

A while ago, I published two articles discussing facebook's storage infrastructure. The first article discussed facebook's hot storage system called Haystack which at the time was used for both hot and warm storage. Then in the second article, I discussed facebook's f4 which was designed to exclusively serve warm storage.
The previous article explained how facebook optimized their storage infrastructure by managing BLOB life cycle, which basically how they move BLOBs from the more expensive and fast hot storage system to a more storage optimized warm storage system.
But as we can see, this left facebook with a constellation of small storage systems that they had to maintain and operate. It also introduced some resources waste. In this article, we will discuss how facebook built a single file system to rule them all!
Introduction
Prior to Tectonic, facebook’s storage infrastructure consisted of a constellation of smaller, specialized storage systems. Blob storage was spread across Haystack and f4 while data warehouse was spread across many HDFS instances.
The constellation approach was operationally complex, requiring many different systems to be developed, optimized and managed. It was also inefficient, stranding resources in the specialized storage systems that could have been reallocated for other parts of the storage workload.
The main idea behind Tectonic is to have a single, multi-tenant storage system that all applications at facebook can use. This is useful because:
- It simplifies operations as it's a single system to develop, optimize and manage.
- It's resource-efficient because it allows resources sharing between multiple-tenant within the same storage cluster.
Tectonic's efficient can be reasoned about using the following example, for instance, Haystack was the storage system specialized for new blobs; it bottlenecked on hard disk IO per second (IOPS) but had spare disk capacity. f4, which stored older blobs, bottlenecked on disk capacity but had spare IO capacity. Tectonic requires fewer disks to support the same workloads through consolidation and resource sharing.
Design Goals
In building Tectonic, facebook had to deal with 3 main challenges and handle them as design goals. The challenges are:
- Scaling to exascale: Tectonic had to be able to store exabytes of data and be flexible to scale to store even more data.
- Providing performance isolation between tenants: Tectonic had to be able to provide the needed storage capacity and latency requirement for each tenant in complete isolation from other tenants in the cluster.
- Enabling tenant specific optimizations: Tectonic had to be able to be flexible enough to enable tenants to customize their storage to match the performance of specialized systems.
At the end of this article, we will come back to evaluate how Tectonic achieved each of these 3 design goals.
Facebook’s Previous Storage Infrastructure
Now let's take a quick look at the facebook's storage infrastructure that existed before Tectonic was introduced to be able to better understanding its positioning and value. I highly recommend checking my previous articles on this (they will be included in the same article series).
The two main data storage needs at facebook are:
- BLOB storage.
- Data warehousing.
Each of those two use cases had a completely different storage infrastructure to suite its needs best.
1. BLOB Storage
Before Tectonic, blob storage consisted of two specialized systems, Haystack and f4. Haystack handled hot blobs with a high access frequency. It stored data in replicated form for durability and fast reads and writes. As Haystack blobs aged and were accessed less frequently, they were moved to f4, the warm blob storage. f4 stored data in RS-encoded form which is more space-efficient but has lower throughput because each blob is directly accessible from two disks instead of three in Haystack. f4’s lower throughput was acceptable because of its lower request rate.
However, separating hot and warm blobs resulted in poor resource utilization, a problem exacerbated by hardware and blob storage usage trends. Haystack’s ideal effective replication factor was \(3.6\) (i.e., each logical byte is replicated \(3\), with an additional \(1.2\) overhead for RAID-6 storage). However, because IOPS per hard drive has remained steady as drive density has increased, IOPS per terabyte of storage capacity has declined over time.
As a result, Haystack became IOPS-bound; extra hard drives had to be provisioned to handle the high IOPS load of hot blobs. The spare disk capacity resulted in Haystack’s effective replication factor increasing to \(5.3\). In contrast, f4 had an effective replication factor of \(2.8\) (using \(RS(10,4)\) encoding in two different datacenters). Furthermore, blob storage usage shifted to more ephemeral media that was stored in Haystack but deleted before moving to f4 (think facebook stories for instance). As a result, an increasing share of the total blob data was stored at Haystack’s high effective replication factor.
So the clear problem here is that Haystack is over-provisioned in terms of disk capacity just to be able to handle the needed IOPS and f4 is over-provisioned in terms of IOPS just to be able to handle the needed disk capacity. We can see that if somehow Haystack and f4 were to be merged in a single system, Haystack will be able to make use of f4's extra IOPS and f4 will be able to make use of Haystack's extra disk capacity. And this is exactly what facebook were trying to do when they built Tectonic.
Check Haystack and f4 for more details.
2. Data Warehousing
Data warehouse provides storage for data analytics. Data warehouse applications store objects like massive map-reduce tables, snapshots of the social graph, and AI training data and models.
Data warehouse storage prioritizes read and write throughput over latency, since data warehouse applications often batch-process data. Data warehouse workloads tend to issue larger reads and writes than blob storage.
Before Tectonic, data warehouse used the Hadoop Distributed File System (HDFS). However, HDFS clusters are limited in size because they use a single machine to store and serve metadata. As a result, we needed tens of HDFS clusters per datacenter to store analytics data. This was operationally inefficient; every service had to be aware of data placement and movement among clusters.
Having multiple HDFS clusters each with limited capacity and throughput introduced a two dimensional bin-packing problem. The packing of datasets into clusters had to respect each cluster’s capacity constraints and available throughput which complicated operations even more.
The main problem here is that HDFS clusters are relatively small and can't scale to fit large datasets. So if Tectonic were to be able to handle this scale, it will eliminate those operational complexities.
Architecture and Implementation
In this section we will discuss the overall architecture of Tectonic and some of its implementation details.
Tectonic: A Bird’s-Eye View
A cluster is the top-level Tectonic deployment unit. Tectonic clusters are datacenter-local, providing durable storage that is resilient to host, rack, and power domain failures. Tenants can build geo-replication on top of Tectonic for protection against datacenter failures.
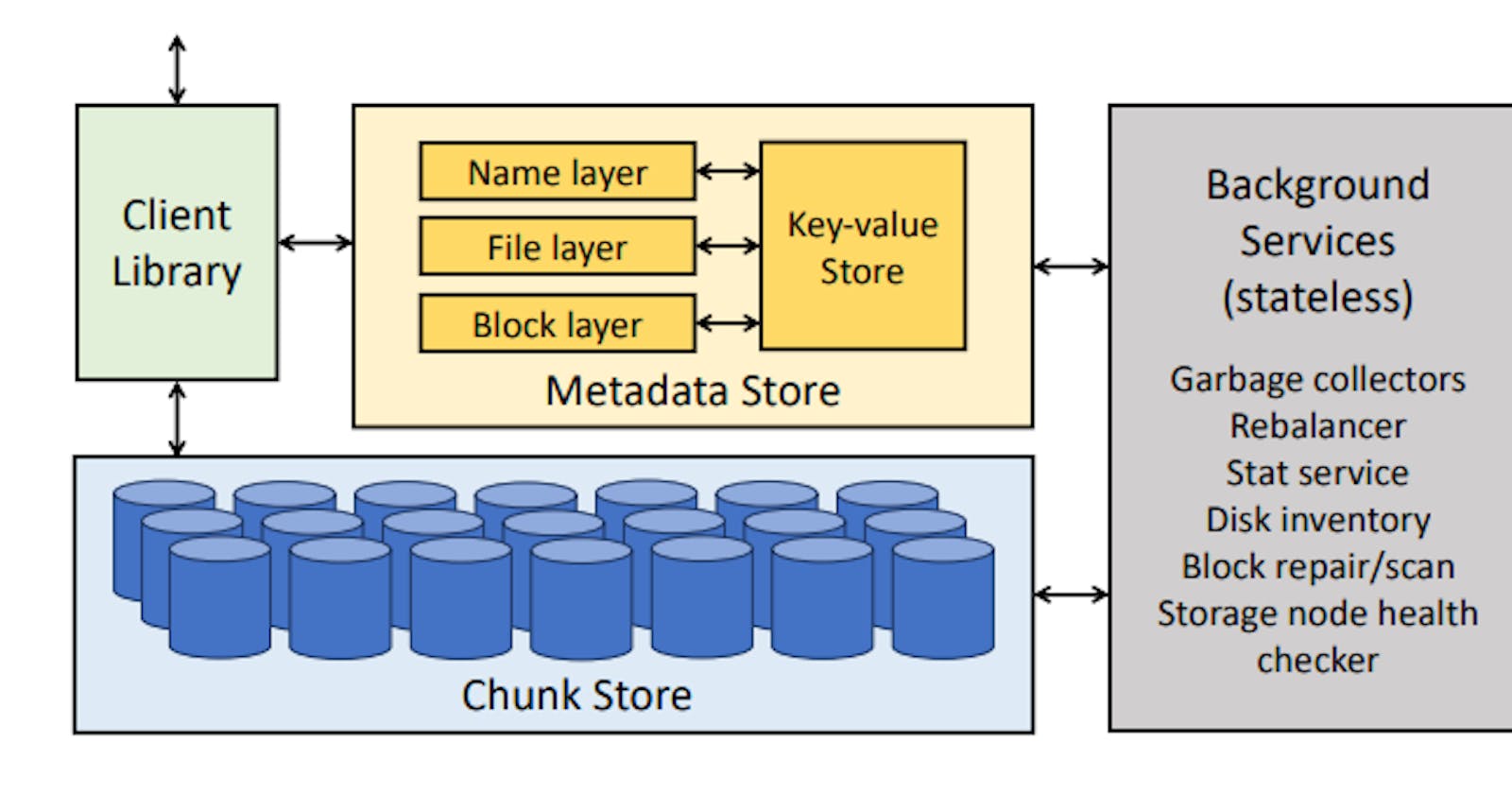
A Tectonic cluster is made up of storage nodes, metadata nodes, and stateless nodes for background operations. The Client Library orchestrates remote procedure calls to the metadata and storage nodes. Tectonic clusters can be very large: a single cluster can serve the storage needs of all tenants in a single datacenter.
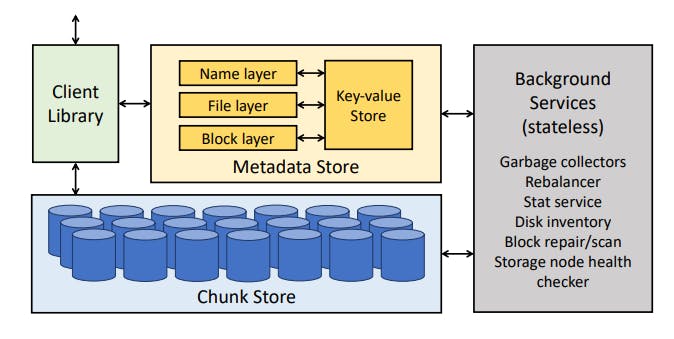
Tectonic clusters are multitenant, supporting around ten tenants. Tenants are distributed systems that will never share data with one another; tenants include blob storage and data warehouse. These tenants in turn serve hundreds of applications, including Newsfeed, Search, Ads, and internal services, each with varying traffic patterns and performance requirements.
Now let's take a deep dive into each of the components in the previous diagram.
1. Chunk Store: Exabyte-Scale Storage
The foundation of a Tectonic cluster is the Chunk Store, a fleet of storage nodes which store and access data chunks on hard drives. The Chunk Store is a flat, distributed object store for chunks, the unit of data storage in Tectonic. Chunks make up blocks, which in turn make up Tectonic files.
The Chunk Store has two features that contribute to Tectonic’s scalability and ability to support multiple tenants:
- The Chunk Store is flat; the number of chunks stored grows linearly with the number of storage nodes. As a result, the Chunk Store can scale to store exabytes of data.
- The Chunk Store is oblivious to higher-level abstractions like blocks or files; these abstractions are constructed by the Client Library using the Metadata Store. This separation simplifies the problem of supporting good performance for a diversity of tenants on one storage cluster because it means reading to and writing from storage nodes can be specialized to tenants’ performance needs without changing filesystem management.
Individual chunks are stored as files on a cluster’s storage nodes which each run a local instance of XFS (XFS is a high-performance 64-bit open source filesystem merged into the Linux kernel). Storage nodes expose core IO APIs to get, put, append to and delete chunks, along with APIs for listing chunks and scanning chunks.
Each storage node has 36 hard drives for storing chunks. Each node also has a \(1TB\) SSD, used for storing XFS metadata and caching hot chunks.
In Tectonic, blocks are a logical unit that hides the complexity of raw data storage and durability from the upper layers of the filesystem. To the upper layers, a block is an array of bytes. In reality, blocks are composed of chunks which together provide block durability. Tectonic provides per-block durability to allow tenants to tune the tradeoff between storage capacity, fault tolerance, and performance. Blocks are either Reed-Solomon encoded or replicated for durability.
2. Metadata Store: Naming Exabytes of Data
Tectonic’s Metadata Store stores the filesystem hierarchy and the mapping of blocks to chunks. The Metadata Store uses a fine-grained partitioning of filesystem metadata for operational simplicity and scalability. Filesystem metadata is first disaggregated, meaning the naming, file, and block layers are logically separated. Each layer is then hash partitioned which helps avoiding hot spots.
Tectonic delegates filesystem metadata storage to ZippyDB, a linearizable, fault tolerant, sharded key-value store. The key-value store manages data at the shard granularity: all operations are scoped to a shard and shards are the unit of replication.

The previous table highlights the principle of disaggregating the metadata layers. As we can see we have the following metadata layers:
- The Name layer: maps each directory to its sub-directories and/or files.
- The File layer: maps file objects to a list of blocks.
- The Block layer: maps each block to a list of chunk locations on disk.
- The Block layer: contains the reverse index of disks to the blocks whose chunks are stored on that disk which is used for maintenance operations.
Name, File, and Block layers are hash-partitioned by directory, file and block IDs, respectively.
In a filesystem, directory operations often cause hotspots in metadata stores. Tectonic’s layered metadata approach naturally avoids hot spots in directories and other layers by separating searching and listing directory contents (Name layer) from reading actual file data (File and Block layers).
3. Client Library
The Tectonic Client Library orchestrates the Chunk and Metadata Store services to expose a filesystem abstraction to applications, which gives applications per-operation control over how to configure reads and writes.
The Client Library deals with tectonic underlying storage at the finest possible level with the chunk level, this results in extreme flexibility when it comes to executing reads and writes and thus the Client Library is able to execute those operations in the most performant way possible from the point of view of each tenant.
The Client Library replicates or RS-encodes data and writes chunks directly to the Chunk Store. It reads and reconstructs chunks from the Chunk Store for the application. The Client Library consults the Metadata Store to locate chunks and updates the Metadata Store for filesystem operations.
The Client Library uses single-writer semantics to avoid the complexity of serializing writes. This means that a single file can be written to from a single writer. If a specific tenant needs multi-writer semantics, it can still use Tectonic but it will have to build its own write serialization logic on top of Tectonic.
4. Background Services
Background services maintain consistency between metadata layers, maintain durability by repairing lost data, rebalance data across storage nodes, handle rack failures and publish statistics about filesystem usage.
Background services are layered similar to the Metadata Store, and they operate on one shard at a time. There a few very important background services such as:
- A garbage collector: between each metadata layer cleans up metadata inconsistencies which can result from failed multi-step client operations or from lazy deletion which marks deleted objects as deleted without actually deleted them as a time optimization.
- A rebalancer: identifies chunks that need to be moved in response to events like hardware failure, added storage capacity, etc.
- A repair service: handles the actual data movement by reconciling the chunk list to the disk-to-block map for every disk in the system.
Evaluation of Design Goals
In the Design Goals section we mentioned Tectonic main 3 design goals which are:
- Scaling to exascale.
- Performance isolation among tenants.
- Enabling tenant-specific optimizations.
In this section, we will take a look at how Tectonic achieved each one of these goals.
1. Scaling to Exascale
Scaling to Exascale means to be able to store exabytes of data which is a 2-challenge problem:
Problem:
Is being able to have enough disk space to store that much data and have an easy mechanism via which the capacity of the storage system can be horizontally increased without any service disruption.
Solution:
We can see that Tectonic solved this problem by offering the ability to scale the storage layer in the Chunk Store layer because Data Nodes can be added to the storage cluster easily and because of having the chunk as a unit of storage which abstracted away the details of the underlying storage.
Problem:
Having exabytes of data also means that the system will have to handle an absurd amount of metadata. It will have to be able to locate where each piece of data is stored on disk from the most abstracted data path (a directory/file name for example).
Solution:
We can see that Tectonic solves this problem by disaggregating the metadata layer into independently-scalable layers by via hash partitioning which effectively load balances metadata operations. For example, in the Name layer, the immediate directory listing of a single directory is always stored in a single shard. But listings of two subdirectories of the same directory will likely be on separate shards. In the Block layer, block locator information is hashed among shards, independent of the blocks’ directory or file. Around two-thirds of metadata operations in Tectonic are served by the Block layer, but hash partitioning ensures this traffic is evenly distributed among Block layer shards.
The metadata layer is also optimized via caching sealed object metadata because metadata shards have limited available throughput, so to reduce read load, Tectonic allows blocks, files, and directories to be sealed which prevents adding objects in the immediate level of the directory. The contents of sealed filesystem objects cannot change; their metadata can be cached at metadata nodes and at clients without compromising consistency with some exceptions (such as the blocks placement because it can change on rebalancing, failure recovery, adding additional storage, etc.).
2. Performance Isolation among Tenants
Problem:
Providing comparable performance for tenants as they move from individual, specialized storage systems to a consolidated filesystem presents a challenge as , tenants must share resources while giving each tenant its fair share, i.e., at least the same resources it would have in a single-tenant system. In particular, Tectonic needs to provide approximate (weighted) fair sharing of resources among tenants and performance isolation between tenants, while elastically shifting resources among applications to maintain high resource utilization. Tectonic also needs to distinguish latency-sensitive requests to avoid blocking them behind large requests.
Solution:
As we can see Tectonic solved this problem by categorizing tenants into Traffic Groups which is a more finer categorization than tenants, yet more coarse than single applications within each tenant. A Traffic Group represents a group of applications which have similar resource and latency requirements. For example, one Traffic Group may be for applications generating background traffic while another is for applications generating production traffic. Tectonic supports around 50 Traffic Groups per cluster. Each tenant may have a different number of Traffic Groups. Tenants are responsible for choosing the appropriate Traffic Group for each of their applications.
Each Traffic Group is in turn assigned a Traffic Class. A Traffic Group’s Traffic Class indicates its latency requirements and decides which requests should get spare resources. The Traffic Classes are Gold, Silver, and Bronze, corresponding to latency-sensitive, normal, and background applications. Spare resources are distributed according to Traffic Class priority within a tenant.
Tectonic uses tenants and Traffic Groups along with the notion of Traffic Class to ensure isolation and high resource utilization. That is, tenants are allocated their fair share of resources; within each tenant, resources are distributed by Traffic Group and Traffic Class.
3. Enabling Tenant-Specific Optimizations
Problem:
Before Tectonic, as we mention before, there were a few specialized storage systems such as, Haystack, f4 and Hadoop. Each of these systems was used for specific applications and each was custom tailored to the needs of each application. For example, Haystack used replication to improve latency while f4 used RS encoding to improve storage while compromising performance.
Having a consolidated storage system would naturally end up being very generic which might degrade performance for some applications which was not acceptable while designing Tectonic. This why Tectonic as to be flexible enough to allow each tenant to customize storage based on its storage-latency needs.
Solution:
We can see that Tectonic solves this problem as it supports around ten tenants in the same shared filesystem, each with specific performance needs and workload characteristics. This is mainly achieved by giving clients nearly full control over how to configure an application’s interactions with Tectonic; the Client Library manipulates data at the chunk level, the finest possible granularity.
To understand this better, let's take 2 examples of client-specific optimizations that are currently in facebook's production:
- Data warehouse write optimizations: A common pattern in data warehouse workloads is to write data once that will be read many times later so those types of applications prioritize a lower write file time. And so Tectonic uses the write-once-read-many pattern to improve IO and network efficiency, while minimizing total file write time. Because files are only read after the are completely written (no partial reads), this allows Tectonic to buffer writes to block size and RS encode data into the buffer before flushing to disks. This saves network bandwidth, disk space and eventually write time. This is fully controlled by the Client Library.
- Blob storage optimizations: Blob storage is on path for many user requests, so low latency is desirable. This why hot BLOB are written non-encoded to faster to fetch and because they are usually small (smaller than Tectonic blocks) it acceptable to write them non-encoded at first. Re-encoding BLOBs takes place with warm BLOBs later during the BLOB lifecycle.
Conclusion
This paper presents Tectonic, Facebook’s distributed filesystem. A single Tectonic instance can support all Facebook’s major storage tenants in a datacenter, enabling better resource utilization and less operational complexity. Tectonic’s hash-sharded disaggregated metadata and flat data chunk storage allow it to address and store exabytes. Its cardinality-reduced resource management via Traffic Groups and Classes allows it to efficiently and fairly share resources and distribute surplus resources for high utilization. Tectonic’s client-driven tenant-specific optimizations allow it to match or exceed the performance of the previous specialized storage systems.
Resources
Consolidating Facebook storage infrastructure with Tectonic file system