


Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases (Part 1)


A couple of days ago I came across a very interesting paper by Amazon Web Services (AWS) titled Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases which discusses the architecture and the design decisions made while building Amazon Aurora.
Amazon Aurora is a relational database service for OLTP (Online Transaction Processing) workloads offered as part of AWS.
If you have ever used AWS then you probably know about how Aurora is famous of its reliability, resiliency and high performance. All are essential traits of any cloud database service in a time where a lot of companies are moving to cloud based service providers to avoid the hassle of maintaining an in-house database or even maintaining a database setup in an adhock cloud environment, like for example, hosting a database on EC2 machines and the likes. Cloud services also provide the ability to provision resources on a flexible on-demand basis and to pay for this capacity using an operational cost model as opposed to a capital expense model.
Decoupling Compute Tier and Storage Tier
The first thing that can be quickly noticed from the paper is that AWS decided to go against the traditional MySQL design where the entire database (server and storage engine) are just one tier, for example, when you host a database on a normal machine, it uses the local disk for storage (or any attached volumes) and the machine resources for compute which cause both compute tier and the storage tier to be coupled.
It's easy to see the shortcomings of the traditional design but let's consider some scenarios:
- If the local disk is physically attached to a machine, then problems in the machine might cause the disk to be lost.
- If the local disk which is physically attached to a machine becomes full, the entire machine will have to replaced with another one with a larger disk and it would be tricky to migrate the old data into the new machine's disk.
Considering the above scenarios, it makes sense to decouple the storage tier from the computer tier. To make this more clear, let's go over some reasons why this decoupling is useful:
- No disks are physically attached to the compute tier instances which ensures that any misbehaving or lost storage instances can be fixed or replaced without stopping the database server running on the compute tier which improves availability.
- Allows for having a fleet of storage instances as opposed to just one disk. Such configuration makes it possible to:
- Replicate data across multiple storage instances in the fleet.
- Spread out the storage instances in the fleet to be located in different physical locations, like for example, AWS Availability Zones which improves immunity against localized events such as, power outages in one data center or even natural disasters in one city.
- Parallelize I/Os to the storage tier because it now has multiple storage instances which eliminates I/O bottlenecks (though it introduces a network bottleneck to be discussed later).
- Allows scaling disks without replacing or taking down compute tier machines.
- Allows for multi-tenancy in the storage tier because they can be connected to different compute tier (different databases for different customers) which is quite useful for a cloud provider.
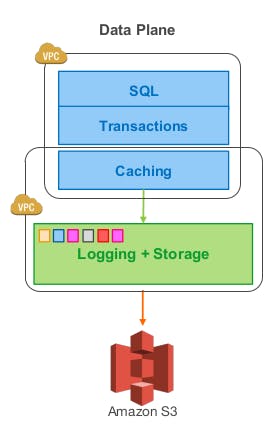
As we can see from the previous diagram representing the data plane of Aurora that it uses a service-oriented architecture with a multi-tenant scale-out storage service loosely coupled to a fleet of database instances. Although each instance still includes most of the components of a traditional kernel (query processor, transactions, locking, buffer cache, access methods and undo management) several functions (redo logging, durable storage, crash recovery, and backup/restore) are off-loaded to the storage tier.
Durability at Scale
If there is one thing that a database should do very well then it would definitely be storing data reliably in the sense that if a record was acknowledged to have been written, then it persists and it can be later read. This shows that the compute instance (the database server) lifetime is not correlated to the storage tier lifetime since compute instances can fail, they can be shutdown by customers or resized up and down based on the needed capacity which shouldn't affect the storage tier and that's why the storage tier is decoupled from the compute tier as mentioned before.
The storage tier itself can experience the same failures that would face any large scale distributed system such as, disk failures or the continuous background low-level noise from network path failures. To provide resiliency against such failures, each disk is replicated.
Achieving Consistency
One approach to tolerate failures in replicated systems is the use of quorum based consensus protocols. This means that if a system has \(V\) replicas, each decision (write or read) will have to obtain a quorum in order to be acknowledged, i.e. read operations have to obtain a quorum of \(V_r\) votes and write operations have to obtain a quorum of \(V_w\) votes.
To achieve consistency in a replicated environment, the quorums must obey 2 rules:
- Each read must be aware of the most recent write, in other words, the set of nodes used for read has to intersect with the set of nodes used for write which can be expressed as \(V_r + V_w > V\). This ensures that the read quorum contains at least 1 node with the newest version of the data.
- Each write must be aware of the most recent write to avoid conflicting writes. This can be expressed as \(V_w > V/2\).
So for example, if \(V = 3, V_r = 2, V_w = 2\), this will stratify both conditions (\(V_r + V_w > V, V_w > V/2\)). Let's see why would this work:
- Read: When data is read, it will be read from 2 nodes and because data is written to 2 nodes, if we had 2 operations (write then read), the write operation wrote data to \(node_1, node_2\) and the read operation can either read data from \(node_1, node_2\) or from \(node_1, node_3\) or from \(node_2, node_3\), we know for sure that one node has to be repeated in the read and write sets which guarantees that a read after a write will be able to read the written data.
- Write: When data is written, it will be written to 2 nodes. So let's assume that we have 2 write operations, the first wrote data to \(node_1, node_2\) and the second wrote data to \(node_1, node_3\), we know for sure that the 2 write operations will overlap in at least 1 node which means that the second write will be aware of the first write via the repeated node (the node that was part of both write operations) which guarantees that no conflicting writes will occur.
While the previous example is a valid quorum configuration, the paper mentions that it's not adequate enough. Let's consider AWS Availability Zones, an AZ is a subset of a Region that is connected to other AZs in the region through low latency links but is isolated for most faults, including power, networking, software deployments, flooding, etc.
If we have 3 replicas of the data (\(V = 3\)) and each replica is located in a separate AZ, so we have 3 AZs (\(A, B, C\)). If we lose an entire AZ due to a major failure, it will break read and write quorums of any concurrently failing replicas, which means that while a failure of 1 AZ still leaves out 2 working replicas which still can achieve quorum, if any of the 2 remaining replicas experience any unrelated failures (like a temporary network noise or disk failures) it will break quorum and render the system unavailable.
AWS decided that Aurora should be tolerate:
- Losing an entire AZ and one additional node in another AZ, so (\(AZ + 1\)) without breaking read quorum (ability to read data).
- Losing an entire AZ without breaking write quorum (ability to write data).
Based on the previous decisions, AWS is using \(V = 6, V_r = 3, V_w = 4\) which satisfies the previously mentioned consistency conditions because \(3 + 4 > 6, 4 > 6/2\). The 6 replicas are spread out across 3 AZs (2 replicas per AZ).
So now let's see if that configuration satisfies both design decisions:
- If we lose an entire AZ (2 nodes) and another node, so a total of 3 nodes, this means that we still have 3 other available nodes and because \(V_r = 3\) then read quorum is achieved.
- If we lose an entire AZ (2 nodes), this means that we will still have 4 available nodes and because \(V_w = 4\) then write quorum is achieved.
Segmented Storage
In the previous section we discussed how Aurora would be able to survive the loss of an entire AZ and 1 node in another AZ without breaking read quorum. But why is this considered sufficient? And how is it achieved?
The paper discusses the idea of reducing the time window at which 2 nodes could be unavailable at the same time in an uncorrelated unavailability event (note that losing 2 nodes in the same AZ because we lost the entire AZ is a correlated failure). Logically, the solution is to try to reduce the time windows in which a node can be unavailable by being able to repair a failing node in the least possible time which naturally reduces the probability of another node failing within that time window (being as small as possible).
To achieve that, Aurora employees a segmented storage system where disks are split into small segments each is \(10 GB\) at the time the paper was published. This is because nodes can vary in size and the time to repair them would be unpredictable while in the segmented model, fixed size segments became the unit of independent background noise failure and repair. Such failures are detected and automatically repaired. A \(10GB\) segment can be repaired in 10 seconds on a \(10Gbps\) network link. This means that for a read quorum to break, an entire AZ will have to be lost and we will have to see 2 nodes failing within a 10 seconds time window which is, according to the paper, sufficiently unlikely considering their observed failure rates.
Operational Benefits of Resiliency
It's clear by now how fault tolerant Aurora is, but fault tolerance also comes with the added benefit of making operations a lot easier, simply because a system that can handle a long-term outage can handle a brief network failure or a spike in load on a storage node. It also makes maintenance a lot easier because maintenance events that cause one segment to be unavailable can be modeled as failures, so basically rolling a software update or an OS patch or doing heat management is as simple as marking one segment as unhealthy and the quorum system will replace it.
Moving forward
Although the paper is around 10 pages long, it's actually packed with details. So to keep this article short, I will publish part 2 later. In part 2, the paper discusses the problems that a 6-way replication would introduce and how they overcame it and achieve more than 30x more throughput than the base MySQL codebase they started with while enjoying all the resiliency guarantees we discussed above..
References
Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases