




In the previous article of this series, we discussed the first part of chapter 3 in Data Intensive Applications which discussed storage and retrieval. We discussed many storage related topics, mainly data structures used for storage in data stores, such as LSM-trees, B-trees, hash indexes, etc.
In this article, we will discuss another type of data stores which is Column-Oriented Storage which leads a different paradigm when it comes to storing data to serve a different use case than normal row or document based data stores.
I recommend checking out this article in which I detail how we use a columnar database called ClickHouse to store 3 billion data rows every day at Instabug.
What is Columnar Storage?
Let's first start by a quick recap of how row-based storage is organized. In a row based database, data is laid out on disk as rows, for example, if you have a table that the columns (id, token, created_at), the values for those 3 columns are all stored together in a sequence of bytes representing this row. Note that as we discussed earlier, that in many cases as database administrator, you will be optimizing for common query patterns, mainly by creating secondary indexes on subset of the columns which are essentially just a sorting order of those columns that points to where the data is in the primary index or on disk (depending on the storage engine used).
In row oriented databases, queries like:
SELECT * FROM tbl;
Just fetch all rows which are stored together which is quite efficient. Row based databases are commonly known as OLTP databases (online transaction processing).
But there exists other use cases, mainly analytics where you would query your database to calculate an aggregate or to generate an analytical report which might only need to use just a few columns which in a row based database will lead to reading the entire row then returning/operating on the specified set of columns.
On the other hand, columnar databases don’t store all the values from one row together, but store all the values from each column together instead. If each column is stored in a separate file, a query only needs to read and parse those columns that are used in that query, which can save a lot of work.
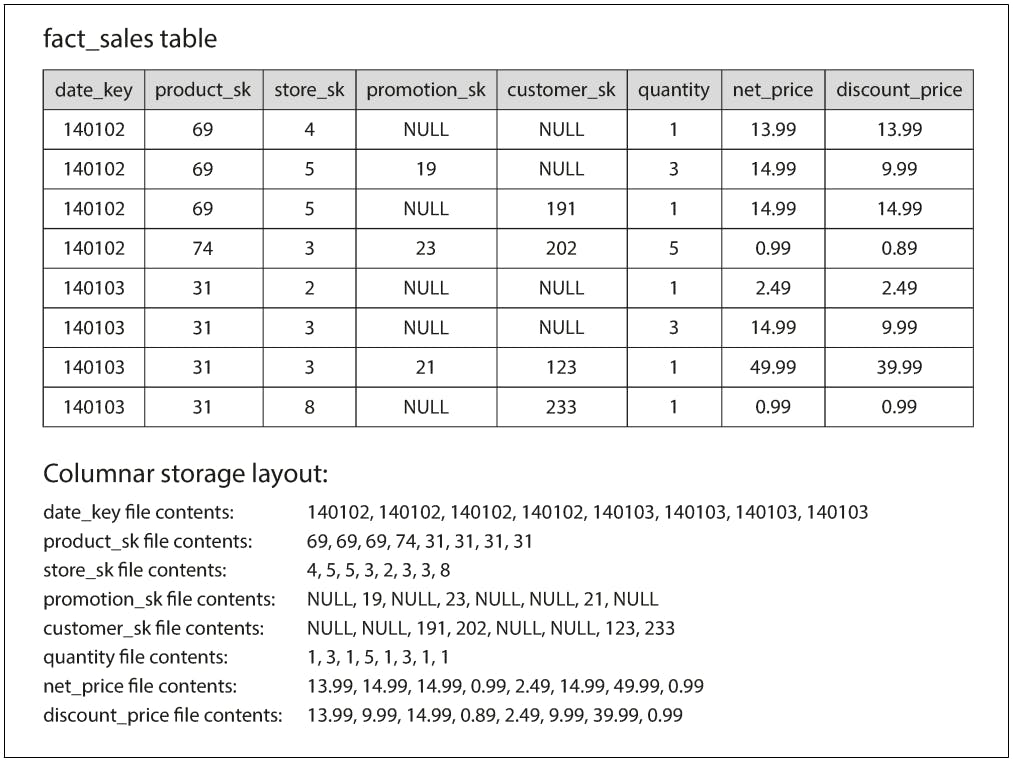
The previous diagram illustrates this principle, as we can see the values of each column are all stored together in separate files as opposed to the entire row being stored together. For this to work, values of all columns have to be sorted in the same order, so the \(n_th\) value of some column \(col_1\) and the \(n_th\) value of some other column \(col_2\) belong together in the same row. This basically how column oriented oriented databases are able to reconstruct a row if needed (like for example to serve a point query).
Column Compression
As explained in the previous section, organizing data in a columnar fashion helped in not having to read/parse the entire row only to operate on a small subset of columns which is a good save specially that most OLAP databases have very wide tables (tables that have many columns).
But that's not all, having all values of the same column stored together often shows a high degree of repeatability. For low cardinality columns (columns that have a small number of unique values, like for example a country column which will most likely have like 200 unique values), values will be repeated a lot which something that compression algorithms love.
There are many compression techniques that can make use of this, for example, bitmap encoding:

In bitmap encoding, a column with \(n\) distinct values can be turned into \(n\) separate bitmaps; one bitmap for each distinct value, with one bit for each row. The bit is 1 if the row has that value, and 0 if not.
If \(n\) is very small (like in the country example we discussed earlier), those bitmaps can be stored with one bit per row. But if \(n\) is bigger, there will be a lot of zeros in most of the bitmaps (we say that they are sparse). In that case, the bitmaps can additionally be run-length encoded, as shown at the bottom of previous diagram. This can make the encoding of a column remarkably compact.
To simplify this idea, let's just assume that we will compress columns in a run-length encoding fashion based on how many times a specific value is repeated instead of writing all repetitions, so for example if a column file has the following values:
country: Egypt, England, USA, USA, USA, France, Egypt, England, England
It will be compressed as follows:
country: (Egypt, 1), (England, 1), (USA, 3), (France, 1), (Egypt, 1), (England, 2)
As we can see, instead of for example writing the value USA 3 times, it was represented by 1 entry that shows the number of its repetitions.
In addition to that, column based databases have a very nice opportunity they can exploit to make compression even better. As we mentioned before, compression algorithms love patterns and repetitions, so what if we order the column values? This is should introduce more repetitions, for example, the ordered column file would like this:
country: Egypt, Egypt, England, England, England, France, USA, USA, USA
So now when this is compressed, it will look like so:
country: (Egypt, 2), (England, 3), (USA, 3), (France, 1)
As we can see now, a value like Egypt was not compressed at all before sorting, but now it is, also a value like England had 2 runs, now all the runs are subsequent allowing for a better compression.
Bear in mind that as we mentioned before, values of all columns have to be sorted in the same order, so the \(n_th\) value of some column \(col_1\) and the \(n_th\) value of some other column \(col_2\) belong together in the same row. So when we choose to order the table by a given subset of columns, all other columns follow the same order, for example, if we have another column called name along our country column:
| country | Egypt | England | USA | USA | USA | France | Egypt | England | England |
|---------|-------|---------|-----|-----|-----|--------|-------|---------|---------|
| name | B | A | A | C | D | Z | A | B | A |
And we order the table by country, name, it will look like this:
| country | Egypt | Egypt | England | England | England | France | USA | USA | USA |
|---------|-------|-------|---------|---------|---------|--------|-----|-----|-----|
| name | A | B | A | A | B | Z | A | C | D |
As we can see, the first column in the sort order made the most use of compression because values will be repeated much better, but the second column is essentially random except when some natural repetitions occur, later columns in the sort order might not get any compression at all. It's the job of the database administrator to choose columns to order the table based on.
Note that sort orders also heavily affect the query speed (pretty much like indexing in row based databases), so some queries might require different sort orders, which is a thing in columnar databases where developers duplicate the same data but sorted differently to serve a variety of query patterns.
Memory Bandwidth and Vectorized Processing
For data warehouse queries that need to scan over millions of rows, a big bottleneck is the bandwidth for getting data from disk into memory. However, that is not the only bottleneck. Developers of analytical databases also worry about efficiently using the bandwidth from main memory into the CPU cache, avoiding branch mispredictions and bubbles in the CPU instruction processing pipeline (bubbles means stalls, it means that the CPU is not doing anything for this instruction during this CPU cycle).
As discussed in the previous section, because columnar databases store column values in a file, they can be compressed better which comes with the added benefit of being able to operate on small datasets that can fit in the CPU's L1 cache which allows some operations needed during processing to operate on larger chunks of data which is called vectorized processing.
Writing to Column-Oriented Storage
The many optimizations we discussed earlier, specially sorting columns, would complicate writing to columnar databases, because writing values in a sorted column will require re-writing the entire column. But as we explored in the previous article, some data structures like LSM-trees have a solution for that where all writes first go to an in-memory store, where they are added to a sorted structure and prepared for writing to disk. It doesn’t matter whether the in-memory store is row-oriented or column-oriented. When enough writes have accumulated, they are merged with the column files on disk and written to new files in bulk (usually in the background). So inserting in LSM-trees is actually pretty fast because it all boils down to an append to the tree structure.
Aggregation: Materialized Views
Another aspect of data warehouses that is worth mentioning briefly is materialized
aggregates. As discussed earlier, data warehouse queries often involve an aggregate function, such as COUNT , SUM , AVG , MIN , or MAX in SQL. If the same aggregates are used by many different queries, it can be wasteful to crunch through the raw data every time. Why not cache some of the counts or sums that queries use most often?
Materialized views are quire similar to virtual views in that they are a transformation defined by some query, but they differ in the sense that in virtual views, just the query is cached and expanded by the database during execution to original DDL, but materialized views also cache the result of running the query as well on a physical table that can be later queried to fetch precomputed data which is very efficient in serving queries. A nice trick that developers do as well, is to create different materialized views on top of the same table but ordered differently to also serve different query patterns.
Summary
In this article we explored the difference between row-based and column-based databases and discussed how storing data in a columns format helps OLAP databases to compress data, vectorize the computations, speed up search and precompute common queries.