
Designing Data Intensive Applications: Ch5. Replication (Part 4: Leaderless Replication)


In the previous article, we discussed multi-leader replication and some of its usecases such as replication over multiple datacenters, offline client applications and collaborative editing applications. We have also discussed the complications that arise from having multiple leader replicas in the replicated system, mainly, due to write conflicts and went over some of the methods used to resolve write conflicts such as synchronous conflict resolution, conflict avoidance, convergent and custom conflict resolution and some approaches for automatic conflict resolution such as conflict-free replicated datatypes (CRDTs) (2-way merge), mergeable persistent data structure (3-way merge) and operational transformation.
All approaches we have discussed so far depend on the idea of having some replica(s) designated as leader(s) to which all writes would go but some data storage systems take a different approach, abandoning the concept of a leader and allowing any replica to directly accept writes from clients. Some of the earliest replicated data systems were leaderless, like for example Dynamo and many other data storage systems inspired by Dynamo, like Riak, Cassandra, Voldemort, etc. Being leaderless, however, has profound consequences for the way the database is used as we shall see.
In this article, we will discuss leaderless replication and go over some of the main differences in design, for instance, how leaderless replicated databases use quorums to achieve eventual consistency, how they use read-repair and anti-entropy processes to reduce staleness, then we will discuss some of the limitations of quorum consistency and some variations like sloppy quorums and hinted handoff.
Writing to the Database When a Node Is Down
In leader-replication architectures, if the system has, for example, 3 replicas and one of them is designated as leader where all the write requests from the client would go. If that leader node goes down for any reason, a failover can be performed where one of the 2 remaining operating nodes can be promoted as leader and it starts accepting write requests and normal operation would proceed til the down replica comes back online and rejoins the system.
On the other hand, in a leaderless system, a client would send write requests to all 3 replicas in the system at the same time (in some systems, the client would send the write request to a coordinator and the coordinator would take care of sending the write requests to all replicas instead), so if a replica is down, the write request will go to 2 replicas. Let's assume that it's enough that 2 out of 3 replicas acknowledge a write to consider it successful.
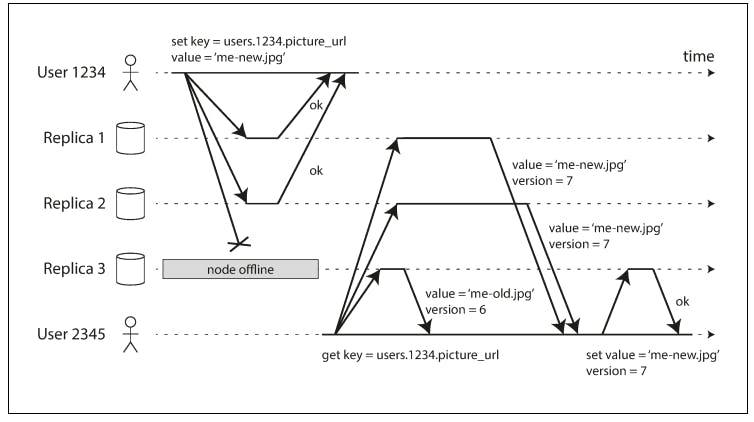
As in the previous diagram, user1234 sends a write request to replica 1 and 2 and 3, it gets acknowledged by replicas 1 and 2, but replica 3 is down and because 2 out of 3 acknowledgments for this system is enough, we consider this write persisted.
Now when replica 3 comes back online and the client attempts to read data, if the read request was directed to either replicas 1 or 2, it will be able to retrieve the write that was just written, but if the read request was directed to replica 3, it will not. That's why read requests will also be directed to all 3 replicas and at least some replicas will have to agree on a value.
That solves the problem for now, but the replication scheme should ensure that eventually all the data is copied to every replica. After an unavailable node comes back online, how does it catch up on the writes that it missed?
There are two mechanisms that are often used in Dynamo-style datastores:
Read repair
When a client makes a read from several nodes in parallel, it can detect any stale responses. For example, in the previous diagram, user2345 gets a version 6 value from replica 3 and a version 7 value from replicas 1 and 2. The client sees that replica 3 has a stale value and writes the newer value back to that replica. This approach is usually referred to as lazy propagation in the sense that the new value (the fix in this case) gets lazily propagated only when the stale value is read, which makes this approach good for values that are read frequently. This causes values that are not read frequently to have lower durability because they will keep being missing from some replicas.
Anti-entropy process
As opposed to the lazy approach, some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another.
Quorum Consistency
What we just discussed in the previous section is called Quorum Consistency in distributed systems.
One approach to tolerate failures in replicated systems is the use of quorum-based consensus protocols. This means that if a system has \(V\) replicas, each decision (write or read) will have to obtain a quorum in order to be acknowledged, i.e. read operations have to obtain a quorum of \(V_r\) votes and write operations have to obtain a quorum of \(V_w\) votes.
To achieve consistency in a replicated environment, the quorums must obey 2 rules:
Each read must be aware of the most recent write, in other words, the set of nodes used for read has to intersect with the set of nodes used for write which can be expressed as \(V_r + V_w > V\). This ensures that the read quorum contains at least 1 node with the newest version of the data.
Each write must be aware of the most recent write to avoid conflicting writes. This can be expressed as \(V_w > V/2\).
So for example, if \(V = 3, V_r = 2, V_w = 2\), this will stratify both conditions (\(V_r + V_w > V, V_w > V/2\)). Let's see why would this work:
Read: When data is read, it will be read from 2 nodes and because data is written to 2 nodes, if we had 2 operations (write then read), the write operation wrote data to \(node_1, node_2\) and the read operation can either read data from \(node_1, node_2\) or from \(node_1, node_3\) or from \(node_2, node_3\), we know for sure that one node has to be repeated in the read and write sets which guarantees that a read after a write will be able to read the previously written data.
Write: When data is written, it will be written to 2 nodes. So let's assume that we have 2 write operations, the first wrote data to \(node_1, node_2\) and the second wrote data to \(node_1, node_3\), we know for sure that the 2 write operations will overlap in at least 1 node which means that the second write will be aware of the first write via the repeated node (the node that was part of both write operations) which guarantees that no conflicting writes will occur (write conflicts will be detected and resolved).
This is actually quite similar to how Amazon Aurora operates (although Aurora is a leader-based replicated system). You can read more about Aurora in this series.
Limitations of Quorum Consistency
As discussed in the previous section, the values \(V_r\) and \(V_w\) can be set in so many different configurations which allows for greater flexibility. Som obvious considerations however are:
If \(V_r\) or \(V_w\) are too large, that will cause latencies. Usually, we would go with a larger \(V_w \) and smaller \(V_r\) if the system is read-heavy but it's acceptable to have some latencies in writes. Or the opposite for different types of systems.
If we choose \(V_r\) and \(V_w\) to be very large and include most nodes in the system, the system's availability will be heavily affected because it will be very hard to assemble a quorum when a few nodes are unavailable.
If we choose \(V_r\) and \(V_w\) to be very small, we are more likely to read stale values because it’s more likely that your read set didn’t include the node with the latest value.
However, even with \(V_w + V_r > V\), there are likely to be edge cases where stale values are returned. These depend on the implementation, but possible scenarios include:
If a sloppy quorum is used (we will go over sloppy quorums in the upcoming section), the \(V_w\) writes may end up on different nodes than the \(V_r\) reads, so there is no longer a guaranteed overlap between the \(V_r\) nodes and the \(V_w\) nodes.
If two writes occur concurrently, it is not clear which one happened first. In this case, the only safe solution is to merge the concurrent writes. If a winner is picked based on a timestamp (last write wins), writes can be lost due to clock skew (some systems get over clock-skew in very clever ways like Google Spanner TrueTime API)
If a write happens concurrently with a read, the write may be reflected on only some of the replicas. In this case, it’s undetermined whether the read returns the old or the new value.
If a write succeeded on some replicas but failed on others (for example because the disks on some nodes are full), and overall succeeded on fewer than \(V_w\) replicas, it is not rolled back on the replicas where it succeeded. This means that if a write was reported as failed, subsequent reads may or may not return the value from that write.
If a node carrying a new value fails, and its data is restored from a replica carrying an old value, the number of replicas storing the new value may fall below \(V_w\), breaking the quorum condition.
All things considered, although quorums appear to guarantee that a read returns the latest written value, in practice, it is not so simple. Those types of databases are usually optimized for workloads that can tolerate eventual consistency and it’s wise to not take them as absolute guarantees.
Monitoring staleness
From an operational perspective, it’s important to monitor whether your databases are returning up-to-date results. Even if the application can tolerate eventual consistency, it's always a good practice to be able on top of things happening in your application so that if the system has been stale for a significant amount of time, it can alert you so that you would investigate the causes.
In leader-based replication, this monitoring is quite easy because all writes go to a designated set of leader(s) and they get applied to replica nodes in order. So each replica has a position in the replication log and by subtracting that position from the length of the replication log, each replica can know how latent it is and replication lag can be reported and monitored easily.
In leaderless systems, however, this is quite hard because writes are not applied to the replicas in any specific order. Also, if the system is using a read-repair method only without any anti-entropy processes, there is no upper bound on how stale the system can be since some values might not be read at all or be read very infrequently.
There has been some research on measuring replica staleness in databases with leaderless replication and predicting the expected percentage of stale reads depending on the parameters \(V\), \(V_w\), and \(V_r\). This is unfortunately not yet common practice, but it would be good to include staleness measurements in the standard set of metrics for databases. Eventual consistency is a deliberately vague guarantee, but for operability, it’s important to be able to quantify “eventual”.
Sloppy Quorums and Hinted Handoff
Databases with appropriately configured quorums can tolerate the failure of individual nodes without the need for failover. They can also tolerate individual nodes going slow, because requests don’t have to wait for all n nodes to respond—they can return when \(V_w\) or \(V_r\) nodes have responded. These characteristics make databases with leaderless replication appealing for use cases that require high availability and low latency, and that can tolerate occasional stale reads.
However, quorums are not as fault tolerant as you might think. Consider the case where the system has \(N\) nodes, where \(N >> V\) which means that the number of total nodes in the system is much larger than the set home nodes (those nodes that represent write and read quorums). In those cases, a network partition might end up separating the client from a large portion of the database nodes (nodes will still be alive but inaccessible to the client due to a network fault), causing the client to not be able to assemble a quorum. When this happens, there are 2 options that database designers will have to choose from:
Return errors to all requests for which we cannot reach a quorum of \(V_w\) or \(V_r\)nodes.
Accept writes anyway, and temporarily write them to some nodes that are reachable but aren’t among the \(V\) nodes on which the value usually lives.
The second approach is called a Sloppy Quorum where writes and reads still require \(V_w\) and \(V_r\) successful responses, but those may include nodes that are not among the designated \(V\) “home” nodes for a value. By analogy, if you get locked out of your home, you knock on your neighbor's door and ask them to stay there temporarily until you can recover a key to your home.
Once the network interruption is resolved, any writes that were temporarily accepted by some nodes that don't belong to the \(V\) home nodes are sent to the home nodes. This is called Hinted Handoff, using the same analogy, once you recover a key to your house, you will leave your neighbor's house and go live in your house.
Sloppy quorums are particularly useful for increasing write availability: as long as any \(V_w\) nodes are available, the database can accept writes. However, this means that even when \(V_w + V_r > V\), you cannot be sure to read the latest value for a key, because the latest value may have been temporarily written to some nodes outside of \(V\). This makes sloppy quorums not really a quorum in the traditional sense, but more of a durability guarantee (a value will be written to \(V_w\) nodes anyway).
Summary
In this article, we have discussed leaderless replication and went over some of the main differences in design, for instance, how leaderless replicated databases use quorums to achieve eventual consistency, how they use read-repair and anti-entropy processes to reduce staleness, then we discussed some of the limitations of quorum consistency and some variations like sloppy quorums and hinted handoff.