


In this article, I am going to discuss how can we implement point queries in an otherwise mainly optimized for aggregations database like ClickHouse. First, I will start by explaining what are point queries, what is ClickHouse and why is it a challenge to implement point queries in a database like ClickHouse. Then I will introduce an example design problem to show the different techniques and optimizations that can be applied to achieve our requirements.
What are point queries?
A point query is a query that's meant to list one or more rows from a given table. So for example queries like this are considered point queries:
SELECT * FROM tbl WHERE tbl.id = '12345';
Or
SELECT * FROM tbl WHERE tbl.date > '2023-01-01';
This is opposed to queries that calculate aggregations like for example a query to calculate the average grade for a student from a table like this:
SELECT AVG(grade) as avg_grade FROM tbl WHERE tbl.name = 'awesome student name';
What is ClickHouse?
ClickHouse is an open-source column-oriented DBMS for online analytical processing that allows users to generate analytical reports using SQL queries in real-time.
Some types of databases are row oriented, in a row-based database, data is laid out on disk as rows, for example, if you have a table with columns (id, name, email), the values for those 3 columns are all stored together in a sequence of bytes representing this row.
On the other hand, columnar databases don’t store all the values from one row together, but store all the values from each column together instead. If each column is stored in a separate file, a query only needs to read and parse those columns that are used in that query, which can save a lot of work. This allows columnar databases, like ClickHouse, to leverage the fact that the data is stored in this fashion to enable features like efficient data compression and vectorized processing.
To learn more about columnar databases, check this article: Designing Data Intensive Applications: Ch3. Storage and Retrieval | Part 2
Problem Description
First of all, let's just all agree that columnar databases like ClickHouse are not meant to be used that way, but sometimes, you just want to use your existing storage solution to serve different use cases.
Now let's assume that we must implement this, let's first start by discussing the setup, the design requirements and constraints.
Current Setup
Let's assume we have a table called logs as follows:
CREATE TABLE IF NOT EXISTS logs
(
service_id UInt8,
container_id UInt32,
timestamp DateTime64(3, 'UTC'),
log_level LowCardinality(String)
)
ENGINE = MergeTree
PARTITION BY toYearWeek(timestamp)
ORDER BY (service_id, container_id, timestamp)
In this table, we store system logs such that a log record belongs to a specific container and that container belongs to a specific service. We also store when that log was created and the log level (debug, error, etc.). The table is using the MergeTree engine, to know more about merge trees, check this article: Designing Data Intensive Applications: Ch3. Storage and Retrieval | Part 1. The table is also partitioned by the week of the year the log was recorded (so basically every week of logs is in its own partition). And the table is ordered by (service_id, container_id, timestamp), the ORDER BY statement in ClickHouse acts like a primary index that tells ClickHouse how to store data on disk. We will circle back to this later to show the importance of choosing good ORDER BY expressions to achieve high performance.
Design Requirements
We want to be able to do the following:
Fetch a specific log record given its unique identifier.
List all logs via pagination:
Fetch the most recent log.
Fetch the earliest log.
Move left and right through logs based on their creation time.
Design Constraints
We want the system to abide by the following:
The
logstable can table tens of billions of records.Fetch and paginate operations need to respond within a timely manner (< 1 sec).
Any added storage for the unique identifier shouldn't exceed \(10\%\) of the total table size.
Why is it challenging to implement this in ClickHouse?
Given the problem description, the changes we need to do to the given table to achieve the design requirements under the given constraints are basically:
Add a unique identifier to uniquely identify each log record.
The unique identifier needs to be sortable to be able to do pagination.
The unique identifier needs to be as small in size as possible not to exceed the allocated extra storage.
The table needs to be more optimized for serving this type of query to achieve the time constraints.
Unfortunately, not a lot of the above is easily achievable in ClickHouse out of the box because:
ClickHouse doesn't have the concept of unique identifiers. There are no uniqueness guarantees like for example a primary key in MySQL. So uniqueness will have to be guaranteed from the application's side.
ClickHouse thrives on its ability to compress columns and high cardinality columns, let alone, unique columns which will not compress at all since there are no patterns or repetitions.
Achieving fast queries is dependent on how the table is ordered as mentioned before. So even if we add a unique identifier, just using it without changing the table ordering properly would be very slow.
So let's get to work!
Choosing the perfect unique identifier
So far we know we need a unique identifier, that will be generated from the application's side so it better be easy, and it should be sortable to be able to do pagination and it should be small.
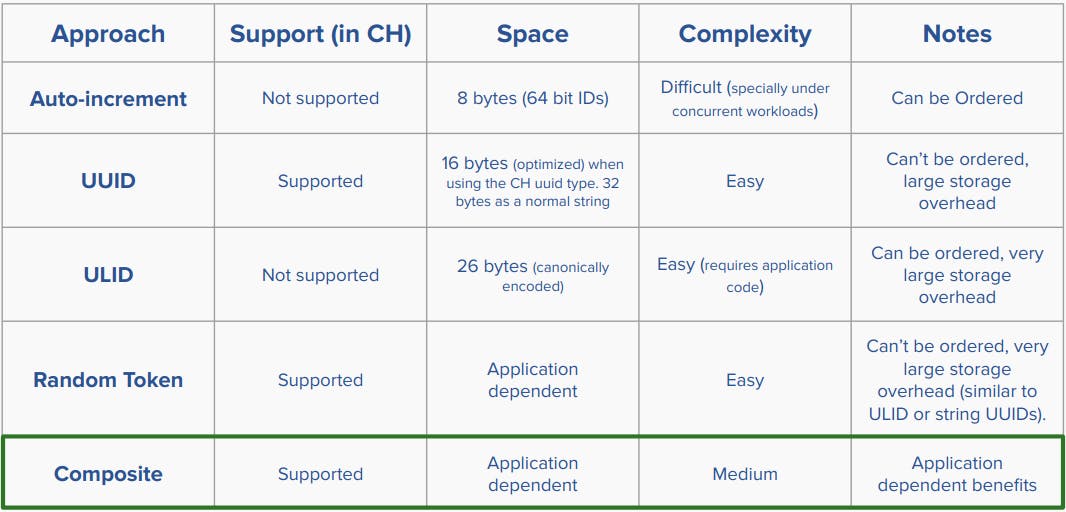
The above table compares a bunch of different alternatives, for example:
Auto-increment: Those are not supported in ClickHouse. They are not efficient and complex to generate from the application's side, especially under concurrent workloads. But they are small in size and can be ordered.
UUID: They are supported in ClickHouse in a compact format and they are very easy to use. But they can't be ordered and they are twice as big as an auto-increment id.
ULID: They are not supported in ClickHouse, but they are very easy to generate from the application's side unlike auto-increment ids and they can also be ordered but they are very large in size because they have to be stored as strings.
Random token: Those are supported in ClickHouse, and their size is configurable depending on the application's need but they can't be ordered and they could have high storage overhead if chosen to be strings.
Composite: ClickHouse supports the ability to add composite primary keys. The main idea here, is to lower the cardinality of the unique id using other existing columns in the table. For example, if we expect the entire table to contain 10 billion records, we will need an
UInt64to support that, but if we know that there can only be around 50,000 records for the same service, the same container and the same creation timestamp, we can for example go for aUInt16instead.
Here we choose to use the composite key for the following benefits:
Make use of existent semi-unique columns.
Because we will be using some existing columns that are semi-unique, the random component can be very small (controllable based on the use case) which keeps the extra storage overhead minimal.
Can be tuned to be sortable (in combination with the
timestampcolumn we already have).Can be tuned to use existing columns that are prefixes of the table’s ordering which achieves very good performance for point queries.
So assuming that a UInt16 can uniquely identifiy logs coming from the same service, same container and same creation timestamp, we can alter our table to look like this:
CREATE TABLE IF NOT EXISTS logs
(
service_id UInt8,
container_id UInt32,
timestamp DateTime64(3, 'UTC'),
content String,
random_comp UInt16 default rand16(),
date Date MATERIALIZED toDate(timestamp)
)
ENGINE = MergeTree
PARTITION BY toYearWeek(timestamp)
ORDER BY (service_id, container_id, date, timestamp, random_comp)
In this table the ORDER BY is chosen such that each column has a lower cardinality than the column to its right, that's why we added the random component at the very end of the ORDER BY. Ordering tables this way enables ClickHouse to purne data and only inspect the minimal numeber of granuls needed which is essential to achieving high performance.
We have also added a materialized column representing the date of the timestamp and incroporated it in our ORDER BY expression before timestamp because it will have a lower cardinality. This trick also allows ClickHouse to prune data better.
So now our unique identifier conisits of 5 parts which are (service_id, container_id, date, timestamp, random_comp), and the sortable id that will be used externally is a concatation between the timestamp and the random_comp, like this for example: 1678045341936-2255229327 since logs are always scopped by their service_id and container_id (i.e. they will be provided in any query in conjugtion with the id). So a point query to fetch a specific log given its id will look like this:
SELECT *
FROM logs
WHERE service_id = 'svc1'
AND container_id = 'con1'
AND date = '2023-05-03'
AND timestamp = '1678045341936'
AND random_comp = '2255229327';
Which utilizes table ordering. The following is a benchmark on a table containing 760 million rows showing the effect of the optimizations we made:
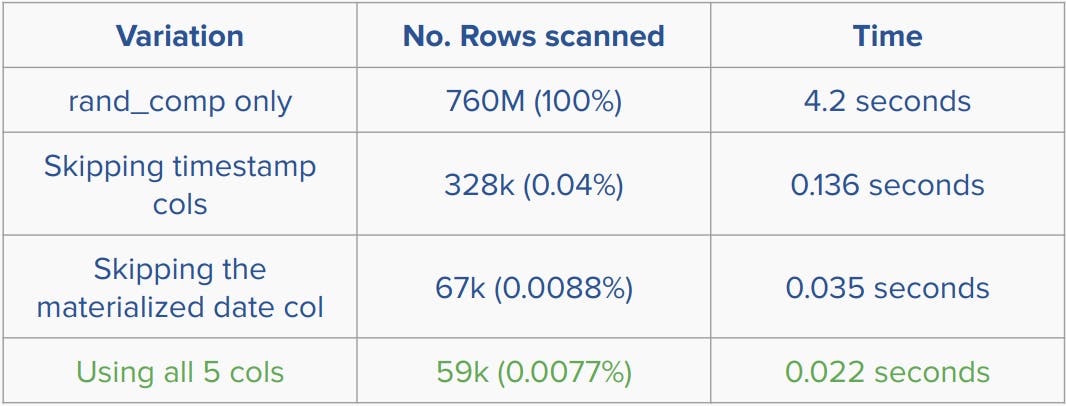
This shows that using all parts of the key achieves the best performance.
Scrolling and Pagination
Now that we have a unique identifier set up, let's turn our attention to implementing pagination. ClickHouse doesn’t support something like a scrolling API out of the box, but it can be implemented if a correct key is designed.
Now let's recap our use cases:
Fetch a page of ids containing the most recent log.
Fetch a page of ids containing the earliest log.
Fetch a page of ids for the next or previous pages relative to the current page.
Since our composite ends with (..., date, timestamp, random_comp), the time portion of this key makes it sortable because we can sort timestamps. If any two logs had the same random_comp which should be rare, they will be sorted arbitrarily but deterministically (i.e. we don't care how they get sorted but they will always be sorted the same way).
So now let's take a look at how those queries can be written.
Fetching the page containing the most recent log
SELECT CONACT(toString(timestamp), '-', toString(id)) AS log_id
FROM
(
SELECT
toUnixTimestamp64Milli(timestamp) AS timestamp,
random_comp AS id
FROM logs
WHERE service_id = 'svc1'
AND container_id = 'con1'
ORDER BY
service_id DESC,
container_id DESC,
date DESC,
timestamp DESC,
random_comp DESC
LIMIT 20
)
Note: We have to specify columns in the ORDER BY one by one (not as a tuple), In order for the optimize_read_in_order optimization to work and make use of the prefix of table ordering.
The query for fetching the earliest page is very similar to this but the opposite way of ordering.
Fetching the page next to the current page (given timestamp and random_comp)
SELECT CONACT(toString(timestamp), '-', toString(id)) AS log_id
FROM
(
SELECT
toUnixTimestamp64Milli(timestamp) AS timestamp,
random_comp AS id
FROM logs
WHERE service_id = 'svc1'
AND container_id = 'con1'
AND date >= toDate(given_timestamp)
AND (
timestamp > given_timestamp
OR (
timestamp = given_timestamp
AND random_comp > given_random_comp
)
)
ORDER BY
service_id ASC,
container_id ASC,
date ASC,
timestamp ASC,
random_comp ASC
LIMIT 20
)
Note: Here we are not comparing the given id against the timestamp and the random_comp columns directly like so (timestamp, random_comp) > (given_timestamp, given_random_comp) as it was found to be more efficient to compare them individually as mentioned in the query.
The following is a benchmark for the same table to show the effect of the different optimizations done while paginating:
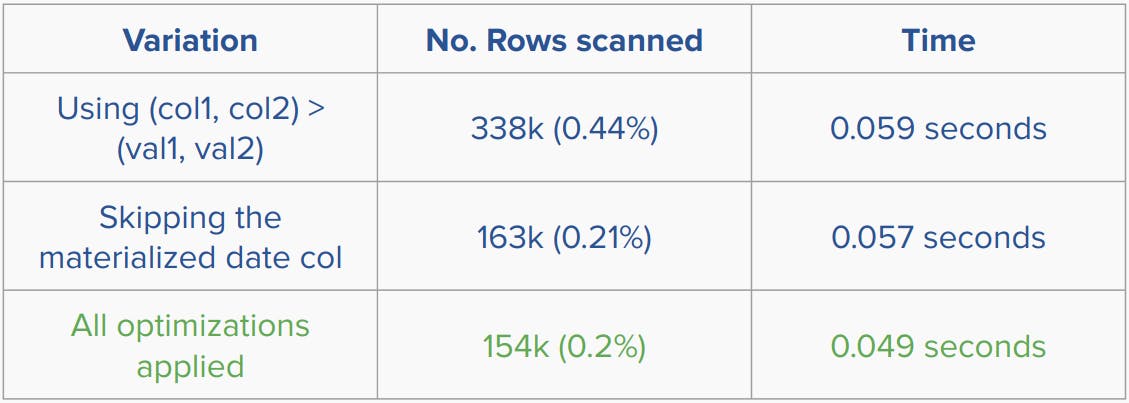
Lessons learned
ClickHouse is a columnar database best suited for aggregations. If your only use case is point queries, then maybe ClickHouse is not for you.
Unique identification for point queries can be implemented by adding small random components to a composite of columns to lower the cardinality of the random component and minimize the overall storage overhead.
Normal timestamp columns can be used to make the entire key sortable without having to use something like a ULID (timestamp: 8 bytes + random_comp: 2 bytes << ULID: 26 bytes).
Table ordering is very important for performance tuning, so be aware of column cardinality and try different things.