


In a previous article, I have talked about partitioned databases and the problem of distributed transactions. The previous article discussed a transaction scheduling and data replication layer called Calvin which presented new ideas to approach the problem of distributed transactions but had a lot of limitations and a few things that didn't seem practical in a production environment.
In this article, I will discuss a partitioned database called Spanner which is Google’s scalable, multi-version, globally distributed and synchronously-replicated database which tries to solve the same problems Calvin tried to solve but in a more robust and practical manner (note that spanner is heavily used within the google infrastructure and it's also available via GCP to cloud customers), so it's very mature and battle tested.
Spanner is the first system to distribute data at global scale and support externally consistent distributed transactions. This article describes how Spanner is structured, its feature set, the rationale underlying various design decisions. It also discusses the innovative idea of exposing clock uncertainty which is basis upon which supporting external consistency is built.
So what is Spanner? What does it mean to be externally consistent? And what is clock uncertainty? Let's take a deep dive into the internals of Spanner to answer those questions.
So What Exactly is Spanner?
Spanner is a scalable, globally-distributed database designed, built, and deployed at Google. At the highest level of abstraction, it is a database that shards data across many sets of Paxos state machines (more on this later, but it means a group of machines that reach consensus through the Paxos algorithm) in datacenters spread all over the world.
Replication is used for global availability and geographic locality as clients automatically failover between replicas. Spanner automatically reshards data across machines as the amount of data or the number of servers changes, and it automatically migrates data across machines (even across datacenters) to balance load and in response to failures.
Spanner is designed to scale up to millions of machines across hundreds of datacenters and trillions of database rows!
What is external consistency?
This term will be used a lot throughout the article to describe the way Spanner supports distributed transactions at global scale so let's take a look at what does it mean.
For a group of transactions to be externally consistent, it means that although transactions are concurrent and distributed, they would appear to be executed at the same global order they were initiated at with respect to some time reference. For example, if we have 2 transactions \(T_1\) and \(T_2\) and \(T_1\) commits before \(T_2\) starts, then this means that \(T_1\) commit timestamp must be smaller than \(T_2\)'s.
One may try to compare external consistency with serializability, but the main difference here is that strict serializability imposes no order on concurrent transactions, whereas external consistency imposes a global order on all transactions and thus external consistency is a stronger guarantee than strict serializability, i.e. any externally consistent system is also strictly serializable.
It's worth mentioning that Spanner is the first database to provide such guarantees at global scale.
Spanner feature set
Spanner’s main focus is managing cross-datacenter replicated data and providing a powerful feature set that works on top of the distributed infrastructure. Google already had similar databases that were in use before Spanner, such as Bigtable and Megastore but both had their drawbacks that Spanner tried to overcome, for example:
- Bigtable can be difficult to use for some kinds of applications: those that have complex, evolving schemas or those that want strong consistency in the presence of wide-area replication.
- Megastore on other hands solves some of Bigtable's problems because it offers a semi-relational data model and support for synchronous replication (strongly consistent), but all that came at a cost of very poor throughput compared to Bigtable.
And so, as a consequence, Spanner evolved as a temporal multi-version database, which means that data stored in the database is versioned and each version is automatically timestamped with its commit time; old versions of data are subject to configurable garbage-collection policies; and applications can read data at old timestamps (which is really helpful for snapshot ioslation). So you can think of it as a key-value store but instead if storing \(\langle key , value \rangle\) it stores \(\langle \langle key, timestamp \rangle, value \rangle\), so the same key can have different values for different timestamps and thus the "temporally versioned" property.
Spanner supports some really useful features such as:
- The replication configurations for data can be dynamically controlled at a fine grain by applications (as opposed to a static configuration for all Spanner users).
- Applications can specify constraints to control which datacenters contain which data, how far data is from its users (to control read latency), how far replicas are from each other (to control write latency) and how many replicas are maintained (to control durability, availability, and read performance).
- Data can also be dynamically and transparently moved between datacenters by the system to balance resource usage across datacenters.
- Support for externally consistent reads and writes (externally consistent mean, that although transactions are distributed, they would appear to be executed at the same order they were initiated at with respect to some time reference).
- Globally-consistent reads across the database at a timestamp.
- Consistent backups, consistent MapReduce executions and atomic schema updates, all at global scale, and even in the presence of ongoing transactions.
- A SQL like query language.
Design and Implementation
In this section we discuss the internal design of Spanner and some of the implementation details and the rationale behind them. Let's first take a look at how a Spanner deployment looks like at a high level.
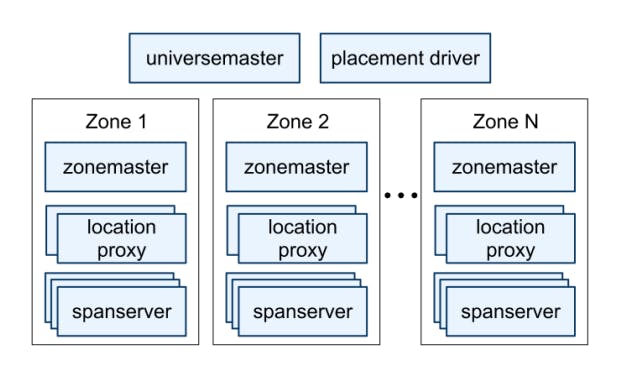
As we can see in the previous diagram, a Spanner deployment is called a universe, each universe represents a global Spanner deployment, so there are can only be a few running universes, currently Spanner supports a test/playground universe, a development/production universe and a production-only universe.
- A universe is comprised from a set of zones, a zone is the administrative deployment. The set of zones is also the set of locations across which data can be replicated. Zones can be added to or removed from a running system as new datacenters are brought into service and old ones are turned off, respectively. Zones are also the unit of physical isolation: there may be one or more zones in a datacenter, for example, if different applications’ data must be partitioned across different sets of servers in the same datacenter.
- A zone is comprised from a single zone master and between one hundred and several thousand spanservers. The zonemaster assigns data to spanservers which in turn store and serve data to clients.
- Each zone has a location proxy which is used by clients to locate the spanservers assigned to serve their data.
- Each Spanner universe also has a single universe master which is mainly a dashboard to monitor the Spanner universe.
- Each Spanner universe also has a single placement driver that handles automated movement of data across zones on the timescale of minutes. The placement driver periodically communicates with the spanservers to find data that needs to be moved, either to meet updated replication constraints or to balance load.
What is a Paxos State Machine?
Paxos is a protocol for state machine replication in an asynchronous environment that tolerates failures. A Replicated State Machine (RSM) is basically a group of machines (replicas) running in parallel and maintaining their state in sync, so for example, when one replica receives a write request, it persists it (to itself only or to a number of replicas) and responds back the client with success, then it proceed to replicate the same write to the remaining replicas in an effort to keep them all in sync.
It is easy for replicas to execute client commands in the same order and remain in sync if there is only one client or if multiple clients send their requests strictly sequentially as shown below:
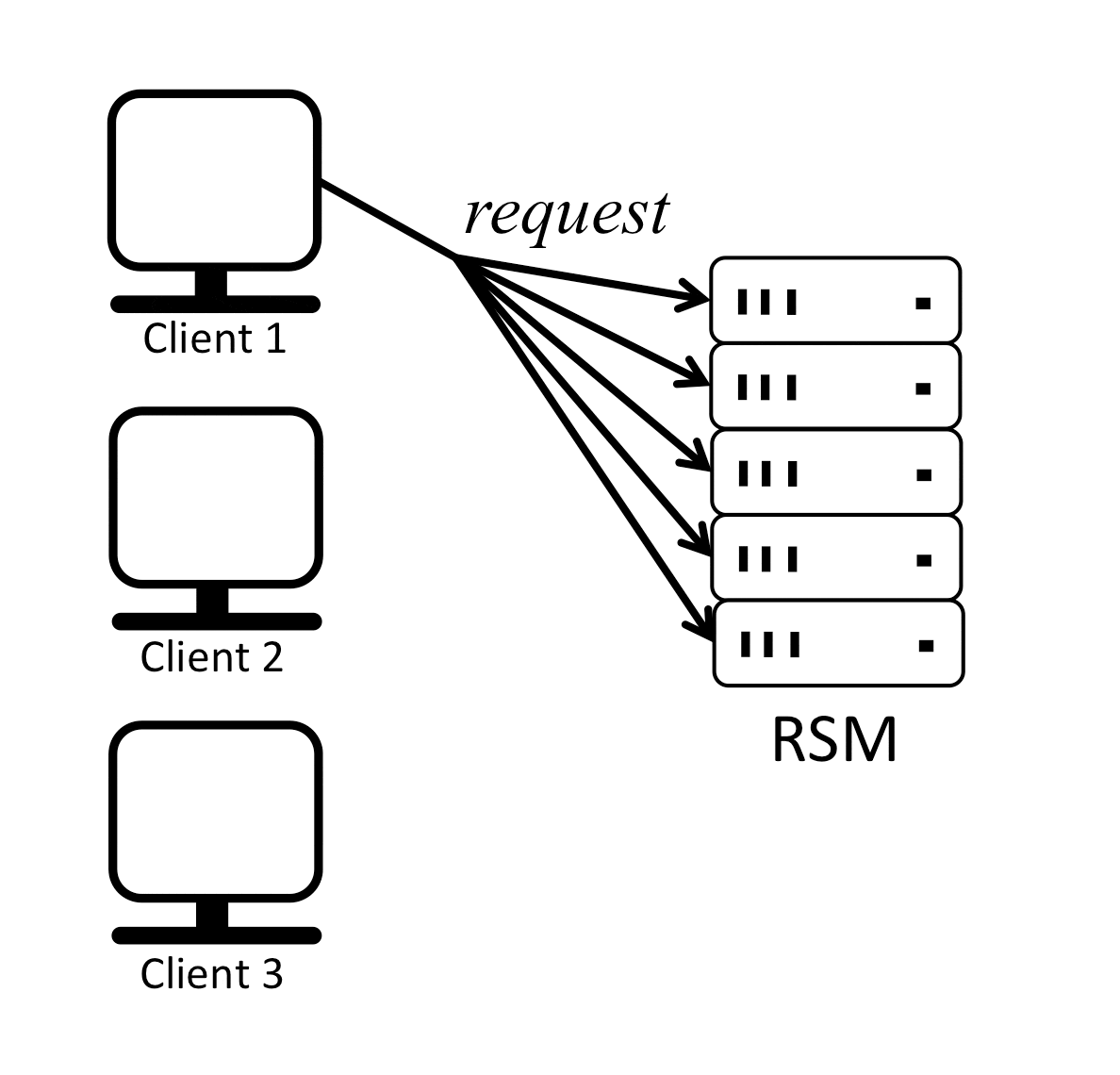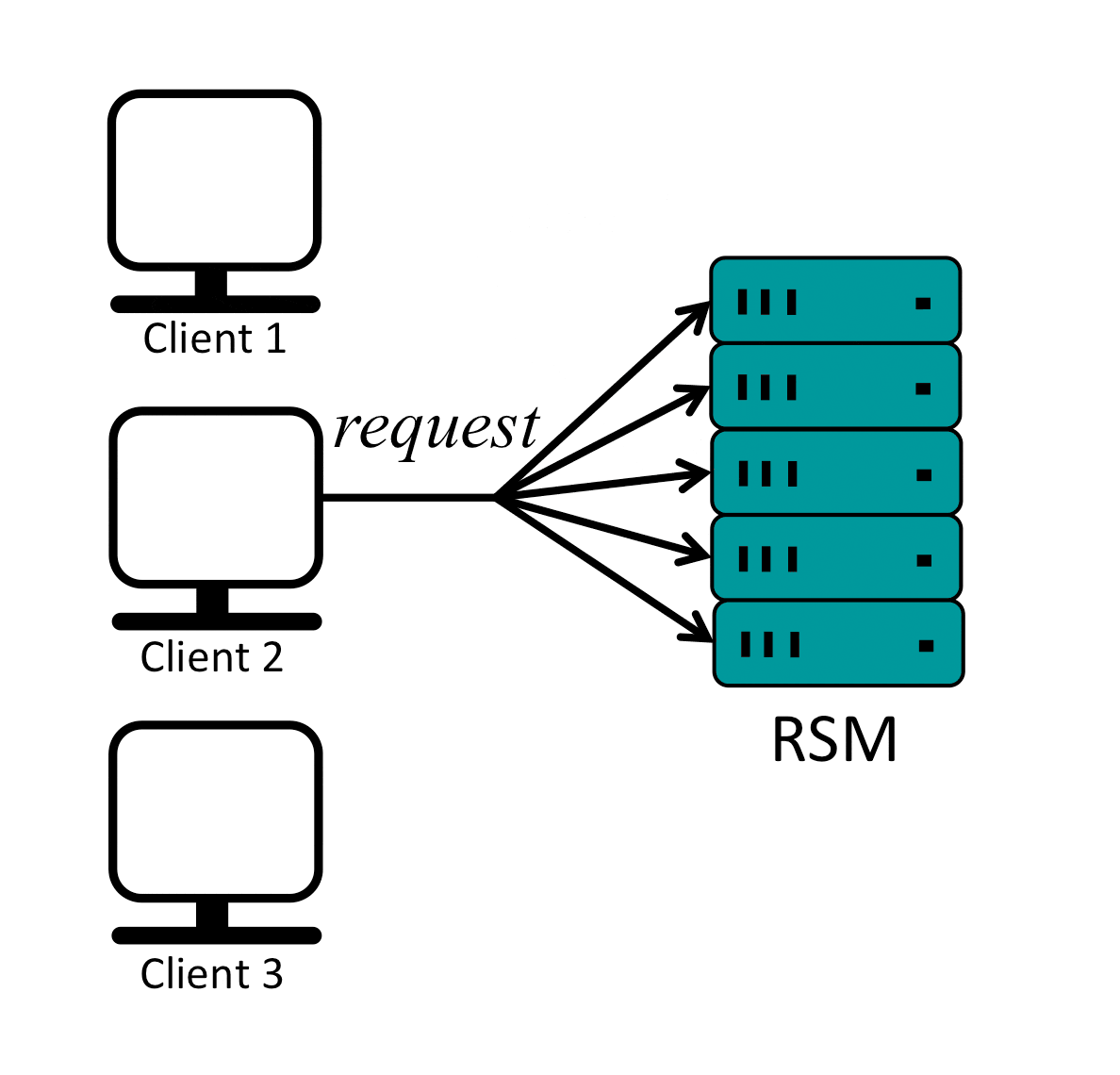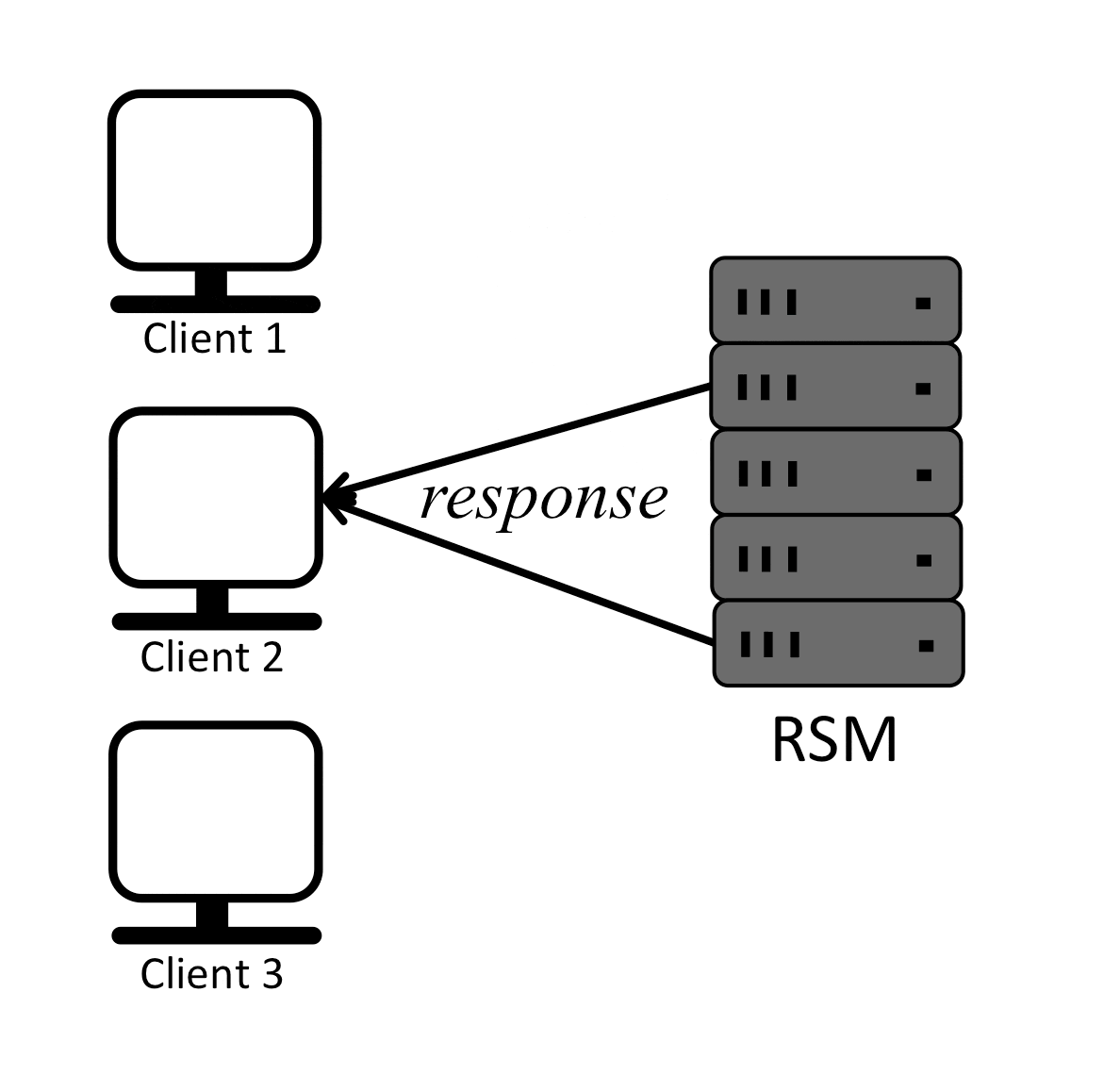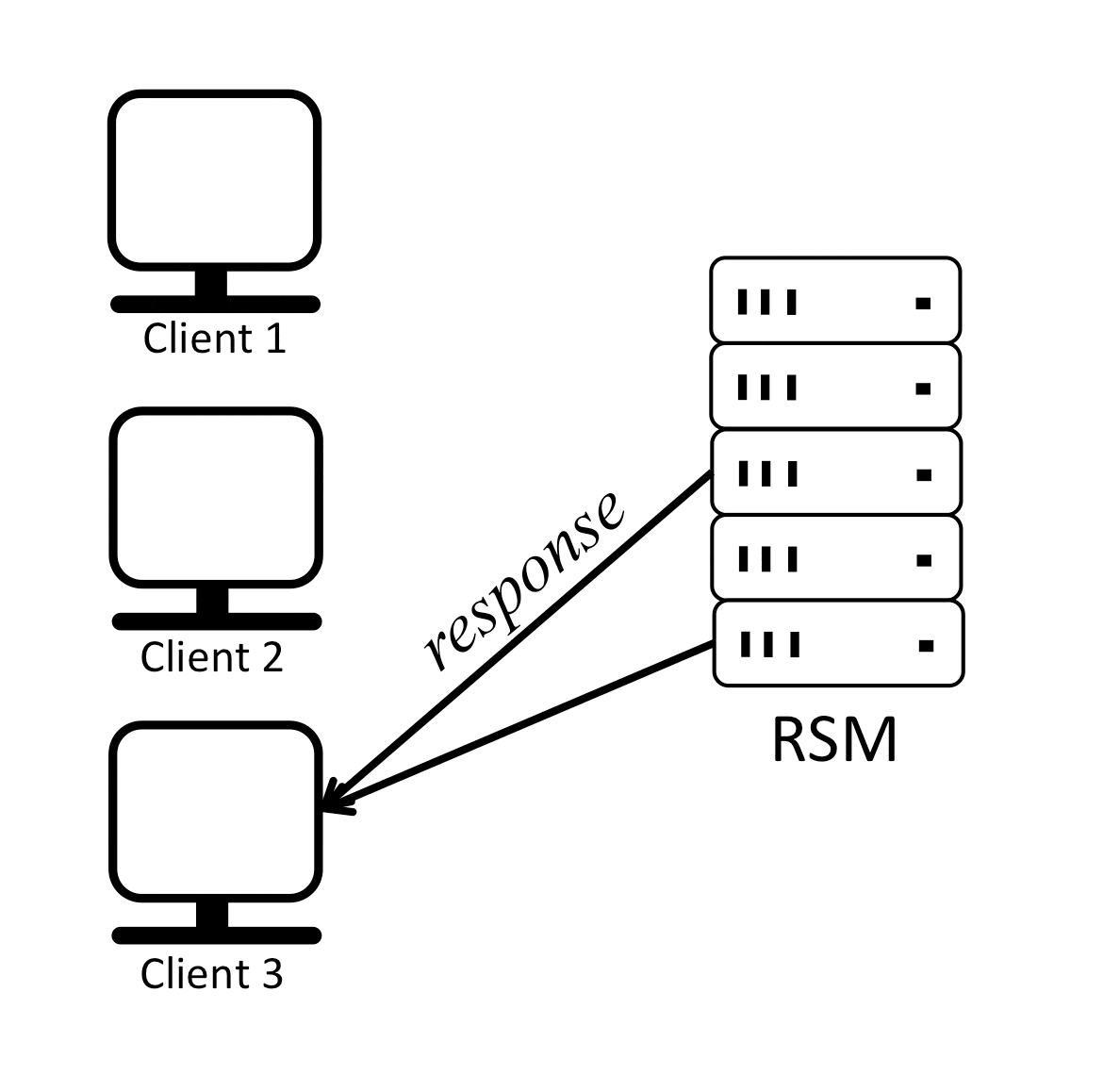
In the previous example replicas receive requests from clients in a serial order, execute the commands in the same order and respond to the clients, in effect staying in sync.
But if multiple clients send requests to replicas in parallel, then different replicas might receive these requests in different orders and execute the commands in different orders, causing their local states to diverge from one another over time. To prevent this divergence a certain order of execution has to be reached so that all replicas process all requests in the same serial order and stay in sync. So for example, consider the following example:
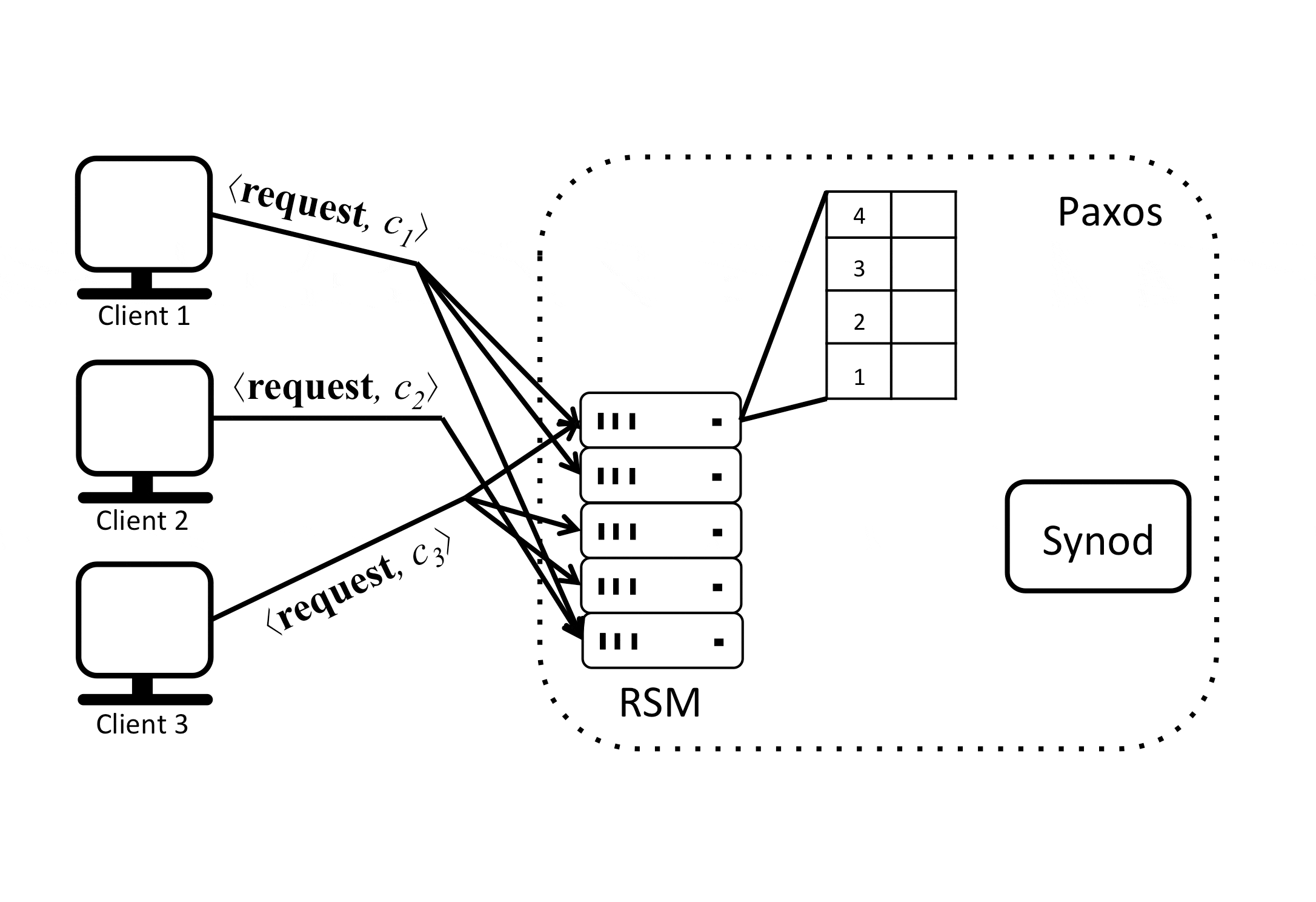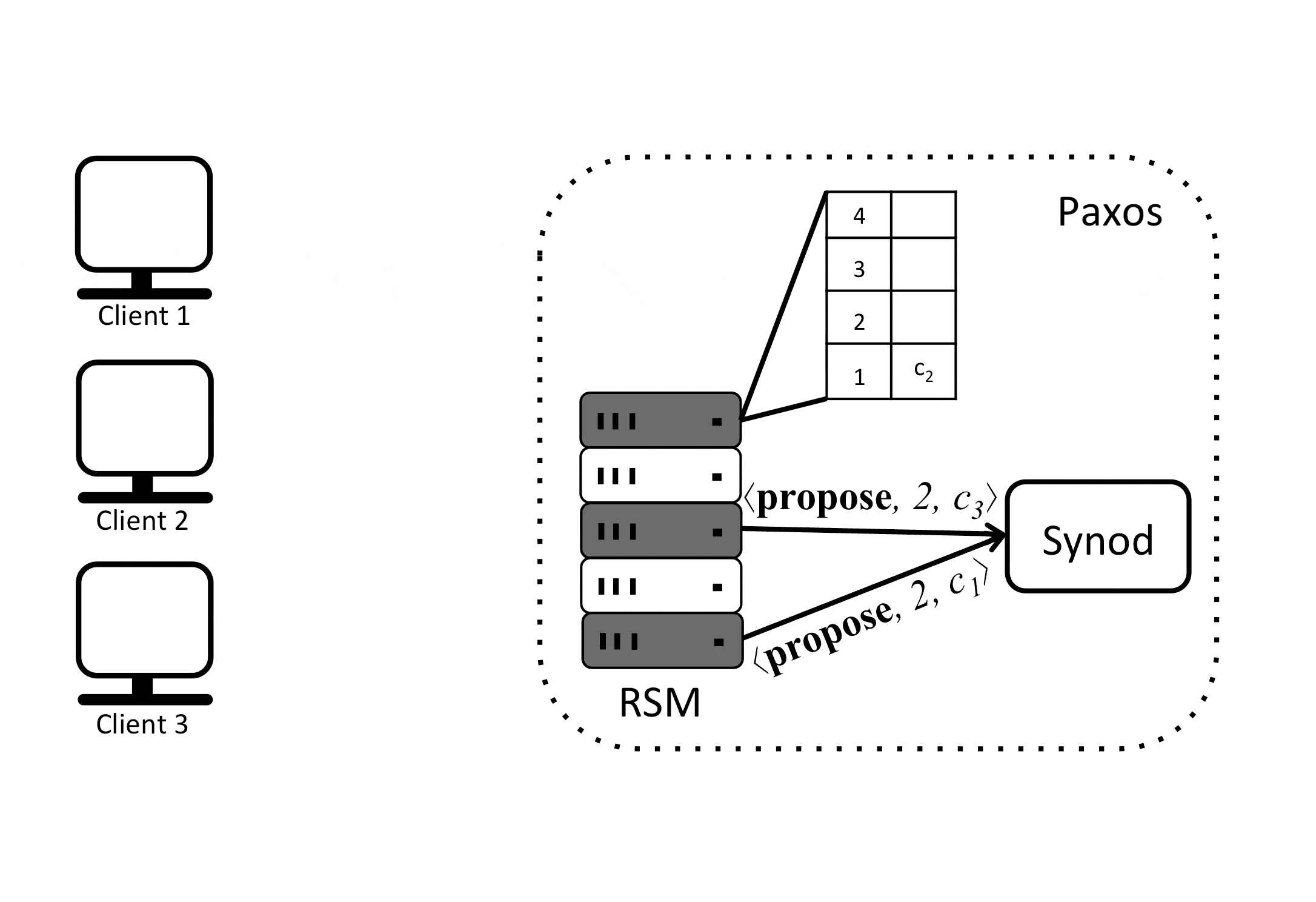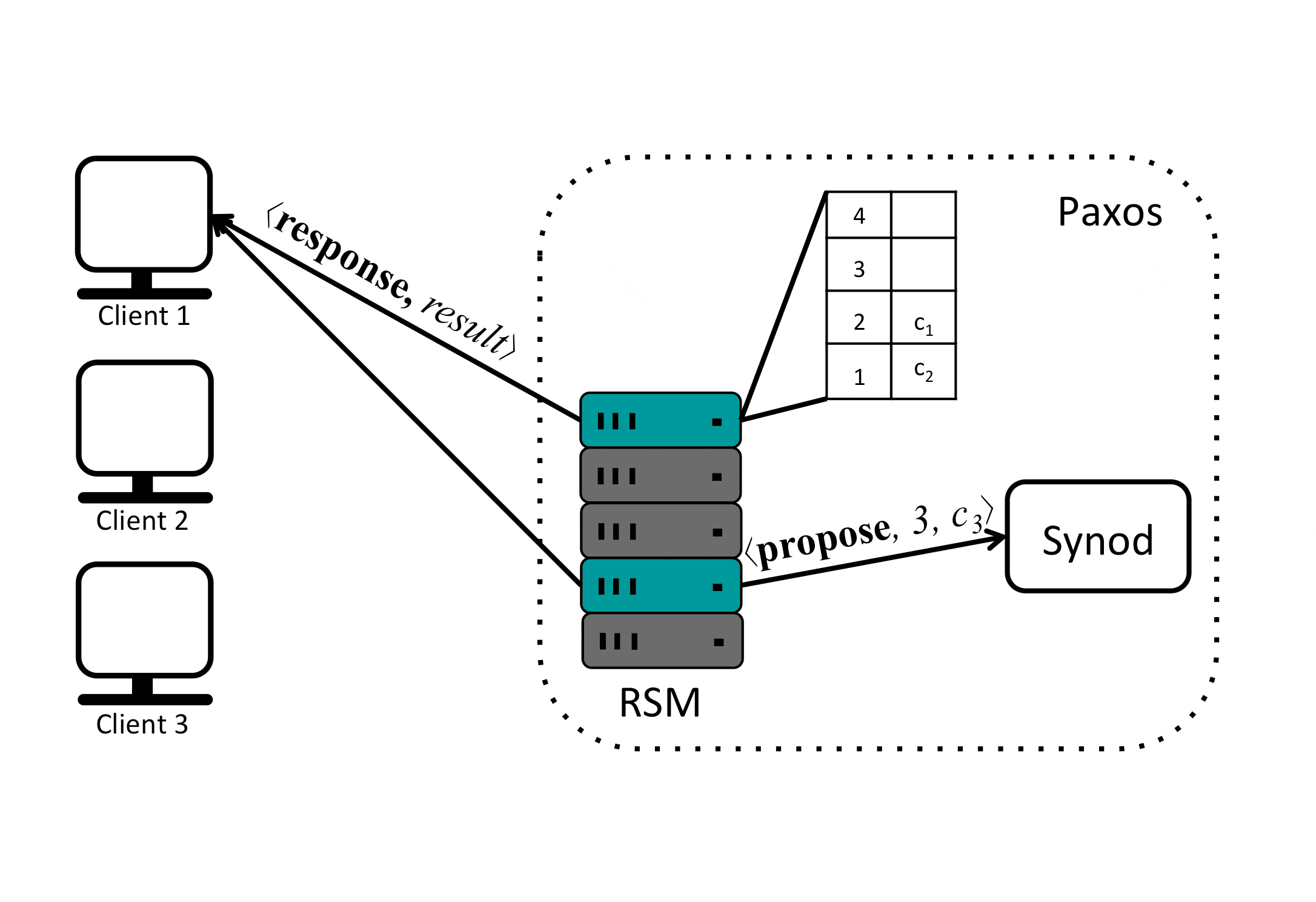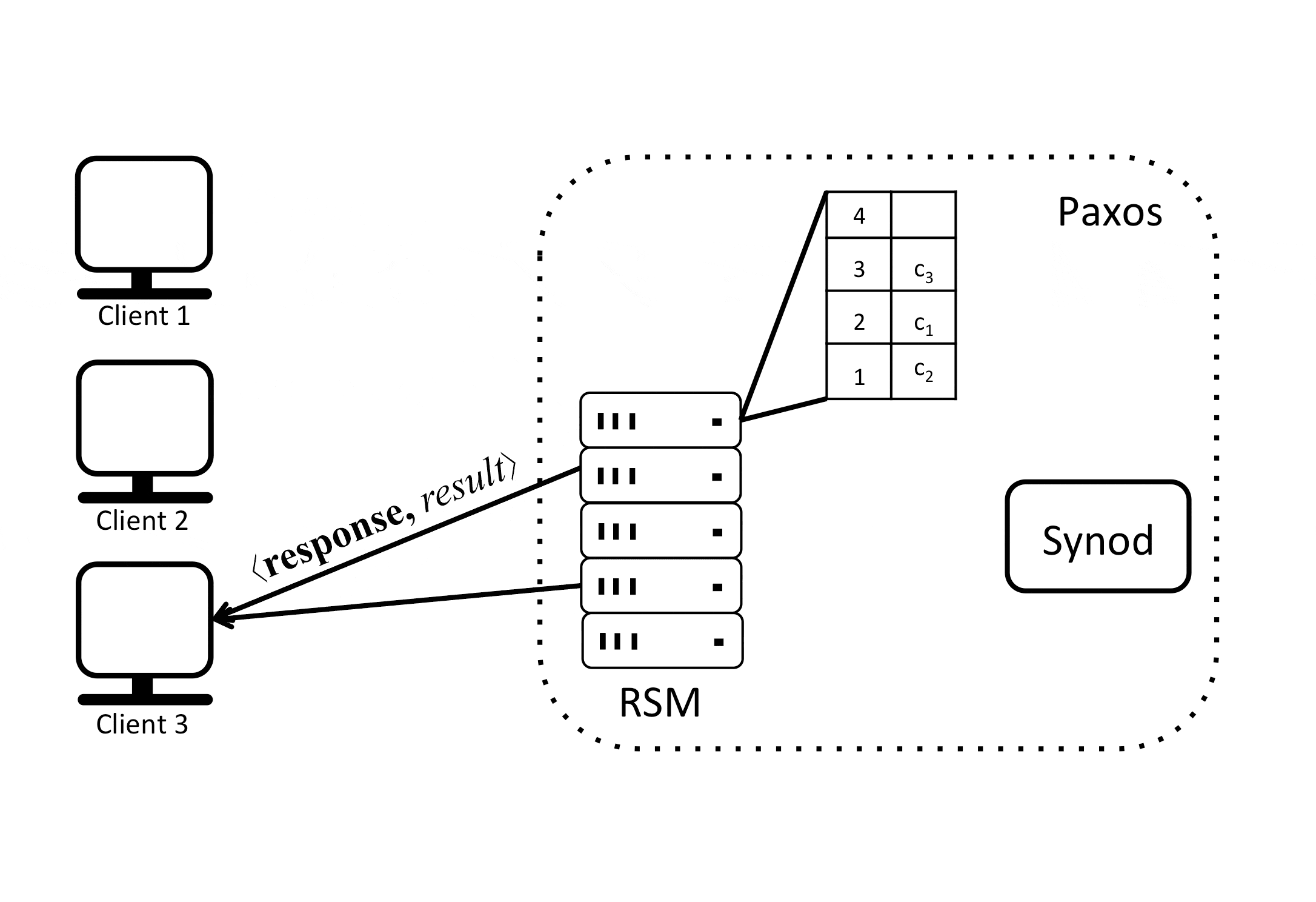
A Paxos RSM keeps an order at which commands will be executed, this is the table shown in the previous diagram. One can think of it as slots that need to be filled with commands. Assuming that this table can be filled in a consistent manner, all replicas can execute commands at the same order. But what if 2 replicas propose different orders (different slot assignment) for a given command \(c_i\)?
Paxos uses consensus to agree on the commands order (slot assignment). So in the previous example when one replica proposed that \(c_1\) takes on slot 1, another replica proposed that \(c_2\) takes on slot 1 and a third replica proposed that \(c_3\) takes on slot 1, the Paxos state machine used the Synod protocol with the underlying protocol for multi-decree Paxos to reach a consensus that \(c_2\) will take on slot 1. This process is repeated and as we can see the commands order is agreed on by replicas in the Paxos state machine which guarantees that they will not diverge.
If you're interested to know more about Paxos internals, I recommend this really awesome article.
Spanner's Paxos state machines use a Paxos variant called time-lease. The idea behind using this specific variant is making leadership long-lived, in a sense, we don't want the Paxos leader to be different frequently for efficiency purposes. The time lease in Spanner is 10 seconds by default. A potential leader sends requests for timed lease votes; upon receiving a quorum of lease votes the leader knows it has a lease. A replica extends its lease vote implicitly on a successful write, and the leader requests lease-vote extensions if they are near expiration.
Spanserver
Now let's take a closer look at the spanserver design which the core of the Spanner universe. The following diagram provides a high level view of the software stack of a spanserver.
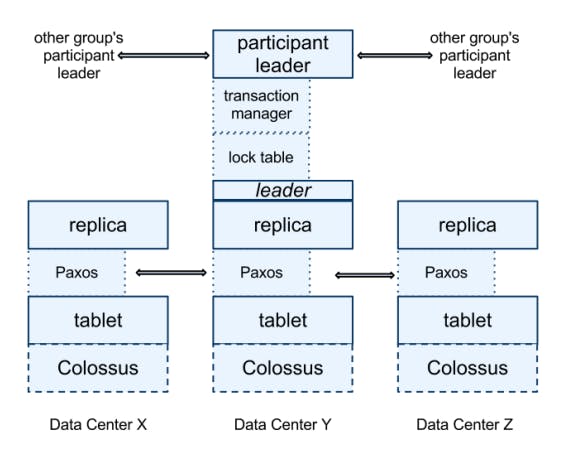
At the very bottom we can see that each spanserver is responsible between 100 and 1000 instances of a data structure called a tablet. A tablet is just an abstraction for a bag of mappings as described before where key-value pairs take on the form of \(\langle \langle key, timestamp \rangle, value \rangle\). The tablet’s state is stored in set of B-tree-like files and a write-ahead log, all on a distributed file system called Colossus (a generic storage system that happens to be used here, not really a part of Spanner itself).
To support replication, each spanserver implements a single Paxos state machine on top of each tablet. The Paxos state machines are used to implement a consistently replicated bag of mappings. The key-value mapping state of each replica is stored in its corresponding tablet. Writes must initiate the Paxos protocol at the leader; reads access state directly from the underlying tablet at any replica that is sufficiently up-to-date (here is were versioning is useful because it enables reading data in the past). The set of replicas is collectively a Paxos group.
As we mentioned before, Paxos leadership is long-lived because it uses the time lease concept explained above. This is key to handling concurrency control efficiently as each spanserver residing on a leader replica implements a lock table which contains the state for two-phase locking: it maps ranges of keys to lock states. So having the same leader for a longer time is good for managing those lock tables.
At every replica that is a leader, each spanserver also implements a transaction manager to support distributed transactions. The transaction manager is used to implement a participant leader; the other replicas in the group will be referred to as participant followers. If a transaction involves only one Paxos group (as is the case for most transactions), it can bypass the transaction manager, since the lock table and Paxos together provide transactionality. If a transaction involves more than one Paxos group, those groups’ leaders coordinate to perform twophase commit. One of the participant groups is chosen as the coordinator: the participant leader of that group will be referred to as the coordinator leader, and the followers of that group as coordinator followers. The state of each transaction manager is stored in the underlying Paxos group (and therefore is replicated).
Directories and placement
On top of the bag of key-value mappings concept, the Spanner implementation supports a bucketing abstraction called a directory, which is a set of contiguous keys that share a common prefix. You can think of this as a table has many rows.
A directory is the unit of data placement. All data in a directory has the same replication configuration. When data is moved between Paxos groups, it is moved directory by directory, as shown in the following diagram.
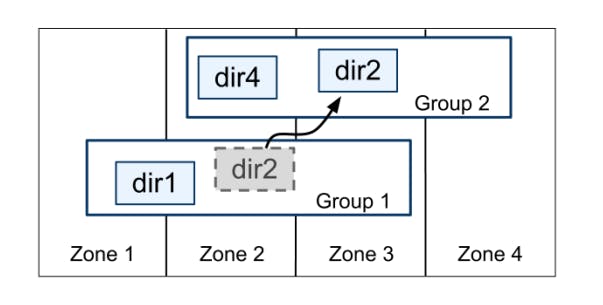
Spanner might move a directory to shed load from a Paxos group; to put directories that are frequently accessed together into the same group; or to move a directory into a group that is closer to its accessors. It's important to note that moving directories is non-blocking and can happen while client requests are still ongoing (described in detail in the paper).
Spanner Data Model
So now let's put it all together and take a look at Spanner's data model to understand more how it stores data. Spanner uses a data model based on schematized semi-relational tables.
An application creates one or more databases in a universe. Each database can contain an unlimited number of schematized tables. Tables look like relational-database tables, with rows, columns and versioned values. Spanner’s data model is not purely relational, in that rows must have names (keys) so every table is required to have an ordered set of one or more primary-key columns.
The following diagram gives an example of a simple photo metadata application that uses Spanner.
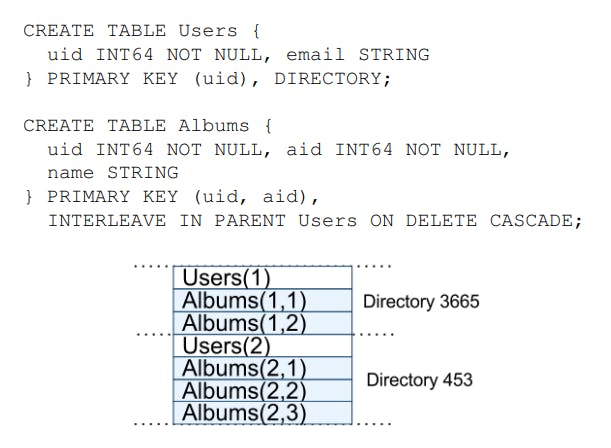
In the previous example Albums(2,1) represents the row from the Albums table for user_id 2, album_id 1. This interleaving of tables to form directories is significant because it allows clients to describe the locality relationships that exist between multiple tables, which is necessary for good performance in a sharded, distributed database. Without it, Spanner would not know the most important locality relationships.
True Time
This part is probably the most innovative part of the entire paper, it describes how Spanner deals with clock uncertainty to satisfy external consistency guarantees during concurrency.
To understand this better, let's take an example of 2 concurrent read-write transactions, \(T_1\) and \(T_2\). The main idea behind external consistency as explained at the beginning of the article is that transactions are executed in a global order as seen by a time reference (a wall clock for example). What Spanner does is that it maps this time reference to something like a sequence number that can be used to order transactions with respect to the time reference. This sequence number is called commit time (which is a timestamp of the moment a transaction committed as the name suggests).
So for example, if \(T_1\) commits before \(T_2\) starts, then \(T_1\) must be assigned a commit timestamp smaller than that of \(T_2\). In an ideal single machine world, the flow will go like this:
- \(T_1\) was fired and shorty after before it commits \(T_2\) was fired, so both \(T_1\) and \(T_2\) are executing concurrently.
- Because \(T_1\) was fired first, it gets assigned a timestamp \(TS_1\) and \(T_2\) gets assigned a timestamp \(TS_2\) such that \(TS_1 < TS_2\).
But what if \(T_1\) went to machine 1 while \(T_2\) went to a different machine? You might think, what's the difference here? Each machine will assign a timestamp \(TS_i\) to its corresponding transaction and the condition \(TS_1 < TS_2\) will still hold. But that assumption is wildly invalid. Why?
You can think of a machine assigning a timestamp to a transaction as a machine calling a method Time.now() to fetch the current time. The thing is, we can never guarantee that all machines will have a synced clock, so we can't guarantee that a call to Time.now() on machine 1 will return a value smaller than a call to Time.now() at machine 2 even if machine 2 issued that call after machine 1, because every machine maintains its local clock and it's impossible to conventionally sync those clocks. If you remember, Calvin assumed that we can do this, that's why I think it's theoretical, but again Spanner is a production grade database so it can't depend on such assumption. This is called clock uncertainty (we are not certain what the time really is now).
So in a sense, we can assume that a call to Time.now() returns an interval \([TS1_l, TS1_r]\) and another call from a different machine to Time.now() returns an interval \([TS2_l, TS2_r]\) and to be able to say that \(TS2\) is definitely (without any uncertainty) greater than \(TS1\) we will have to wait until the 2 intervals \([TS1_l, TS1_r]\) and \([TS2_l, TS2_r]\) no longer overlap at all, then any \(ts\) in interval 1 is definitely smaller than any \(ts\) in interval 2.
The true time API exposes to 2 methods called TT.before(t) and TT.after(t) which mean:
TT.before(t): Means that we are sure that \(t\) has passed, i.e. any call toTime.now()will yield an interval which lower bound is greater than \(t\).TT.after(t): Means that we are sure that \(t\) is in the future, i.e. any previously assigned values are smaller than \(t\).
Now that we know why Spanner needs a clock and what is clock uncertainty, let's take a look at how Spanner handles this in a robust way.
Transactional reads and writes use two-phase locking. As a result, they can be assigned timestamps at any time when all locks have been acquired, but before any locks have been released. For a given transaction, Spanner assigns it the timestamp that Paxos assigns to the Paxos write that represents the transaction commit.
When a transaction begins, a call to Time.now() which assumes returns a range as we explained above, we need to wait for TT.after(t) to be true however, because only then we will be sure that \(t\) is greater than any previously assigned value. Similarly, before a transaction commits and actually uses \(t\) as its commit timestamp, it needs to wait until TT.before(t) is true because only then we will be sure than any call to Time.now() will yield an interval with a lower bound greater than the chosen \(t\).
Considering what's explained above, Spanner has a robust way of ordering transactions in a global order regardless of local clocks on every machine. But how does it keep time if doesn't depend on those local clocks? In fact, Spanner true time uses a clock reference that consists of a GPS clock reference and atomic clock reference. It has a whole complex infrastructure that makes this possible as it keeps clock uncertainty fairly low, around \(7 ms\). Here is a look at how those true time clocks look like:

The paper goes into more detail on how this clock keeps its accuracy and how it handles clock drift, etc.
Moving Forward
The paper goes into more detail about how its concurrency control mechanism handles assigning commit timestamps to different types of transactions but the idea is similar to what we explained in the previous section. I would recommend checking those parts in the paper for more details however.
Conclusion
To summarize, Spanner combines and extends on ideas from two research communities: from the database community, a familiar, easy-to-use, semi-relational interface, transactions and n SQL-based query language; from the systems community, scalability, automatic sharding, fault tolerance, consistent replication, external consistency and wide-area distribution.
Spanner combines some of the features that were missing from Bigtable and Megastore to serve a variety of usecases all powered by innovative ideas like TrueTime and flexible infrastructure.