![High Performance MySQL [Ch.4: Optimizing Schema and Data Types]](https://cdn.hashnode.com/res/hashnode/image/upload/v1618654838531/6T7J0EnWu.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


So the last 2 articles discussed chapter 2 and 3 of High Performance MySQL titled Benchmarking MySQL and Profiling Server Performance respectively. Today's article will go a bit deeper into MySQL schema design and discuss chapter 4 titled Optimizing Schema and Data Types.
Designing a good schema is essential to achieving high performance as you should consider a schema design that would perform well with the types of queries you expect to run.
Chapter 4 starts with a discussion of available data types in MySQL and how to choose the optimal data type for your use case, then it goes into a discussion of some choices when it comes to the logical design of a schema such as normalized and denormalized schema designs, then it discusses how to mix both design approaches to speed up queries by using techniques such as cache and summary tables and since no schema stays the same, the chapter ends with some advice on the use of ALTER TABLE statements.
Choosing Optimal Data Types
MySQL supports a variety of data types that we can use in our schema, but often there are subtle differences between similar types that might make it unclear which type to choose. The choice of a data type affects storage because some data types are smaller than others and it also affects query execution speed as some types work better together (we will see more about this later).
The are three rules when it comes to selecting a data type:
- Smaller is usually better: In general, you should try to use the smallest possible data type that can correctly represent your data. Smaller types take up less space on disk and in memory during execution, they also take up less CPU cycles to process and are generally faster. The problem here is sometimes you are not sure how big your data type should be and if you start with a really small data type you might end up having to change it in multiple places of the schema which could be a very cumbersome process for a high volume database. So exercise good judgement but don't go for the largest possible type to give yourself room to grow even if you are not likely to need it.
- Simple is good: Simpler types require less CPU cycles to process, like for example, it's faster to compare two integers than to compare two characters because a character is a complex type and its comparison requires knowledge of its character set and collation (sorting rules). So if you store something in a string and you can replace it with an integer, it's often a good idea to do so. A common example of this is an IPv4 address which is a 15 character string (
www.xxx.yyy.zzz), but they are actually unsigned 32-bit integers and the dotted notation is a way of making it easier to read. So we can store IPv4 addresses in 32-bit unsigned integer and use MySQL'sINET_ATON()andINET_NTOA()functions to convert between the two notations. This is more space efficient and works better if you are comparing and sorting IPs but might sound like over-engineering if you are just storing IPs as accessory data, so again good judgement. - Avoid NULL if possible: In many cases tables would contain a lot of nullable columns just because
NULLis the default without a need to represent the absence of a value withNULL. The problem with nullable columns is that they make it harder for MySQL to optimize queries that refer to those columns because they make indexes, index statistics and comparisons a lot more complicated. In some storage engines, representing aNULLeven takes up more space (an extra byte per entry) but an engine like InnoDB uses only 1 bit per entry. It's always a good practice to specify a column asNOT NULLif it doesn't really have to storeNULL, however the performance improvement entailed from such a change is not expected to be worthy, so don't spend a lot of time changing a current schema that's already riddled with nullable columns but take care while designing new ones.
Now that we know some general rules to guide our choice of a data type, the next step is to choose the general class of the data type, like for example, is it a numeric value? Is it a whole number or a real number? Is it a literal? Or is it a date? This is often an intuitive and a straightforward decision with some exceptions (like the IPv4 example we showed above).
After we settle on which general class a type falls in, we can start choosing the specific MySQL type. Many MySQL types can store the same type of data but they differ in the range of data they can store, the precision they permit and how much space they take up. Some types even have some special properties that can be useful for some use cases.
MySQL Data Types
We can classify MySQL data types into 5 categories, namely, whole numbers, real numbers, string types, data and time and bit packed types.
Whole Numbers
Are those numbers without a fractional part. If you are storing a whole number, choose one of the integer types, such as TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT. They all represent the same type of data but they vary in the range of data that can be stored. They require 8, 16, 24, 32, 64 bits to store respectively and they can store numbers in range \([-2^{(N-1)}, 2^{(N-1)} - 1]\).
Integer types can be specified to be UNSIGNED in case we don't need them to represent negative numbers which almost doubles the range of positive numbers they can store, so for example a TINYINT stores numbers in range \([-128, 127]\) but an UNSIGNED TINYINT can store numbers in range \([0, 255]\). They both use 8 bits, so choose whichever is best for your data range.
MySQL internally does integer computations using BIGINT and sometimes DECIMAL or DOUBLE to fit the type of computations that are being performed regardless of the original data type you chose. So for example, if you do a SUM aggregation, MySQL opts to use a BIGINT to calculate the SUM even if the individual values are each just a 32-bit INT to avoid overflows. You can reason that it would use DECIMAL or DOUBLE to do the same for an AVG aggregation for example.
MySQL also specify a width for integers, such as INT(11) but this is only to allow MySQL interactive tools, such as the command line tool to reserve 11 characters to display this number but it doesn't affect its actual data range or size. So for all intends and purposes, INT(20) is identical toINT(1).
It's also worth mentioning that many third party MySQL storage engines might be storing data a lot differently. Specially the ones that offer better compression.
Real Numbers
Are those numbers with a fractional part. But in many cases, you can use DECIMAL to store integers with very large values that might not fit in a 64-bit BIGINT. MySQL supports both exact and approximate math, the FLOAT and DOUBLE types do approximate math and the DECIMAL type does exact math.
Types that represent real numbers allow setting a precision which specifies the number of digits before and after the decimal point, for example, DECIMAL(18, 9) which affects the space consumption of the column, so it's advisable to think about how much precision you really need based on the needs of your application.
A FLOAT column uses 4 bytes of storage while a DOUBLE uses 8 bytes of storage but it's capable of storing wider ranges with greater precision. You also need to consider if you really need exact math or you could tolerate some imprecision as the floating point types generally take up less space than DECIMAL.
String Types
Are those types that can store literals. MySQL supports quite a few string types with some variations of each.
The two major string types are CHAR and VARCHAR which are used to store strings of either fixed or variable size as follows:
VARCHAR: Stores variable length character strings, it requires less space than fixed length types because it only uses as much space as it needs. However aVARCHARtype uses an extra 1 or 2 bytes of storage to represent the length of the string (1 byte if the maximum length is 255 and 2 bytes if it's more).VARCHARcomes with two caveats however, the first is that MySQL will still allocate fixed blocks of memory for those strings to avoid having to expand the memory allocated frequently, so aVARCHARstoring 2 characters might actually be able to store more under the hood. The second is that aVARCHARcan grow when updated which can cause extra work. If a row grows and no longer fits in its original location, some storage engines might choose to fragment the row or split the page to fit the row onto it while other engines might not be able to update the value in place at all. All things considered, it's recommended to useVARCHARwhen the maximum column length is much larger than the average column length.CHAR: Stores fixed length strings as MySQL will always allocate enough space for the specified number of characters and it also strips trailing spaces unlike aVARCHAR. TheCHARtype is suitable if you want to store very short strings or strings that will always be of the same size like anMD5hash for example. The advantages of using aCHARtype specially for very short strings is that it can actually use less space because it doesn't need to store the size information and it's not prone to fragmentation.BLOBandTEXTtype: Are designed to store large amounts of data. There are multiple variations of that type as well,TINYTEXT,SMALLTEXT,TEXT,MEDIUMTEXT,LONGTEXTand the same forBLOBtype. Those types are handled differently in terms of storage as most storage engines deal with them as objects with their own identity and store them in a different storage area. Data of those types require up to 1-4 bytes per row to store the location of the data and as much space as needed to store the data in the external storage area. They are also different in their sorting behavior as MySQL doesn't use the full length of data to sort, rather uses the firstmax_sort_lengthbytes to sort them. It's important to note that those types can't be indexed. Queries that deal withTEXTandBLOBdata types can't store temporary tables or sort files in memory, they will have to be stored on disk which is a serious performance overhead, so it's advisable to avoid using those types unless you really need to and if you use them, avoid doing queries involving the whole length of data. However, according tomysql8docs , the in-memory storage engine now supports large binary objects.ENUM: Stores values that belong to a set of predefined values. Sometimes we use string columns to store a value of something that has a finite set of values, for example, a column that represents which State a person resides in would have at most 50 values in which case using anENUMinstead of a string would be more efficient as MySQL stores them very compactly in one or two bytes depending on the carnality of the possible values set. It stores each value as an integer representing its position in the field definition list and it keeps a lookup table to convert that number into the actual value. It's worth mentioning that sortingENUMvalues might be a bit weird as it sorts the values based on their position in the field definition list regardless of what the actual values might be, so for example, if we define states to be (New York, California) New York will always sort before California in an ascending order although a lexicographical sort would yield the opposite because MySQL is sorting (0, 1) not (New York, California). It's also very important to note thatENUMvalues will always need conversion, in the sense that we will always have to check with the lookup table what the value 0 really means which introduces some overhead that can be tolerable in many cases, but in some other cases, like if we are joining anENUMcolumn with another column for typeVARCHARfor example, this could be a serious performance hit. There is a pretty good benchmark in terms of speed and storage space in the book.
Date and Time
Stores temporal data related to date and time. Unlike the rest of the types discussed before, date and time don't have that many variations so it's not really a discussion of which types is best. The finest granularity of time in MySQL is second although some third parties provide sub-second accuracy. There are two main types for working with date and time:
DATETIME: This type can hold a large range of values from the year 1001 to the year 9999 in the standardANSIformatYYYYMMDDHHMMSS. It's packed and consumes 8 bytes of storage. Nothing fancy about this type.TIMESTAMP: Conceptually, it saves the same type of data but this type is very similar to theUNIXtimestamp as it counts the number of seconds elapsed since the epoch(1970-01-01 GMT)so it can represent dates starting from the epoch up to the year 2038 (pretty soon we will all have to deal with this). The very distinctive feature aboutTIMESTAMPhowever is its ability to store time zone information as every connection can have a different timezone information. Usually, it's a good idea to save date and time information in a standard format like inDATETIMEand in case time zone logic needs to be applied it's done on the application's end.
Bit-Packed
This type allows representing boolean information in the form of a BIT or a SET of bits and allows normal bitwise operations. It might be more efficient to use this as it uses less space and it's actually internally used in MySQL, for example, to handle the Access Control List (ACL) which controls permissions.
Choosing Identifiers
The choice of the ideal data type can also be affected by whether this type will end up being used as an identifier or not. Choosing a good type for an identifier is important for high performance as the identifier column is very likely to be used for comparisons, joining, sorting, etc. When choosing an identifier, there are some general rules:
- Identifiers will be used as foreign keys that will be in turn used to perform joins, so it's recommended to choose the same type for all related tables. So for example if you used the id column in some table as a foreign key in another table make sure that it has the same type including properties like
UNSIGNED. Mixing types can cause performance problems. - When you choose an identifier you shouldn't just think about its storage type but you also need to consider how MySQL deals with it during comparisons, so for example,
ENUMandSETtypes are converted to strings during comparisons in a string context, so it doesn't make sense to use anENUMkey to join on a column of type string because this will entail a conversion overhead with every comparison. - Use the smallest possible type that can correctly represent your data, so for example, if we have a column state_id that represents which one of the 50 states, it doesn't makes sense to use a 32-bit
INTthat can store billions. This is particularly important if that column will be used as a foreign key in other tables because it will be duplicated in many rows, so even a few bytes will make a difference. It's worth mentioning tho that in this case, be sure to allow for future growth because changing the type of a foreign key can be very difficult. - Integer types are usually the best option for identifiers because they work with
AUTO_INCREMENT. - Avoid types like
ENUMandSETfor identifiers because they will always need a conversion from the lookup table. - Avoid string types because they can take up a lot of spaces and they are slower to compare and sort than integer types. There is a somewhat common use of
UUIDs as identifiers which is not the best in most cases as it can slowINSERTSbecause it causes random disk access and clustered index fragmentation. It also slowsSELECTs because related rows are not adjacent anymore so they take more work to fetch. It also causes caching to perform poorly. However, in some cases, using a random string as identifier can eliminate hot spots which might be a desirable behavior. The author recommend to remove dashes from theUUIDs and convert them to 16-byte numbers withUNHEX()and store them in aBINARY(16)columns if they are to be used.
Schema Design Gotchas in MySQL
Sometimes a bad schema is bad because it violates universally known good design principles, but sometimes it's bad because it makes MySQL specific mistakes as well. This discusses some of the schema design problems related to MySQL.
- Too many columns: MySQL's storage engine API works by copying rows between the storage engine and the server in a row buffer format that it later has to decode into column format which can be costly. Some storage engines like MyISAM match the server's format exactly so no conversions are needed but storage engines like InnoDB always need conversion. The cost of those conversions depend on the number of columns, so very wide tables (hundreds of columns) can be very costly to convert and this problem often manifests in the form of a very high CPU usage on the server. So it's not recommended to have very wide tables in MySQL specially with the InnoDB storage engine (this affects the normalization vs. denormalization decisions).
- Too many joins: There is a design pattern called Entity Attribute Value (EAV) which tries to tackle the problem of having too many columns but ends up creating too many tables that will often have to be joined to get any useful information which doesn't work well with MySQL as it enforces a maximum of 61 tables per join and even for a lot fewer than 61 tables it still performs really badly. It's always recommended to have at most a few tables per join.
- Overusing ENUM: The
ENUMdata type might seem like a really convenient way to store data with a finite set of values but it has a serious drawback that you can't add new values in the middle of the already defined field definition list without anALTER TABLEwhich can be very slow and even infeasible in many cases. - Overusing NULL: As mentioned before, having many nullable columns affects query performance. So it's recommended to be avoided if possible even if a value has to stay empty, then maybe use a different default value like zero or something. But also don't be over cautious to use
NULL, it's often better than having weird magical values to represent the non-existence of data.
Normalization Vs. Denormalization
There are many ways to represent data that range from full normalized to fully denormalized and anything in between. A fully normalized schema is when every piece of data is represented only once, conversely, a denormalized schema is when data is duplicated as much as needed and stored in different places.
To better discuss the pros and cons of each and what could be a good middle ground, let's take a quick example. The following is a database that uses a single table to represent employee, department and department heads data:
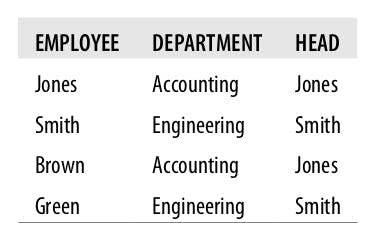
It's obvious that if we wish to know who is Brown's boss, we could just query this table for the employee named Brown and get the value of the Head column. On the other hand, if the accounting head changed from Jones to Smith, we will have to update all records that have the value Accounting in the Department column.
This table can be converted to the second normal form (2NF) as follows. Now we have 2 tables, one for employees and the other for departments.

If we want to know who is Brown's boss in the new schema, we will have to check which department Brown works for from the employees table and then fetch the head of that department from the departments table, effectively joining the two tables on the department foreign key. But if Smith takes over as head of accounting, we will only update one record in the departments table.
It's worth mentioning that there are other normal forms that can be derived here. If you need to brush up your knowledge on normal forms, refer to this article .
At this point we already have a good idea of what are the pros and cons of normalized and denormalized schemas, but let's go into a more detailed discussion.
Pros and Cons of Normalized Schema
- Normalized updates are usually faster because there is only one source of data.
- Well normalized schemas have no or very few duplicates so it's more space efficient.
- Normalized tables have fewer columns and they are usually smaller which makes them fit better in memory and thus be faster when it comes to querying single tables.
- The lack of duplicates eliminates the need to use statements like
DISTINCTorGROUP BYwhich can be expensive. Like for example, in the denormalized schema, if we want a list of departments, we will have to selectDISTINCTbut in the normalized schema we can justSELECTfrom the departments table. - In a normalized schema we don't lose an entity by deleting a record. Like for example, in the denormalized schema, if only a single employee works for a department and that employee was deleted, we will lose all information about that department even if it still exists unlike the normalized schema, we can delete the employee record and not the department record.
- The major drawback is any non-trivial query on a normalized schema will have at least 1 join and it could be more if the schema is fully normalized which can incur a cost on retrieval.
Pros and Cons of Denormalized Schema
- If all the needed data resides in the same table, no need to perform any joins which makes retrieval a lot faster.
Denormalization and Efficient Indexing Strategies
Having all data in the same table allows for more efficient indexing strategies. For example, if you have a forum app where users post messages and users can be standard or premium. If you want to fetch the most recent 10 messages from premium users only, on a normalized schema, the query will look like:
SELECT message_text, user_name
FROM message
INNER JOIN user ON message.user_id=user.id
WHERE user.account_type='premiumv'
ORDER BY message.published DESC LIMIT 10;
For MySQL to execute this query, it will have to scan the published index in order and for each entry, it needs to check with the users table if this message is from a premium user or not.This is inefficient if only a small portion of users are premium.
Another query plan would be to scan the users the table for premium users, get all their messages and then sort the fetched messages in which case it didn't use the index on the published column and instead it will do a file sort which will be even worse than the first query plan.
On the other hand, if the schema was denormalized and we had a combined table with columns (message_text, user_name, account_type, published) we could make a compound index on both (account_type, published) and write a query without a join as follows:
SELECT message_text,user_name
FROM user_messages
WHERE account_type='premium'
ORDER BY published DESC
LIMIT 10;
This will allow MySQL to use the (account_type, published) compound index to efficiently serve this query.
The Best of Both Worlds
As we might already have deduced from the previous discussion that neither approaches is solely best, so it makes sense to try to mix both approaches. The most common way of denormalizing a schema in MySQL is via duplication or caching the selected columns from one table to another. MySQL offers TRIGGERS that can be used to update the duplicate values if they changed in one table which makes the implementation easier.
So for instance, in the previous example instead of fully denormalizing the schema into a single table, we could have just duplicated the account_type column in both the users and messages tables to serve the same purpose. This makes sense if the account_type doesn't change often because now if it changed in the users table, we will have to update it in the messages table which is a somewhat large fan-out (1 user can have a million messages). But in this particular case, I think that this is a reasonable approach since most of the load will be SELECT queries like messages by a user_name and so on while changing the account_type will be a somewhat rare event.
Cache and Summary Tables
In the previous example we discussed duplicating data in the same tables used for other stuff, but sometimes you might want to create completely separate tables for that and tune them for retrieval needs. This is particularly useful if you can tolerate stale data (the new table will take some time to be synced with any changes in the original tables).
A cache table is a table containing data that can be generated from other tables in the schema, so for example, we can leave the users and messages tables as is and create a new cache table named message_users that does the denormalization we talked about. However, we will have to sync this new table with any changes that happen in the users and messages tables.
A summary table is a table containing aggregated data from GROUP BY queries. So for example, if we want to fetch the count of messages for every user and we expect to perform this query quite often which will be expensive in the normalized schema, we could generate a messages count table every \(x\) mins and always look up that table if we can tolerate some delay.
There are some other options as well like using Materialized Views and Counter Tables which the book mentions that they will be discussed in more details in chapter 7.
Nothing is Ever Final
Even after a very thorough consideration of what types to use and what schema to go to production with, it will often be the case the the schema will change over time. You will need to add new columns, drop old ones, make new tables, change columns types, etc. So it's essential to know how costly certain operations are.
This section particularly considers ALTER TABLE which MySQL sometimes can perform online, but sometimes it will be a blocking operation, refer to the official docs for more details. ALTER TABLE can take days or even be infeasible in some cases if the table is very large. So try as much as possible to avoid having to use it.
ALTER TABLE is internally implemented in MySQL by creating a new table with the needed changes, copying the data from the old table into the new table, switching tables and then dropping the old table. This could be very difficult for large tables with many indexes because at some point, it will use twice as much storage on the server.
For the general case, you need to use either operational tricks such as swapping servers around and performing the ALTER on servers that are not in production service, or a shadow copy approach. The technique for a shadow copy is to build a new table with the desired structure beside the existing one, and then perform a rename and drop to swap the two.
There are a bunch of third party tools that make this a bit easier but from a personal experience, this is always a cumbersome process that I wish I can always avoid.
References
High Performance MySQL: Optimization, Backups, and Replication
Previous Articles
Checkout previous articles in this series here: