Calvin: Fast Distributed Transactions for Partitioned Database Systems


As a business develops, the amount of data that business needs to handle grows at a much higher pace which opens a door to a lot of new challenges. One way of handling massive amounts of data and very high throughput requirement is to use a replicated database, much like Aurora which I previously discussed in this series. Another way is to also use a partitioned database which splits your data onto multiple non-intersecting nodes that could still be replicated. One advantage of the partitioned approach is being able to accommodate massive tables and things like that but on the other hand, it complicates consistency and somewhat undermines the transactional properties of database systems.
In order to achieve high scalability, however, today’s systems generally reduce transactional support, disallowing single transactions from spanning multiple partitions or not supporting transactions altogether. The main reason behind this is that transactions in a distributed environment usually needs very costly distributed commits protocols which badly affects throughput (defeats the main purpose of having a distributed database in the first place).
The secret to Calvin’s scalability is that it orders transactions in such a way that distributed commit protocols are not needed and thus avoid this bottleneck that affects throughput.
So What Exactly is Calvin?
Calvin is not a database by itself, it's as the paper describes it "... a practical transaction scheduling and data replication layer...". Calvin uses a deterministic ordering guarantee to significantly reduce the normally prohibitive contention costs associated with distributed transactions.
Calvin is designed to run alongside a non-transactional storage system, transforming it into a shared-nothing near-linearly scalable database system that provides high availability and full ACID transactions. These transactions can potentially span multiple partitions spread across the cluster. Calvin accomplishes this by providing a layer above the storage system that handles the scheduling of distributed transactions, as well as replication and network communication in the system.
In the remainder of this article, we will discuss an overview of the problem of distributed transactions and how Calvin tackles this problem then we will discuss a quick overview of Calvin's architecture and how everything works together in order to make what was previously promised possible.
The Cost of Distributed Transactions
A distributed transaction is a transaction that needs to be executed on multiple partitions in order to be considered durable. The important note here is to make a distinction between this and replicated systems. In a replicated system, like Aurora for example, it works in a single-writer multi-reader configuration, so in a sense, the transaction is executed on a single machine (the writer) then its effects are replicated to system replicas (readers). On the other hand, in partitioned systems, there are however multiple writers each owning a partition of data, so if a transaction spans multiple partitions, this means that all partitions involved in a transaction need to communicate during the transaction execution to ensure atomicity which heavily impedes performance.
The primary mechanism by which distributed transactions impede throughput and extend latency is the requirement of an agreement protocol between all participating partitions at commit time to ensure atomicity and durability. Also to ensure isolation, all of a transaction’s locks must be held for the full duration of this agreement protocol, which is typically two-phase commit. The problem with this, is that two-phase commits are very expensive as they require multiple network calls and round trips between all participating partitions and therefore the time required to run the protocol can often be considerably greater than the time required to execute all local transaction logic.
The paper refers to the duration a transaction needs to hold its lock (including the duration needed to run any commit protocol) as the contention footprint because it represents the duration at which a transaction is competing for resources (locks). It follows that if the contention footprint is long, i.e. transactions hold locks for long, it will cause other transactions to be delayed or aborted altogether (depends on the locking mechanism used, pessimistic vs optimistic).
Example
To understand this better, let's take an example where a transaction needs to be executed on 3 partitions and for that transaction to be ACID, all 3 partitions need to agree to commit or to rollback. Let's call the 3 partitions, \(A\), \(B\) and \(C\). In two-phase commit protocols, one partitions has to act as a coordinator, let's assume \(A\) was chosen to be the coordinator. And so the following happens:
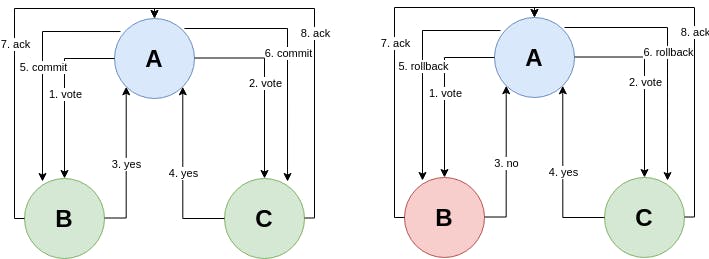
- Voting phase: In which the coordinator partition initiates the transactions for other partitions and listens for votes to either commit or not.
- The commit phase: In which the coordinator partition decides whether to commit only if all partitions voted yes or rollback if at least one partition voted no and sends a notification to participants accordingly.
In both cases, the coordinator partitions commits or rolls back locally when all partitions have sends acknowledgements of commit or rollback.
It's clear that such commit protocols are not suitable for high throughput because:
- They are clearly expensive and network heavy (specially for globably replicated systems where replicas might be located in other continents even). There are however some known optimizations that allows to piggyback (group) some messages in batches which makes it a bit more efficient but not enough.
- Partitions have to keep holding locks throughout the entire protocol (until they get a commit/rollback notification from the coordinator) which as we discussed increases the contention footprint of the transaction.
The Main Idea
Calvin’s approach to achieving inexpensive distributed transactions and synchronous replication is the following: when multiple machines need to agree on how to handle a particular transaction, they do it outside of transactional boundaries—that is, before they acquire locks and begin executing the transaction. Once an agreement about how to handle the transaction has been reached, it must be executed to completion according to the plan—node failure and related problems cannot cause the transaction to abort as a failing node can recover from a replica that's running the same plan in parallel or by replaying its history. Both parallel plan execution and replay of plan history require activity plans to be deterministic—otherwise replicas might diverge or history might be repeated incorrectly.
Calvin depends on replicating transaction inputs rather than effects and because the execution plan (the order at which all transactions are executed) is deterministic and there is a global agreement on which transaction to attempt next, Calvin doesn't need to do redo logging for example, as opposed to other database systems like Aurora that supports commutativity of transactions.
Calvin's Architecture
Calvin is designed to serve as a scalable transactional layer above any storage system that implements a basic CRUD interface (create/insert, read, update and delete).
Calvin consists of 3 main components:
- Sequencer: which is responsible for intercepting transactions and placing transactions into a global transactional input sequence. It's also responsible for replication.
- Scheduler: which is responsible for orchestrating transaction execution using a deterministic locking scheme to guarantee equivalence to the serial order specified by the sequencer while allowing transactions to be executed concurrently by a pool of transaction execution threads.
- Storage: which is responsible for handling all physical data layout. Calvin transactions access data using a simple CRUD interface so any storage engine supporting a similar interface can be plugged into Calvin fairly easily.
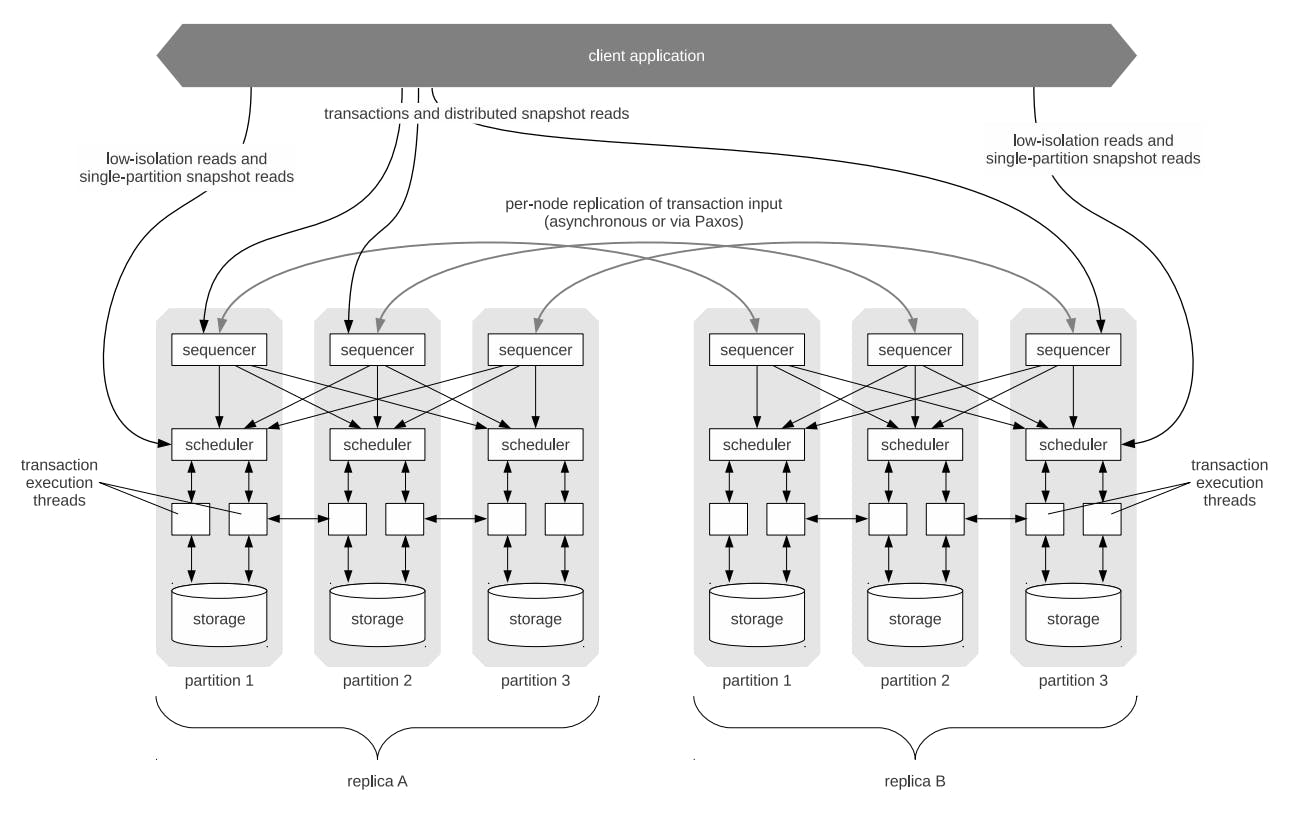
Now let's take a deep dive into each of these components.
1. Sequencer
As we can see from the previous diagram, the sequencer is not a single echo server type of thing, rather, it's distributed across all partitions to avoid having a single point of failure or creating bottlenecks in terms of scaling a single sequencer machine.
Calvin divides time into 10-millisecond epochs during which every partition's sequencer collects transaction requests from clients. At the end of each epoch, all requests that have arrived at a sequencer node are compiled into a batch and replicated to other replicas in the cluster. After a sequencer’s batch is successfully replicated, it sends a message to the scheduler on every partition within its replica with the needed metadata to allow each scheduler to piece together its own view of a global transaction order by interleaving all sequencers’ batches for that epoch.
Replicating transaction inputs can be done either synchronously or asynchronously, each has its pros and cons in terms of latency or complicating failovers. We have discussed this before in the Aurora series here.
2. Scheduler
Once the scheduler components receives transactional inputs from the sequencer it attempts to piece together the metadata to reach a global order of transactions and it starts executing those transactions in that order via a group of execution threads.
The scheduler layer is what handles concurrency control and because Calvin is just a layer that gets plugged on top of storage systems, it can no longer make any assumptions about the physical implementation of the data layer and cannot refer to physical data structures like pages and indexes, nor can it be aware of side-effects of a transaction on the physical layout of the data in the database. Rather it deals with with logical components which complicates the process of concurrency control.
Calvin’s deterministic lock manager is partitioned across the entire scheduling layer and each node’s scheduler is only responsible for locking records that are stored at that node’s storage component—even for transactions that access records stored on other nodes. The locking protocol resembles strict two-phase locking, but with two added invariants:
- For any pair of transactions \(A\) and \(B\) that both request exclusive locks on some local record \(R\), if transaction \(A\) appears before \(B\) in the serial order provided by the sequencer then \(A\) must request its lock on \(R\) before \(B\) does. This implies that all transactions must declare its full read/write sets in advance.
- The lock manager must grant each lock to requesting transactions strictly in the order in which those transactions requested the lock. So in the above example, \(B\) could not be granted its lock on \(R\) until after \(A\) has acquired the lock on \(R\), executed to completion, and released the lock.
Once a transaction has acquired all of its locks under this protocol (and can therefore be safely executed in its entirety) it is handed off to a worker thread to be executed. Each actual transaction execution by a worker thread goes through the following five phases:
- Read/write set analysis: In this phase, the execution thread analyzes items in the read/write set declared by a transaction and determines which items are located locally on the same partition the execution thread is running and which items are not. Those items that are not are further categorized into active participants which are those partitions containing items of the write set of a transaction and passive participants which are those partitions containing only items of the read set of a transaction.
- Perform local reads: In this phase, the worker thread looks up the values of all records in the read set that are stored locally. Depending on the implementation of the physical storage layer, local copies of these records might be made and stored in a buffer.
- Serve remote reads: In this phase, all results from the local read phase are forwarded to counterpart worker threads on every actively participating partition. Since passive participants do not modify any data, they need not execute the actual transaction code and therefore do not have to collect any remote read results. If the executing partition is a passive participant, it's finished after this phase.
- Collect remote read results: If the worker thread is executing at an actively participating node, then it must execute transaction code, and thus it must first acquire all read results—both the results of local reads (acquired in the second phase) and the results of remote reads (forwarded by every participating node during the third phase).
- Transaction logic execution and applying writes: Once the worker thread has collected all read results, it proceeds to execute all transaction logic, applying any local writes. Non-local writes can be ignored since they will be viewed as local writes by the counterpart transaction execution thread at the appropriate partition and applied there.
The previous mechanism, while on paper seems straightforward, but it has some complications. For example, some transactions can't really declare their full read/write sets before the transaction begins. Those transactions are called dependent transactions because they might need to perform reads in order to be able to declare their full read/write sets. Calvin handles those types of transactions by firing an inexpensive, low-isolation, unreplicated, read-only reconnaissance query that performs all the necessary reads to discover the transaction’s full read/write set.
Some other problems with this approach are related to latency when it comes to reading records from disk which will be discussed in the next section related to the storage layer.
3. Storage
As mentioned before, Calvin abstracts dealing with storage by being able to work as a plugin with any storage system that implements a CRUD interface. There was a previous paper published by the Calvin team that only assumed storage will be in-memory resident storage to simplify some problems. This paper however tries to tackle the more general problem of having disk-resident data.
But why is having disk-resident data a problem for Calvin? Let's consider the following example: If a transaction (let’s call it \(A\)) is stalled waiting for a disk access, a traditional system would be able to run other transactions (\(B\) and \(C\), say) that do not conflict with the locks already held by \(A\). If \(B\) and \(C’s\) write sets overlapped with \(A’s\) on keys that \(A\) has not yet locked because it's stalled on disk access, then execution can proceed in manner equivalent to the serial order \(B − C − A\) rather than \(A − B − C\)
But as we agreed before, Calvin's approach is totally dependent on executing transactions in the exact same order as the sequencer planned, which suggests that \(B\) and \(C\) will have to stall as well and wait until \(A\) is finished, bringing the system throughput to a quick halt.
Calvin avoids this disadvantage of determinism in the context of disk-based databases by following its guiding design principle of moving as much as possible of the heavy lifting to earlier in the transaction processing pipeline, before locks are acquired. Any time a sequencer component receives a request for a transaction that may incur a disk stall, it introduces an artificial delay before forwarding the transaction request to the scheduling layer and meanwhile sends requests to all relevant storage components to “warm up” the disk-resident records that the transaction will access. If the artificial delay is greater than or equal to the time it takes to bring all the disk resident records into memory, then when the transaction is actually executed, it will access only memory-resident data.
As we can see, this seems like a shaky implementation somewhat, because what if the artificial delay is too long or too short. If it's too short, we will run into the same problem we explained above and if it's too long, it will cause transactions to unnecessarily take longer. Calvin uses a predictive delay mechanism that they claim works such that at least \(99%\) of disk-accessing transactions were scheduled after their corresponding pre-fetching requests had completed.
Checkpointing
Because a database system is still bound to failure at anytime, being able to recover quickly is a very important concern.
As we mentioned before, Calvin ditches the idea of physical redo logging because given the transactional input history, it can replay this history in the exact same order it was initially executed in because of its determinism guarantees. So in theory, a failing Calvin system, can depend on the logged transactional input to rebuild its state.
But replaying the entire transactional history is very expensive, so Calvin tries on shorten this process by taking regular snapshots so that it will only have to replay history of the renaming deltas (the duration between 2 snapshots).
Calvin supports 3 different snapshot algorithms that are quite lenghty and you can refer to them in the paper in section 5.
Review
The paper is published by a team of computer scientists at Yale's university, so I am probably not qualified enough to judge their work, but here are my 2 cents anyway.
The paper discuss the problem of distributed transactions pretty well, explains why is it complicated and why lots of distributed databases decide to ditch transactions altogether in order to simplify operations.
It then introduces a very interesting idea of avoiding expensive commit protocols via deterministic locking schemes. My only problem tho, which could be related to my understanding of the paper, is that it makes some pretty bold assumptions, for example:
- In the sequencer layer, as we mentioned, time is split into epochs and transactions received during each epoch are complied as a batch and sent to schedulers with some metadata. Those metadata, as the paper mentions, include the epoch number (which is synchronously incremented across the entire system once every epoch), but it doesn't explain how is that possible specially during failures and how to keep all partitions in a time sync?
- There is another assumption that a distributed transaction begins executing at approximately the same time at every participating node which then later is explained to not be true in case of disk-resident data which is handled by a predictive, artificial delay approach, but it doesn't explain what happens if that assumption doesn't hold.
- There is another major assumption that sequencers, in order to be able to accurately predict delay times, will have to keep track of hot records across the entire system—not just the data managed by the storage components co-located on the sequencer’s node which as the paper mentions not a scalable solution and finding a more robust approach is as of the paper publish date is still pending as future work.
Overall, I think this paper is a good read and the idea is definitely interesting, specially considering that there are database systems that are based on some Calvin ideas like faunaDB and Calvin is also usually compared to databases like Google's Spanner which I actually have next on my reading list.
Anyways, hope you enjoyed this article.
References
Calvin: Fast Distributed Transactions for Partitioned Database Systems