personally, I was wondering about the internals of what actually is cached and how it gets invalidated, the book mentions that there will be a detailed discussion of this in chapter 7.
Concurrency Control
Like any system that has to handle multiple and possibly competing operations at the same time, MySQL needs to handle multiple queries at the same time while keeping data integrity and high performance.
I will use the book's example of a mailbox file that's shared between multiple clients. If one client is trying to add a new entry to the mailbox at a time, then no problem, but it will often be the case that multiple clients would be adding entries to the mailbox at the same time which will cause data corruption if not handled correctly. The trivial idea of locking the mailbox simply serializes the insertion in the mailbox effectively making it single threaded which is a major performance hit but it guarantees integrity of data. On the other hand, reads from the mailbox doesn't seem as troublesome, there is nothing wrong with 2 clients reading from the mailbox at the same time, but in some cases where another client is writing/deleting from the mailbox, the reading clients can have inconsistent data, so even reads needs to be locked sometimes. A read operation needs to acquire a read lock or otherwise called a shared lock because as we said, nothing wrong with 2 clients reading at the same time, on the other hand, a write operation needs a write lock or otherwise called an exclusive lock, this type of lock prevents other read and write operations from taking place at the same time as long as this lock is still not released.
As one might imagine, locking causes lock contention and makes the system slower, so the choice of when to lock and what to lock is key to mitigating this performance hit which brings us to lock granularity.
Lock granularity tries to improve performance by being more selective about what to lock, like for example, if we can lock just parts of the shared resource that would be far better than locking the entire resource, better yet, lock the exact piece of data that you need to protect. On the other hand, figuring out which parts of the data to lock introduces a lot of overhead which also negatively affects performance. So let's discuss some of the possible granularity levels:
Table Locks: This is the simplest type of locks and the one with the least overhead. It's analogous to the mailbox example. When a connection issues a write operation (
insert,update,delete, ...) it acquires a write lock (exclusive lock) which stops all other read and write operations. When a connection issues a read operation (select), it acquires a read lock (shared lock) which is only granted if there are no write locks on the table (there can be other read locks). A write lock takes precedence over read locks in the lock queue, also a read lock can be promoted to a write lock in the same connection.Row Locks: As opposed to table locks, row locks only lock certain rows within the table, so naturally this offers the greatest concurrency but it comes with the greatest overhead of figuring out which rows to lock. This type of locking is the most widely used and it uses the same
read/writelock mechanism mentioned above but on the row level.
It's worth mentioning that table locks are server level locks while row locks are storage engine locks.
Row locking is quite interesting, the innoDB engine does row locking on inserts, at first I was lead to believe that when we insert 1 record, we lock 1 row, but turns out that are many cases where more rows will be locked (sometimes called next-key locking). This is not mentioned in the book at this point, but for example, let's consider the case where we have a table with column called name and we have a unique index on that column. Let's say we already have the following records:
+----+------+
| id | name |
+----+------+
| 1 | ggg |
| 2 | jjj |
+----+------+
Now if we try to insert a record with name ppp, innoDB would need to lock the gap between jjj to ppp in the index (this solves a problem called phantom reads that will discuss later). It's easy to see that concurrent inserts could cause innoDB to lock overlapping gaps which sometimes can even lead to deadlocks.
The book somewhat portrays table locking and row locking as opposing options, so you get either, maybe that changes with any further discussion over the coming chapters. But anyways, both types of locks are used in databases as some operations require table locks such as most ALTER TABLE operations while other operations can be performed with only row locks. I believe MySQL Reference is a better source of information here since things change over releases.
Transactions
Transactions are a very common concept for database systems. A transaction allows you to group certain operations that are not atomic by default into an atomic construct that implements an all or nothing functionality, meaning, either the transaction succeeds and all its operations are performed or the transaction fails and none of its operations is performed.
The most common example here, which is also the example that the book uses is a bank transaction that takes a certain amount of money from a checking account and deposits it into a savings account. It looks something like this:
1: START TRANSACTION;
2: SELECT balance FROM checking WHERE customer_id = 1;
3: UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 1;
4: UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 1;
5: COMMIT;
Let's say we performed instructions 2, 3, 4 without it being in a transaction. If instruction 3 succeeded and subtracted $200 from the checking account but later instruction 4 failed to add the same amount to the savings account, the database will end up in an inconsistent state where $200 disappears in thin air. When the whole thing is wrapped in a transaction, this guarantees that if instruction 4 fails, instruction 3 will be rolled back and it would be as nothing ever happened.
But the more you examine this, the more you realize that a transaction itself is not enough unless the system is ACID. So what's is an ACID transaction?
Atomcity: Means that a transaction should work as indivisible unit that either completes to success or gets rolled back on failures (this is the all or nothing we discussed above).
Consistency: Means that the database only moves from one consistent state to another so any changes done by a transaction don't reflect unless that transaction is committed.
Isolation: Means that there should be a level of control of on when changes done by a transactions are visible to other transactions. Let's consider the case when a bank statement summary query runs to get the user checking account details and it runs between statement 3 and 4. In this case it makes sense that as long as the transaction didn't yet complete, the checking account shouldn't show up missing $200. Isolation has many levels that we will discuss later.
Durability: Means that once a transaction is committed, the changes are permanent and no data is lost during a crash. Of course, nothing is 100% durable, and durability is implemented differently to offer different guarantees. For example, in some system, a change has to be applied to a subset of replicas before it's acknowledged, this guarantees that if a replica crashes, the data is available on another replica. It's easy to see that the more durability guarantees a system provides, the more overhead it incurs on performance.
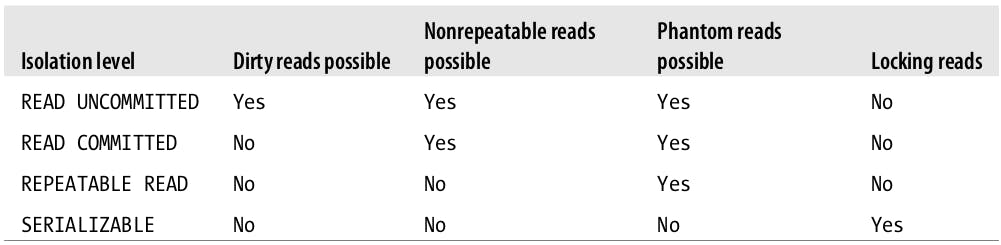
Isolation Levels
As discussed above, Isolation is one of the ACID properties but it has many levels. Here we discuss the main difference between those levels:
READ UNCOMMITED: As the name suggests, in this isolation level transactions can view the changes done by other un-committed transactions. This is also known as dirty reads which is rarely used in practice as it doesn't offer significant performance improvements over other levels and it introduces a very problematic behavior.
READ COMMITED: As the name suggests, in this isolation level transactions can only view the changes done by other transactions if they committed before this step at the transaction began. This level allows non-repeatable reads as the same
SELECTcan be issued twice within the same transaction and yield different data because other transactions might be committing in between queries within a transaction. So for example if transaction 1 reads the balance and it's $200 while transaction 2 updates the balance to be $250 and successfully commits, then transaction 1 reads the balance again it will get $250 and not $200. This is the default level in many databases such as PostgreSQL but not MySQL.REPEATABLE READ: This isolation level solves the problem highlighted in
READ COMMITEDas it guarantees that rows of data will look the same for all queries within the same transaction regardless of what other concurrent transactions might be doing. This level however introduces another problem called Phantom Reads which happens when a transaction selects a range of rows then another transaction inserts a new row in that range then you select the same range again and it will return the new "phantom" row. This problem is handled by multiversion concurrency control (discussed later). This isolation level is MySQL's default isolation level.SERIALIZABLE: This isolation level solves the phantom read problem by forcing an order on transactions so two transactions may never conflict. It also places read locks on every row that it needs to read. This level is the most strict isolation level, it causes lots of timeouts and lock contention and is rarely used.
The following table summarizes the 4 isolation levels.
Deadlocks are a fact of life when it comes to transactions, for example if there are circular dependencies between transactions. Most database systems have mechanisms to handle deadlocks such as timeouts and some are even advanced enough to spot the circular dependencies during query parsing and return errors before execution can take place. If a deadlock happens during a transaction, most of the time, the transaction with the fewest exclusive locks is rolled back.
Multiversion Concurrency Control
Row locking is not good enough as a performance improvement, that's why most MySQL transnational storage engines don't solely depend on it. Instead a mix of row locking and multiversion concurrency control (MVCC) is used to avoid the need for locking at all in many cases. This allows non-blocking reads and only locking necessary rows during writes.
MVCC in MySQL works by keeping a snapshot of the database at a certain point of time which allows operations within the same transaction to be served by the same snapshot and thus have a consistent view of how the data was when the transaction began regardless of how long it runs. This means that different transactions can see different data from the same table at the same time.
The way InnoDB implements MVCC is by keeping 2 extra hidden columns, one represents when the version of this row was created and the other presents when the version of this row expired but rather than saving the actual timestamp, it saves a monotonic system version number that increases when a new transaction begins. Each transaction has its own record of the system version number when the transaction began and it uses that number to access the correct version as highlighted below (assumes REPEATABLE READ isolation level):
- SELECT: InnoDB has to find rows with a creation version number less than or equals to the transaction version number, this ensures that those records either already existed before the transaction began (version number is less than the transaction's version number) or were inserted/altered by the same transaction (version number is equal to the transaction's version number). It also has to check that those rows have an undefined deletion version number (row is not yet deleted) or it has a deletion version number greater than the current transaction version number (it was later deleted by another transaction that came after this one).
- INSERT: InnoDB records the current system version number as the creation version number of the inserted row.
- DELETE: InnoDB records the current system version number as the deletion version number of the deleted row.
- UPDATE: InnoDB inserts a new copy of the altered row and it sets its creation version number to the current system version number, it also sets the current system version number as the old record's deletion version number.
The upside of all the extra record keeping in MVCC is that now read operations need not acquire locks at all and they can read data that match the aforementioned criteria as fast as they can. The obvious downside is the extra storage needed to save all those snapshots, but compared to time, it's a trade off worth taking.
It's worth mentioning that MVCC only works with READ COMMITTED and REPEATABLE READ isolation levels.
MySQL's Storage Engines
Lastly, we take a look at some of the most common storage engines in MySQL (will only discuss 2).
InnoDB
InnoDB is the default transactional storage engine for MySQL (and yes, some MySQL storage engines are not tranascational).
InnoDB saves its data in a series of data files collectively known as table space. It defaults to REPEATABLE READ isolation level that is combined with MVCC to achieve high concurrency.
InnoDB uses a clustered index structure which defines the way data is stored in the table sorted ascendingly by their primary key which results in extremely fast primary key look ups. On the other hand, secondary indexes will have to contain the primary key as a part of them so it's recommended to always use small primary keys because if the primary key is large, it will make all other secondary indexes large as well.
InnoDB implements a variety of internal optimizations such as read-ahead which pre-fetches data from disk that it predicts it will need to read later, insert buffers for bulk inserts, etc. This part is covered later in the book.
MyISAM
MyISAM is one of MySQL's non-transactional storage engines (it doesn't support transactions) but it provides other useful features such full-text indexing and compression.
MyISAM's biggest weakness as the book discusses is that it's not remotely crash safe, so it's suitable for systems that are not transaction based and not that dependent on being crash safe (small tables that won't take much time to repair).
MyISAM locks entire tables not rows as opposed to InnoDB. Readers will have to acquire shared read locks on all tables it needs to read data and writers will acquire exclusive write locks.
One of the interesting features of MyISAM however is its ability to support full-text search as it allows indexing the first 500 characters of BLOB or TEXT fields. This allows MyISAM to serve some complex word search queries.
Another very interesting feature that's useful for read only systems is compression. MyISAM allows you to compress tables that don't change. Compressing a table doesn't allow you to alter it in any way, but you can always decompress, modify it and recompress.
Selecting the Right Storage Engine
InnoDB and MyISAM are not the only storage engines available, in fact there are a dozen more which brings forward the question of how to choose the suitable storage engine.
When choosing a storage engine, there are some factors to consider:
- Transactions: If your application requires transactions, then you have to use a transactional storage engine like InnoDB, but if it doesn't and it primarily issues SELECT and INSERT then maybe you can get away with using something like MyISAM.
- Backups: InnoDB is capable of performing online backups, that is to say that an InnoDB table can be backed up without having to take it down for maintenance. So if your system requires taking regular online backups then using InnoDB or similar engines is a must, but if you can afford to take the DB down for backup or don't need backup at all then you can choose other engines.
- Crash Recovery: If a table has a lot of data, crash recovery becomes a pressing matter because if your tables can become corrupt more often, you will be spending a lot of time to repair them. MyISAM table are notorious of going corrupt frequently. This is, as the authors say, one of the reasons to use InnoDB even if you don't need transactions.
- Special features: As mentioned before each storage engine offers a set of features that might not be available in other engines, so if a feature set matches your case, you will probably have to go with that option.
There are lots of other factors and uses cases to consider.
As mentioned before, a storage engine is a per table configuration, so there is nothing that stops you from having an InnoDB table and a MyISAM table in the same database. The book authors recommend against this however as it exposes you to many edge cases and weird bugs. It's also worth mentioning that converting a table from one storage engine to another is quite doable.
References
High Performance MySQL: Optimization, Backups, and Replication