![High Performance MySQL [Ch.5: Indexing for High Performance]](https://cdn.hashnode.com/res/hashnode/image/upload/v1618659509791/C_-GQoTgp.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


So the last article discussed chapter 4 of High Performance MySQL titled Optimizing Schema and Data Types. Today's article discusses chapter 5 titled Indexing for High Performance.
In the last chapter we discussed schema design choices and optimization, but having a good and an efficient schema is not the whole story. Having indexes is critical for good performance specially as the database grows. Indexing optimization is the most powerful way to improve query performance as choosing the correct indexes can improve performance by orders of magnitude in many cases, so it's essential to have a good understanding of indexes and how they work and how to employ them to your benefit.
This chapter starts by discussing the basics of indexes, their types and their benefits. Then it goes on to discuss indexing strategies, such as, choosing the indexed columns, choosing the columns order, clustered indexes, covering indexes and how performance is affected by redundant, duplicate and unused indexes. It ends with a case study on indexes that puts everything together in a toy project.
Indexing Basics
So the easiest way to visualize how an index work is to compare it to a book's index. When you need to find a certain topic in a book, you look up the index for that topic and it gives you a page number and then you look up that page number to find what you need. This is exactly what an index does (more or less) as when a query is executed and the storage engine sees that it can use an index to serve that query, it looks up the index structure and finds the needed value.
Types of Indexes
There are a bunch of index types that differs in how they store data and which types of queries they can serve, but perhaps the most famous type and what most people usually refer to when they say an index is the B-tree index. There are however some other types such as hash indexes, spatial (R-tree) indexes, full text indexes, etc. So let's take a look on some of the important types and see how they differ.
B-tree Indexes
B-tree is the most common index type and it's important to note that a B-tree index is not necessarily a B-tree data structure as some storage engines such as InnoDB implements it as a \(B^+ tree\) while other storage engines such as NDB cluster implements it as a T-tree, but the concept is the same. Also, different storage engines implement the same B-tree differently which affects performance (more on that later).
The general idea of a B-tree structure is that all the values are stored in-order and the tree is balanced (i.e. all leaf nodes are at equal distance from the root node). A B-tree has 3 types of nodes, namely, a single root node, internal node(s) and leaf node(s). The root node is where the tree starts, the internal nodes store the index keys which are used to compare the look up value against to determine at which direction the tree traversal should proceed and finally the leaf nodes is where the indexed data is stored.
As mentioned before, storage engines implement B-trees differently, so for example, MyISAM uses prefix compression to make the index smaller but InnoDB leaves values uncompressed. Also MyISAM stores physical locations of the rows in leaf nodes while InnoDB stores their primary keys. We will see later how these choices affect performance.
The following diagram shows an example of a B-tree index (root node omitted).
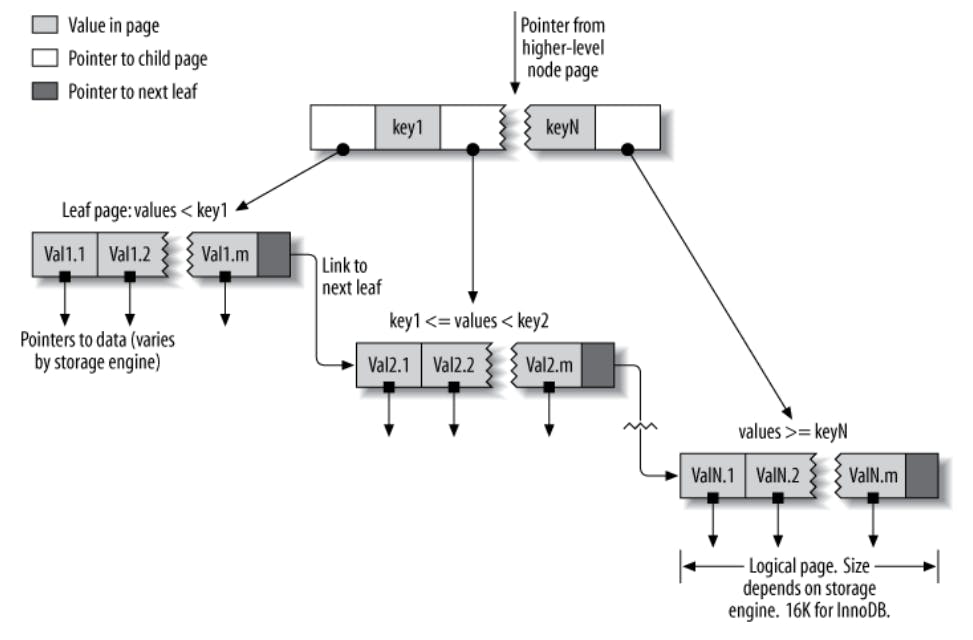
To be able to understand this fully, let's try to traverse the tree for a value that is less than key1. When we reach the internal node, we compare the look up value against key1 and find out that it's smaller and because we know the tree stores values that are smaller than key1 in the left subtree, then we can go left and find the leaf node corresponding to our search. What happens after a leaf node is reached is storage engine dependent, for MyISAM, it will use the physical address stored in the leaf node to immediately fetch the row while in InnoDB, it will use the primary key stored in the leaf node to do another lookup in the primary key index to find the row.
In many cases, a B-tree index might have more than 1 indexed column, in which case the order of the columns in the index is very important as it determines what sort of queries the index can serve. To be able to understand this bit, let's first take a look at how a multi-column index is stored in a B-tree. The following is an index on (last_name, first_name, date_of_birth) columns in some table.
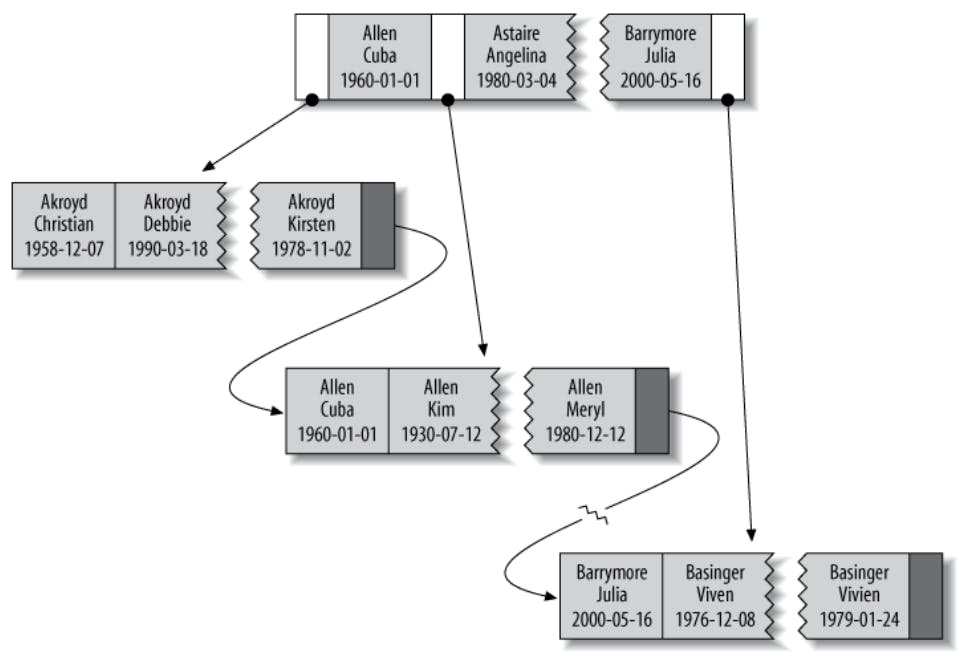
As we can see the left most key in the internal node has the value Allen for the last_name column and thus the left subtree will have last_name values that are less than Allen so for example here, it's Akroyd, while the right subtree will have last_name values that are greater than or equal to Allen as we can see. Now let's take a closer look on the left subtree, we will see that all nodes have the same value Akroyd for the last_name column and so the index sorts those records by the next column in the index which is the first_name column and because all records have distinct values for the first_name column, the date_of_birth order is irrelevant. But for example, let's take a look at the rightmost subtree, we can see that the last 2 records both have the value Basinger for the last_name column and the value Vivien for the first_name column, so they are ordered by the third column in the index which is the date_of_birth.
Now that we know how the index is constructed, let's discuss how it can be helpful and for which types of queries. This index can serve the following queries:
- Match the full value: The index can serve a match on a value for the full key (all columns stored in the index), so for example, it can serve a query looking for a person named
Cuba Allenborn in1960-01-01. And this is easy to understand as it will traverse the tree in order and use the index columns in-order to find the needed value. - Match a leftmost prefix: The index can serve queries performed on a left most prefix of the index columns, so for example, queries looking for all people whose
last_nameisAllen. This might be a bit confusing for some, but to understand this clearly, let's say we want to find people whosefirst_nameisCuba. As we traverse the index, we will not be able to determine the traversal direction because nodes are sorted by thelast_namecolumn first and then by thefirst_namecolumn. This why multi column indexes can only serve queries that use a leftmost prefix of the index columns. - Match a column prefix: The index can serve queries looking up the first part of a column's value (the column has to be a leftmost prefix of the index as highlighted above), so for example, we can use the index to find all people whose
last_namestarts with aJ. - Match a range of values: The index can serve queries looking for a range of values for a column that's a leftmost prefix of the index columns, so for example, queries looking for all people whose
last_nameis betweenAllenandBarymorecan be served from the index. - Match one or more columns exactly and a range or a part on the next column: This is an extension of the two previous use cases because if we fixed the value for one column, we can do a range on the next column or a part of the next column, so for example, queries looking for all people whose
last_nameisAllenand whose first name is betweenChristianandKirstenor whosefirst_namestarts with aK.
It's also worth mentioning that B-tree indexes are not only useful to finding values in arbitrary order, they can also be used to find values in ORDER BY clauses because the values are sorted in the index so they can be fetched in a certain order.
B-tree indexes have some limitations:
- As mentioned before, they can't be used to find values by columns that are not a leftmost prefix of the index columns (this why the order of the columns in the index is very important).
- Queries can't skip columns in the index, so for example, it can't serve queries looking for people whose
last_nameisAllenand who are born in1976-12-23because it skipped thefirst_namecolumn, or in other words(first_name, date_of_birth)is not a leftmost prefix of the index columns. - The storage engine can't optimize access to any columns to the right of the first range condition, so for example:
WHERE last_name="Smith" AND first_name LIKE 'J%' AND date_of_birth='1976-12-23'date_of_birthpart of the condition because of the range query on thefirst_name.
Some of these limitations are not inherent to B-Tree indexes, but are a result of how the MySQL query optimizer and storage engines use indexes. Some of them might be removed in the future.
Hash Indexes
A hash index as the name suggests is built on top of a hash table where all columns of the index are hashed and the hash value is used to lookup those keys. In MySQL, explicit hash indexes are only available for the memory storage engine and they are the default type for memory tables. The memory tables also support non-unique hash indexes as it stores values with the same hash (in case of collisions) in the same key as a linked list that it will have to examine each element in order to find a certain value.
To understand this better, let's assume we have the following table:
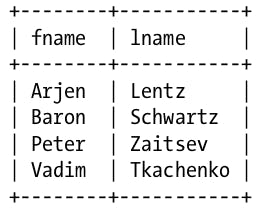
And let's say we define a hashed index on the fname column using some hash function \(hash = f(fname)\) that produces the following values:

Then the hash index structure will look as follows:
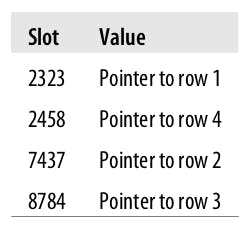
So when we execute a query with WHERE fname = 'Peter', it will calculate the hash of Peter using the same hash function, so \(f('Peter') = 8784\) and then it will look up the index and find a pointer to row 3, then it will fetch the row.
Notice that because hashed indexes store only a hash of possibly multiple index columns, it's usually smaller and in many cases has a fixed size, this is why hashed indexes are very compact and they serve look ups lightning fast, but the have some limitations as well:
- Because the index only has the hash values and pointers to rows, MySQL will always have to hit the disk to find the rows as it can't find the needed values in the index as opposed to queries on values that are covered by a
B-treeindex (more on this when we discuss covering indexes). - As we can see, the hash values are random and thus they are not sorted, so a hashed index can't be used to sort results in an
ORDER BYclause. - Hash indexes don't support partial key matching because the hash is calculated on all columns of the index, so for example, if the index has columns
AandB, the hash value is \(h(A, B)\) so we can't find rows using onlyAor onlyB, it has to use bothAandB. So in case queries that use only part of the index are important, then a new index has to be created for those columns separately. - Hash indexes can't support partial matches one column, so for example, it it's not helpful for
LIKEclauses because the hash is calculated on the full length of the value (or some part of it, but it's a fixed part anyway). - Hash indexes only support equality conditions, so only
=,IN,<=>but it can't do<or>and so on, because the values are not sorted as we mentioned before. - Accessing data in the hash index can be very quick, but in case of having an index on a column of low selectivity (very few distinct values) many collisions can occur which can cause values to be chained in a linked list. In this case when the hash key matches a linked list, all elements of the linked will have to be examined until a match is found in the worst case.
- Some index maintenance operations can also be very slow in case of having too many collisions.
All the previously mentioned limitations make hash indexes only useful for a few use cases. One of the most common use cases for hash indexes is to speed up look ups for a star schema (a schema which has one fact table that's referencing multiple dimensions tables) which is common for data warehousing applications.
It's also worth mentioning that although explicit hash indexes are only available for memory tables, but some storage engines such InnoDB construct hash indexes automatically when it detects that some parts of a B-tree index are being accessed very frequently which is called an Adaptive Hash Index. It's also easy to construct your own hash index even if you are not using memory tables as MySQL supports a variety of hash functions and TRIGGERS that can be used to perform index maintenance operations (there is a detailed example in the book for that).
Other Index Types
There are a bunch of other index types discussed in the book, such as Spatial (R-tree) indexes which can be used with spatial types like GEOMETRY, there is also full-text indexes that can help with text matching queries, etc.
To keep this article brief, I will omit discussing those types as they are not as important as the previously discussed types.
Benefits of Indexes
Now that we know the different index types and how they work, it's clear that an index can help a query execute faster by quickly finding a value or a range of values. But is this the only benefit entailed from having an index?
The answer is not quite. An index can also help:
- Reduce the amount of data that the server has to examine. Note that examining data might entail copying or having to move a lot of data around.
- Avoid sorting and temporary memory tables because the data in the index is already sorted (
B-treeindex). - Turn random disk
I/Os into sequentialI/Os because related data are stored sequentially on disk.
It's worth mentioning that having an index can also have some drawbacks mainly due to index maintenance operations because the index has to be synced when a new record is inserted, updated, deleted, etc. So for small tables, specially ones that are so small that they fit entirely in memory, having an index might slow things down. But for large tables, it's no question that the performance improvement an index brings in terms of data retrieval outweighs any maintenance overhead.
Indexing Strategies for High Performance
Creating the correct indexes and using them properly is crucial for high performance. The previous sections introduced different index types, their strengths and weakness so let's discuss how to effectively use indexes and fully tap into their power.
There are many ways to choose and use indexes effectively, because there are many special-case optimizations and specialized behaviors. The following are a set of common rules that can make this process more systematic.
Isolating the Column
MySQL can't use indexes on columns unless those columns are isolated in the query. So even if you created the correct indexes but wrote the wrong queries, MySQL might not be able to use those indexes which defeats the purpose of creating them. So what does it mean to isolate the column?
Let's take a look on the following example query:
SELECT actor_id FROM actors WHERE actor_id + 1 = 5;
And let's assume that we created an index on the actor_id column. The problem with this query is that the indexed column is not isolated, i.e. it's part of an expression or a function, so MySQL might not be able to use the index on the actor_id column. It's easy to see that this query is equivalent to:
SELECT actor_id FROM actors WHERE actor_id = 4;
And now this query isolated the indexed column so MySQL will be able to use the index on the actor_id column to serve this query.
There are many forms via which this mistake could happen, perhaps the previous example is somewhat clear and easy to spot, but let's take a look at this query:
SELECT ... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
You can probably write to this query to fetch rows that are at most 10 days old and you have an index on the date_col, but MySQL might not be able to use the index because the indexed column is part of the TO_DAYS function. But if we re-write the query to isolate the indexed column as follows, MySQL will be able to use the index.
SELECT ... WHERE date_col >= DATE_SUB(CURRENT_DATE, INTERVAL 10 days);
There is a subtlety in the new query that using an always changing value like CURRENT_DATE although we don't need the entire date, just the days, will cause this query to miss the cache all the time, so it will be better to replace the CURRENT_DATE with a fixed data, such as, 2021-03-13, this way the right hand side of the comparison will always be constant so it's more cache friendly.
Prefix Indexes and Index Selectivity
Sometimes you might need to index columns which values are very long which can make the index large and slow. We discussed how hash indexes can help with this case because a hash is usually smaller and of fixed size, but due to the many limitations of hash indexes, it might not be not enough.
In those cases we can define a prefix index, which is as the name suggests, an index on only a prefix of the column value, so for example, a prefix on the first 3 characters of the name column. This can make the index a lot smaller and very fast, but using only a prefix of the column value reduces the number of distinct values in the column and thus reduces the index selectivity. An index selectivity is the ratio between the number of distinct values in the column to the table size. The more selective an index is, the more MySQL is able to filter out results and reduce the search space. A unique index has a selectivity of 1 which is as good as it gets.
Sometimes indexing a prefix of the column is not optional, because if you are indexing columns of type TEXT or BLOB, MySQL disallows indexing the full length of the column.
So the trick here is to choose a prefix length so that it's small enough to have a small and fast index, yet not so small to have a reasonably selective index. The book shows an example of choosing a prefix length by performing some queries that calculate the index selectivity for different prefix sizes to determine which prefix is optimal.
Multi-Column Indexes
It's often the case that queries will use multiple columns in the WHERE or the ORDER BY clause which require having multi-column indexes. There are very common mistakes of indexing all columns in the same index, or indexing each column in a separate index or even indexing columns in the wrong order. All of which can cause multi column indexes to perform poorly.
Let's discuss why each of those mistakes is actually a mistake.
- Indexing all columns in the same index is bad because as we explained for
B-treeindexes, they can only serve queries on a leftmost prefix of the index columns, so having a single index will only work from prefixes and you will end up with useless columns in the index that can cause the index to be large and slow. - Indexing each column separately in an index is bad because queries often need multiple columns in the
WHEREor theORDER BYclause which in this case can't be served by using a single index. MySQL can sometimes use a strategy calledindex-mergeto make limited use of multiple indexes to serve a query but depending on this behavior is sub optimal. - Choosing the wrong columns order can limit the index use to serve some types of queries but not others. It also affects the index selectivity.
So choosing the correct column order depends on the types of queries the index is created to serve.
Clustered Indexes
There is a common misunderstanding that clustered indexes are a different type of indexes, but this is untrue, they are rather an approach to data storage that's implemented differently based on the storage engine.
When a table that has a clustered index is created, this actually means that the whole table is stored in the index leaf nodes. The name "clustered" represents the fact that related rows are stored together. All other indexes are called secondary indexes because a table can only have one clustered index.
Some storage engines let you choose the key that the clustered index will use, but some other will only use the primary key and if no primary key is designated, an auto generated primary key will be used. The following diagram shows an example of a clustered index which is quite similar to the examples showed for the B-tree index with one key difference which is that the leaf nodes in the clustered index contain the entire row (perhaps this example wasn't the best as it shows the same columns as the index we discussed earlier, but if there is another column, for example, country which is not part of any index, it will be included in the leaf node). It's very important to note that this is similar to how InnoDB implements clustered indexes, but other storage engines such as MyISAM do it differently.
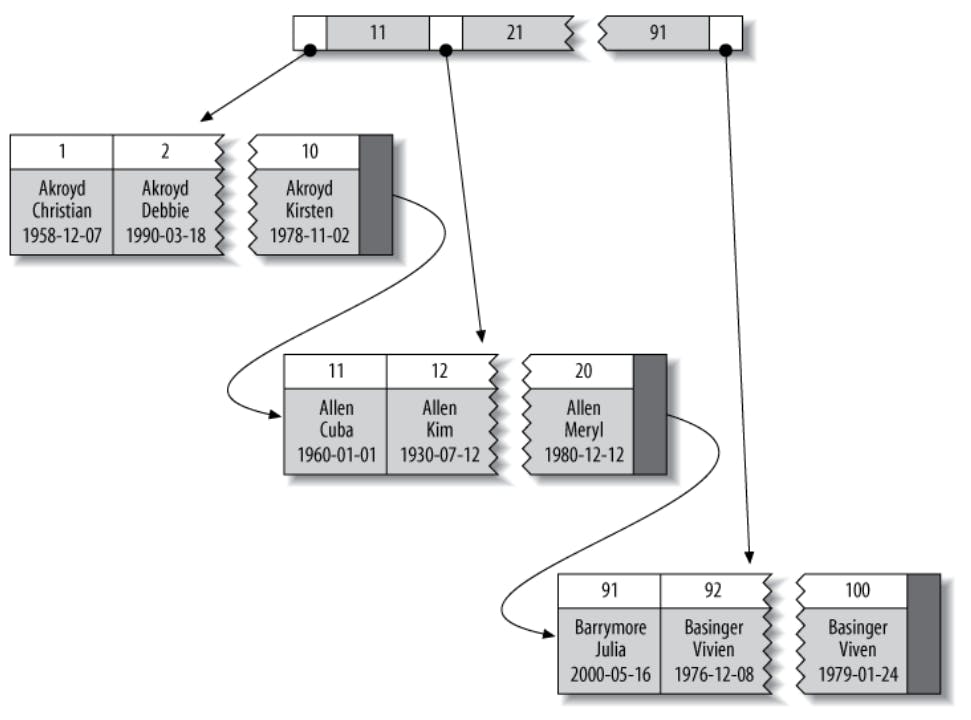
Clustering data has some advantages:
- A clustered index keeps the data close together, so for example, a
mail_boxtable, clustering byuser_idwill keep records of the sameuser_idclose together so fetching all mails for a single user will do a sequential disk read which is faster than doing randomI/Os. - A clustered index is the table as it holds all the data in the leaf node which makes a clustered index perform the same as a covering index (to be discussed later) which means that the clustered index can fetch the value of any columns (even if not the key used for clustering) directly from the index without having to fetch it from disk or via any other look ups like in secondary indexes. This makes lookups using the clustering key (usually the primary key) very fast.
Clustered indexes also have some disadvantages:
- Clustered indexes improve IO-bound workloads only so it's only helpful if the table is large that it doesn't fit in memory, otherwise, the order in which the data is fetched from memory doesn't really matter.
- Insertion speed depends greatly on the order at which data in inserted. It's always a good idea to choose the clustering key (primary key) to be a monotonically increasing
idsuch asAUTO_INCREMENTtypes because this causes all new records to be inserted in order at the end of the index which makes insertions a lot of faster than using a random key. - Updating the clustered index is quite expensive as it might force MySQL to move the row to a different location which might cause pages to split and cause fragmentation.
- Clustered tables can be slower than a full scan especially if rows are less densely packed or stored non sequentially because of page splits.
- Using a clustered index always includes the primary key in all other secondary indexes which might cause them to be larger than expected.
Although the list of disadvantages might look long and complicated but all those points are easily addressable by choosing an AUTO_INCREMENT primary key and never update it because this will:
- Avoid page splits as new records will be inserted at the end of the index.
- The index will be densely packed with no fragmentation so it will be more efficient to traverse than a full table scan.
- The primary key will be small so it won't be an issue if it's part of all other secondary indexes.
MySQL has a statement called OPTIMIZE_TABLE that can be used to optimize the clustered index layout in case you had to do PK updates, inserted a large volume of data out of order or deleted a lot of rows.
As mentioned before, the clustered index is implemented differently in MyISAM than in InnoDB because MyISAM has a separate row space so the clustered index is essentially the same as any other index because they both have physical pointers to rows in the row space. On the other hand clustered indexes in InnoDB are the table (there is no separate row space) so the leaf nodes in the clustered index contain the rows themselves while in the secondary indexes they only contain the PK + the index columns (so it requires 2 index lookups to search for a value in a secondary index). The following diagram explains this in a more visual way.
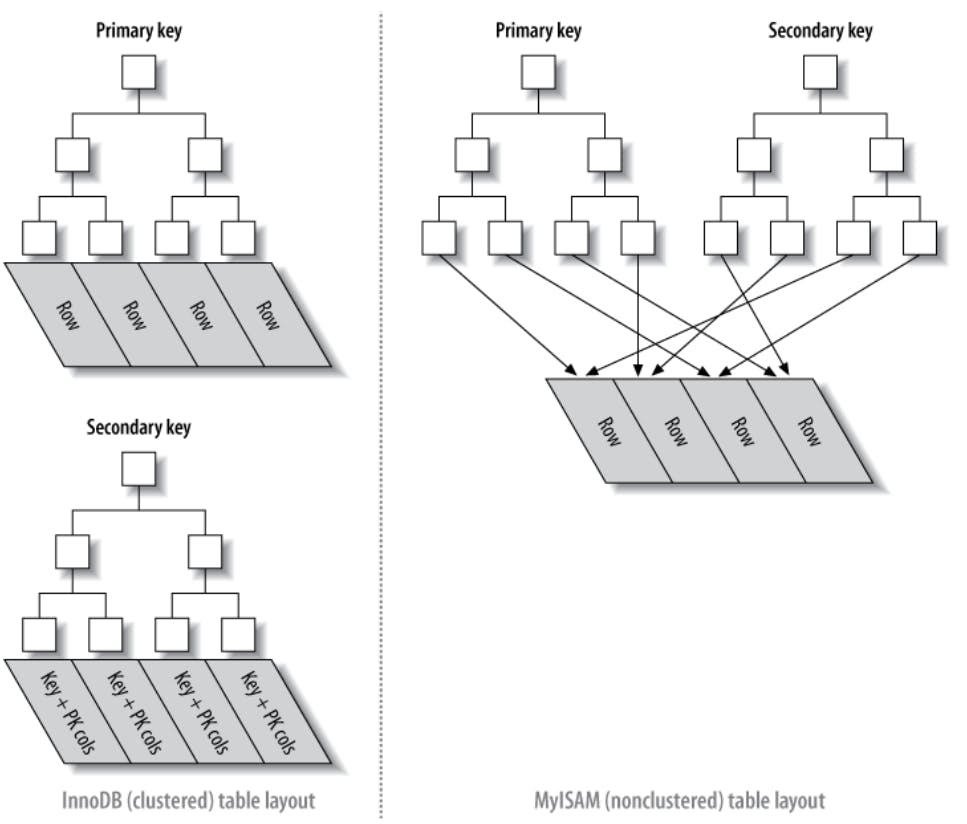
I can't stress enough on the importance of having a surrogate PK for InnoDB MySQL tables. Most elementary academic courses will probably instruct you to choose a natural column (on the columns in the table) as a primary key because "It saves space". This can't be more wrong. Let's understand this more by an example, let's consider that we have a table with 1 column called name and that name column was chosen to be the primary key instead of adding a new AUTO_INCREMENT column id to "save space", this is problematic because:
- The name column will probably have long values, at least longer than a simple integer which will not only cause the clustered index to be large, but all other secondary indexes (remember that the
PKis part of all secondary indexes in InnoDB). - Lookups using the
PKwill not be as fast as if the key was an integer, because if you remember from the last chapter, comparing strings is slower than comparing integers because it will have to consider their character sets and collation rules. This also causes joins on primary keys to be slow. - The values that the name column can take are not sequential in the sense that we might insert a record with name
value = 'D'and then insert another row withvalue = 'X'and then another row withvalue = 'S'and so on. But why is that bad? It's bad because now the storage engine will not be able to directly insert the record at the end of the index, rather it will have to find the destination page for which it will have to check previous pages that might have already been flushed to disk in which case it will have to fetch them from the disk which complicated the insertion and made it awfully slow. - Random insertions also cause page splits because let's assume that we have 2 records with names
AandCand we wish to insert a record with nameBthat will have to go in between the two rows we already have, this will force the storage engine to split the page and move theCrecord to insert theBrecord. Having this being done frequently slows down the insertion rate dramatically. - Because of 3&4 we will end up with a sparse index that can cause fragmentation which will make a full index scan slower than a normal full table scan and it causes the index to be needlessly larger than it needs to be.
- When the index is sparse, fetching data will result into random
I/Os, so retrieval will also be affected.
The moral of the story is that you should strive to insert data in primary key order when using InnoDB, and you should try to use a clustering key that will give a monotonically increasing value for each new row.
To be fair, using a monotonically increasing PK has some drawbacks as well, specially in highly concurrent systems as it creates a hot spot at the end of the index because that's where all the new data goes. This might cause lock contention and it affects the insertion rate as well. MySQL has options to control this behavior that can be found in the docs . But in most cases, you are better off with a monotonically increasing PK unless you are absolutely sure what you are doing.
Covering Indexes
There is a very common misconception that creating an index is only related to the WHERE clause of the query which causes people to create indexes that will make retrieval fast but this is not the whole story. As we mentioned before, InnoDB secondary indexes leaf nodes have the PK + the keys in the index, so if the select statement fetches columns that are not part of the index, InnoDB will use the PK to do another lookup in the clustered index to fetch the entire row. So a single query did two B-tree traversals.
But if the index was created with the SELECT statement in mind, it might have included the needed columns in the index and InnoDB would have been able to fetch the needed columns directly from the secondary index and omits the second lookup.
An index that can completely serve a query in a single lookup is called a covering index. Note that the clustered index is a covering index by default because it has the entire row in the leaf node. Also note that this discussion is somewhat specific to InnoDB because as mentioned before MyISAM indexes leaf nodes always have a pointer to the physical location of the row in the rows space and never the actual data. This is however is not as slow as the 2 lookups InnoDB does because the second MyISAM lookup is a direct disk seek to a certain location (it doesn't traverse another index). On the other hand, if a MyISAM record was updated and had to be moved to a different physical location, this will require updating the index but in InnoDB if the location changed but not the PK, no indexes will be updated, so it's a system design tradeoff.
So it's a good to create covering indexes if possible specially for queries that involves inspecting a lot of rows such as joins because doing the double lookup for all the rows can cause those queries to be slow.
Using Index Scans for Sorts
MySQL has two ways of sorting results, either by doing a sort operation (in memory or on disk) usually called a filesort even if it doesn't use a file or by traversing the index in order (because it's already sorted). It's clear that traversing the index is much faster than doing a sort operation specially for large tables, but this is only true for covering indexes that include the sort columns because otherwise MySQL will have to fetch all rows as it traverses the index which is basically random I/Os.
MySQL can also use the same index to find and sort data, so it's a good idea to design indexes to serve both purposes simultaneously.
It's important to note that ordering the results by the index works only when the index order is exactly the same as the ORDER BY clause and all columns are sorted in the same direction (ascending or descending). If the query joins multiple tables, it works only when all columns in the ORDER BY clause refer to the first table. The ORDER BY clause also has the same limitation as lookup queries as it needs to form a leftmost prefix of the index. In all other cases, MySQL uses a sort. We can determine how MySQL decided to sort the results by looking at the type column in the EXPLAIN statement and observe whether it's a (sort or using index).
Let's consider a table called rental that has the following index:
UNIQUE KEY rental_date (rental_date,inventory_id,customer_id)
Here are some queries that can use the index for sort:
WHERE rental_date = '2005-05-25' ORDER BY inventory_id DESC;(rental_date, inventory_id)form a leftmost prefix of the index.WHERE rental_date > '2005-05-25' ORDER BY rental_date, inventory_id;rental_dateoverlaps between the range condition and theORDER BYclause.
Here are some queries that can NOT use the index for sort:
WHERE rental_date = '2005-05-25' ORDER BY inventory_id DESC, customer_id ASC;WHERE rental_date = '2005-05-25' ORDER BY inventory_id, staff_id;staff_idis not part of the index.WHERE rental_date = '2005-05-25' ORDER BY customer_id;(rental_date, customer_id)doesn't form a leftmost prefix of the index.WHERE rental_date > '2005-05-25' ORDER BY inventory_id, customer_id;rental_datebutrental_dateis not in theORDER BYclause so it doesn't use the rest of the index.WHERE rental_date = '2005-05-25' AND inventory_id IN(1,2) ORDER BY customer_id;inventory_iduses anINstatement which as far as sorting concerned is a range statement and it's not included in theORDER BYclause so it doesn't use the rest of the index.
Redundant, Duplicate and Unused Indexes
MySQL doesn't automatically protect you against redundant, duplicate or unused indexes and it will maintain each all of them and consider them all while creating the execution plan or optimizing the query which will negatively affect performance. Let's first make a distinction between each type.
Redundant Indexes
Redundant Indexes are indexes that have other similar but not duplicate indexes that can do the same job, like for example, and index on (A, B) can serve queries on both (A, B) or queries on A alone (remember the leftmost prefix rule). So in case a table has both an index on (A, B) and an index on A, the index on A is considered a redundant index. This problem can also manifest in having a normal index on A and a unique index on A, in this case the normal index is redundant.
Duplicate Indexes
Duplicate Indexes are indexes that are exact duplicates of other indexes, such as an index on (A, B) and another index with a different name but also on (A, B).
Unused Indexes
Unused Indexes are neither redundant nor duplicate, they are just unused by MySQL either because other indexes are a better choice or you simply because you don't execute any queries that make use of those indexes. MySQL will still maintain those indexes however. There are many tools available to collect statistics on index usage which will allow you to spot unused indexes and delete them.
Indexes and Locking
It's easy to see that an index will reduce the number of rows that need to be examined in order to serve a query which in turns will reduce the number of rows that need to be locked during a query execution. This is only true if the storage engine can inspect values in the storage engine level but if not, MySQL sever will need to fetch those rows and lock them on the process.
Let's look at this example of executing the following query on the actors table:
SET AUTOCOMMIT=0;
BEGIN;
EXPLAIN SELECT actor_id FROM actors WHERE actor_id < 5 AND actor_id <> 1 FOR UPDATE;
Note the following:
- We disabled
auto-committo be able to emulate a transaction. - We use
SELECT FOR UPDATEin order to acquire an exclusive lock.
By inspecting the extras column in the EXPLAIN statement we can see that MySQL intends to do both (Using where; Using index) which indicates that the server decided to perform a WHERE after the storage engine returns rows from the index. What does that mean?
This means that the server told the storage engine to "begin at the start of the index and fetch all rows with actor_id < 5 but it didn't tell it about the actor_id <> 1 condition and it intends to apply that part of the WHERE on the returned rows from the storage engine. This will cause the storage engine to return the row with actor_id = 1 back to the server and then the server will filter it out. This will cause the row with actor_id = 1 to also be locked although it's not needed. We can make sure of this behavior by trying to acquire a lock on that row as follows:
SET AUTOCOMMIT=0;
BEGIN;
SELECT actor_id FROM actors WHERE actor_id = 1 FOR UPDATE;
This transaction will hang because the first transaction didn't commit yet and it's locking this row (although it doesn't really need to). Note that the locking behavior here might differ based on the isolation level.
The author mentions that some new improvements to the server-storage engine API will be added to allow the server to push WHERE conditions down to the storage engine. I am not entirely sure if that was already implemented or still planned.
Indexing Case Study
There is a very interesting case study on indexes in the book, I really recommend checking it out, however I will omit it here to keep the article short. It can be found under the Indexing Case Study section of this chapter.
References
High Performance MySQL: Optimization, Backups, and Replication
Previous Articles
Checkout previous articles in this series here: