
Finding a Needle in a Haystack: How Facebook Serves Millions of Images per Second


So a couple of weeks ago, I came across a file system called SeaweedFS which is according to their readme:
... is a distributed storage system for blobs, objects, files, and data lake, to store and serve billions of files fast! Blob store has O(1) disk seek ...
And it looked very interesting. Turns out, as mentioned in the readme, that SeaweedFS is actually originally based on storage systems designed by facebook such as, Haystack, f4 and the new Tectonic storage system.
So I started reading the design paper published facebook in 2010 (very old but still relevant) detailing the design of the Haystack storage system and I found it really interesting in the sense that it addresses real-world file system concerns in the largest social networking platform in the world and provides fairly simple solutions that are very effective yet easy to reason about, implement and maintain.
The paper starts by an overview of the problem facebook were trying to solve, a discussion of the system they had in place before Haystack and its drawbacks, then it goes into the detailed design of the new system and it concludes by an evaluation of the new system and how it meets their design objectives.
Introduction
As we might all have guessed, sharing photos is probably the most popular feature on facebook whether they're profile pictures, photos in the timeline or photo albums uploaded by billions of users around the globe. At the time the paper was published, in 2010, facebook users have uploaded over 65 billion photos, and for usability reasons, facebook generates 4 images for each uploaded photo of difference sizes (thumbnail, small, medium and large) accumulating into over 260 billion images and more than 20 petabytes of data. Users upload one billion new photos (∼60 terabytes) each week and facebook serves over one million images per second at peak. Remember that all these numbers are 10 years ago, so you can only imagine how those numbers are now in 2021!
The Existent System
Facebook used to depend an NFS (Networked File System) that's mainly comprised of NAS (Network Accessed Storage) appliances to implement their storage system. An NFS is a system that allows disk storage to be mounted and accessed by remote machines as if they were directly attached to those machines via RPCs (Remote Procedure Calls). A NAS appliance is simply a disk that's accessed via a network rather than being physically attached to a machine.
Those storage appliances are all POSIX complaint so you can think of them as your traditional UNIX file systems. This storage system also uses a CDN (Content Delivery Network) affront that's used to cache the most frequently requested images which should improve read latency for this type of requests.
The Main Idea
An interesting fact about photos on a social networking platform is they are written once, never modified and rarely deleted. This is reasonable since we can model photo edits such as, rotations or filters as new photos.
In traditional POSIX based file systems, everything is modeled as a file and every file has its associated metadata such as permissions which is basically unused for such a system and thus resulting in a considerable waste of space (a few bytes per image multiplied by billions and billions of stored images).
We can understand that the useless metadata would waste space, but disk space is not really an issue. The real issue here surfaces when an image is read from disk. When an image is read from disk in a POSIX based file system, the following takes place:
- One (typically more) disk operations is made to translate the filename into an inode number. An inode is like a file serial number for the file that contains information about that file such as, file type, permissions, UID, GID, etc.
- One disk operation to fetch the inode from disk.
- A final disk operation to fetch the file itself from disk.
We can easily see that we have wasted 2 (or more) disk operations just reading the metadata of a file. So it follows that if we can have that metadata in main memory, it can be read very quickly compared to reading it from disk. But the problem is that having all metadata of all stored files in the system in main memory in impractical due to the size of the metadata multiplied by the massive number of files stored on the system.
Haystack Design Goals
Given the disadvantages of the previously described system, Haystack was designed to serve 4 main goals:
- High throughput and low latency: The storage system has to maintain a high throughput of serving images back to clients. High throughput is needed because requests exceeding the system's capacity are either dropped which is bad for user experience or have to be handled by a CDN which is not very cost effective.
- Fault-tolerant: As any large scale distributed systems, failures happen and they are inevitable, so Haystack has to maintain a high level of fault tolerance and availability with a zero downtime.
- Cost-effective: The current NFS based system they had was very costly, so Haystack had to do better but at a much lower cost. The paper defines cost based on two dimensions: Haystack’s cost per terabyte of usable storage and Haystack’s read rate normalized for each terabyte of usable storage.
- Simplicity: In production environments, having a simple system that's easy to implement and maintain is quite crucial to its success, so Haystack had to be simple enough to implement in a few months rather than a few years and because of the lack of its production system, it had to be straight-forward, easy to fix and maintain (because it's expected that it will evolve a lot after using it in production for a while).
Background and Previous Design
As we mentioned in the previous sections, facebook employed a CDN based system on top of an NFS based storage. Now let's take a look on how CDN based systems usually work.
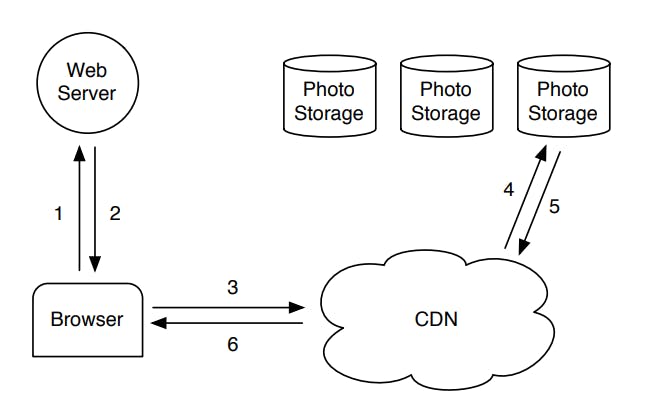
As we can from the figure above, a request to fetch an image (or any file basically) life cycle in a CDN based system is as follows:
- The browsers issues an HTTP request to fetch the needed image to the backend web server.
- The backend server uses the application logic to fetch the URL at which the image can be found and sends it back to the browser. The URL has embedded information about the CDN and any other needed info by the storage system.
- The browser sends an HTTP request to the CDN using the URL sent back from the web server.
- The CDN inspects its cache for the needed file and immediately serves it back to the browser in case of a cache hit (the image is in the CDN cache). But in case of a cache miss in the CDN, it will have to communicate with the storage system to fetch the needed image and caches it in the CDN.
- The CDN then finally responds back to the browser with the requested image.
It's easy to see that the CDN approach would only for the most recently requested content. In the context of facebook, that would be profile pictures or recently uploaded images. But facebook also generates a considerable amount of traffic on far less popular content (old images) which they call the long-tail. Logically, requests for the long-tail would result in a cache miss in the CDN and will hit the storage system resulting in a high read traffic. They will also expire from the CDN very quickly as more hot content is cached, so they will almost always have to be served by the storage system.
The photo storage component highlighted in the previous diagram was implemented by facebook as an NFS based system as follows:
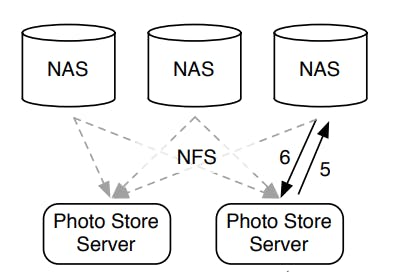
As we can see from the previous diagram, the storage system is basically a collection of NAS appliances that are connected as an NFS. Each image is stored in its own file, so directories can contain millions of files which led to an excessive number of disk operations in order to read just a single file.
Given the concern about the high read traffic generated for old content which will have to be served by the storage system and not the CDN, it's clear that a system that needs to perform many disk operations to fetch a single image will not scale at all.
Haystack Design and Implementation
By now we can see that the CDN approach is still very effective as it shoulders the burden of serving frequently accessed and newly uploaded content. It also alleviates that load from the storage system so that it can serve the long-tail requests (those that would miss the cache in the CDN). And thus using a CDN is still used in conjugation with Haystack.
Now let's take a look on how Haystack implements a storage system that would be effective enough in handling the large traffic of long-tail requests.
As we discussed before, the main throughput bottleneck in the old NFS system was the disk operations fan-out (4 more disk operations per file read) which was mainly wasted on fetching file metadata. And we agreed that loading all metadata in main memory would eliminate those disk operations but was impractical due to its size and the large number of files stored. So the main idea is to minimize the per file metadata so that it can be efficiently loaded in main memory.
Haystack uses a straight-forward approach: it stores multiple photos in a single file and therefore maintains very large files. Note that the metadata is a per-file expense, so having very large as opposed to many small files will reduce the overall size of metadata, thus achieving the goal of being able to loaded it all in main memory.
At this point, it's very important to note that Haystack has 2 different types of metadata:
- Application metadata: describes the information needed to construct a URL that a browser can use to retrieve a photo.
- File system metadata: identifies the data necessary for a host to retrieve the photos that reside on that host’s disk.
Overview
The Haystack architecture consists of 3 core components: the Haystack Store, Haystack Directory and the Haystack Cache.
Let's briefly describe each component before going into details:
- The Haystack Store is responsible for encapsulating the persistent storage file system for images and is the only component that handles file system metadata. The Store's capacity is organized by physical volumes, for example, a 10 terabytes of capacity is organized into 100 physical volumes each of which provides 100 gigabytes of storage. Physical volumes are grouped into logical volumes so when an image is to be stored, it's replicated to all physical volumes in the same logical volume. This redundancy allows to mitigate data loss due to hard drive failures, disk controller bugs, etc.
- The Haystack Directory maintains the mapping between logical volumes and their corresponding physical volumes along with other application metadata, such as the logical volume where each image is stored and the logical volumes with free storage space.
- The Haystack Cache which functions as an internal CDN, which protects the Haystack Store from requests for the most popular images and provides insulation if upstream CDN nodes fail and need to refetch content (commonly known as a cache stampede).
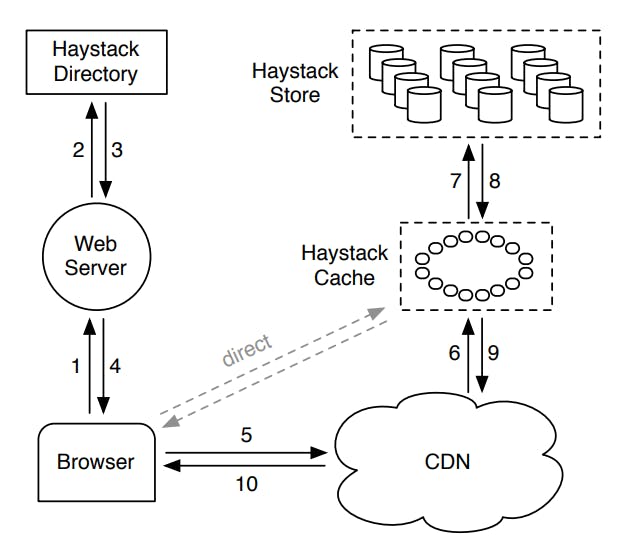
The previous figure shows how all 3 components interact to serve traffic (both the hot traffic and the long tail traffic) as follows:
- The browser sends an HTTP request to the backend web server to fetch the image.
- The backend server communicates with the Haystack directory to fetch a URL for the requested image.
- The Haystack directory looks up its application metadata and fetches the URL for the requested image and sends it back to the backend server. Remember that the directory is what is storing where each file is stored.
- The backend server responds back to the browser with the image URL.
- The browser either requests the image from the CDN or directly for the Haystack cache based on the provided information in the returned URL (we will discuss this later).
- The CDN looks up the image in its cache and serves it back in case of a cache hit, but in case of a cache miss, it fallsback to the Haystack Cache.
- The Haystack cache looksup the image in its ache and serves it back to the CDN in case of a cache hit, but in case of a cache miss, it fallsback to the Haystack Store.
- The fetched image is returned from the Haystack Store back to the Haystack Cache where it gets cached (or not based on some logic to be discussed later).
- The Haystack Cache returns the image back to the CDN.
- The CDN caches the image and returns it back to the browser.
Now let's take a look at the URL generated by the Haystack Directory, it generally looks like so:
https://<CDN>/<Cache>/<Machine id>/<Logical volume, photo>
The first part of the URL specifies from which CDN to request the photo. The CDN can lookup the photo internally using only the last part of the URL: the logical volume and the photo id. If the CDN cannot locate the photo then it strips the CDN address from the URL and contacts the Cache. The Cache does a similar lookup to find the photo and, on a miss, strips the Cache address from the URL and requests the photo from the specified Store machine. On the other hand, requests that go directly to the Cache have a similar workflow except that the URL is missing the CDN specific information.
Now let's take a deeper dive in each of the 3 components and understand their design.
The Haystack Directory
The Directory is designed to perform four functions as follows:
- Store the mapping between logical and physical volumes which is used to generate URLs for images when requested.
- Act as a load balancer to balance the write/read load on different Store machines.
- Determines whether an image should be read from the CDN or directly from the Haystack Cache which controls the system's dependence on external CDNs.
- Identifies those volumes marked as read-only either because of operational reasons or because they have reached their disk capacity.
The Directory should route write traffic to write-enabled machines only but it can route read traffic to both write-enabled or read-only machines. It's a fairly simple component that stores its information in a replicated database accessed via an API.
The Haystack Cache
The Cache receives HTTP requests for photos from CDNs and also directly from browsers. The Cache is organized as a distributed hash table that uses the photo id as the key to locate cached data. If a Cache lookup ended in a miss, then the it fetches the image from the Store machine identified in the URL and replies back to either the CDN or the browser as appropriate.
When there is a Cache miss and the Cache fetches the image from the Store, it has to decide whether to cache that image in its internal cache or not. The Haystack Cache caches an images only if:
- The request is coming directly from a browser and not the CDN. This makes sense because if a request is coming from a CDN, it means that it missed the CDN cache, so it's unlikely that it will hit in the Haystack Cache and thus no need to cache it.
- The image is returned from a write enabled machine. This is a little bit indirect to understand, newly uploaded images will be routed to write-enabled machines and those images are very likely to be read in the near future which means that this read traffic would hit the write-enabled machines which saturates its resources. So it's better to avoid routing those reads to the write enabled machines and serve them from the Cache instead. The Haystack Cache has a hit rate of \(80\%\).
The Haystack Store
The Store machines receives read requests from the Haystack Cache and they can quickly find an image using only the id of the corresponding logical volume and the file offset at which the photo resides. This knowledge is the keystone of the Haystack design: retrieving the filename, offset and size for a particular photo without needing disk operations.
A Store machine manages a group of physical volumes, we can think of each physical volume as a very large file where multiple images are stored in the same file at different offsets. Each physical volume consists of a superblock followed by a sequence of needles. Each needle represents a photo stored in Haystack (pun intended, probably).
To retrieve needles quickly, each Store machine maintains an in-memory data structure for each of its volumes that looks like so:
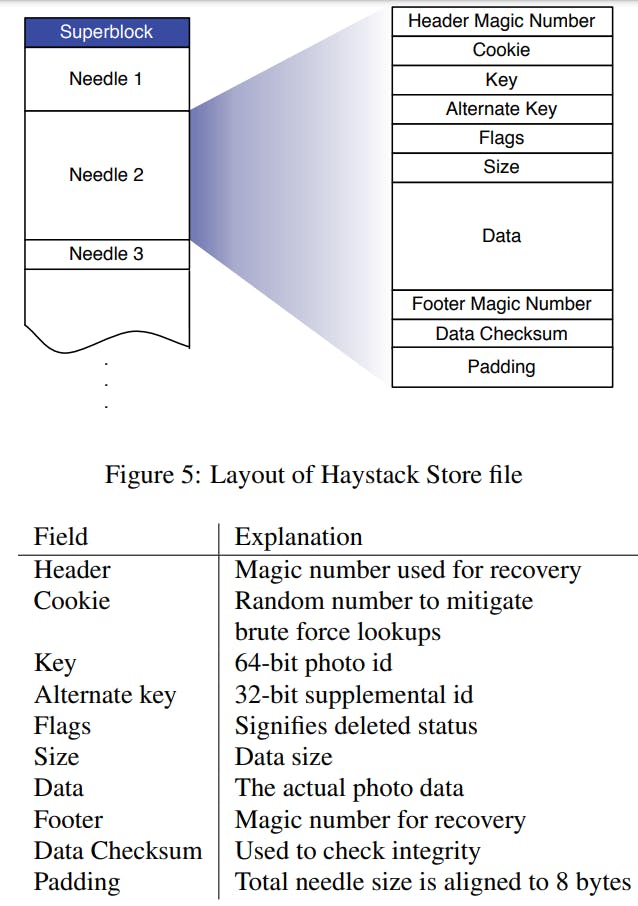
But a Store machine receives more than just read requests as it also serves write and rarely delete requests. So let's take a look at how each of those requests is handled by the Haystack Store:
- Photo Read: When a Cache machine requests a photo it supplies the logical volume id, key, alternate key and cookie to the Store machine it looks up the relevant metadata in its in-memory mappings. If the photo has not been deleted the Store machine seeks to the appropriate offset in the volume file, reads the entire needle from disk and validates its integrity using the checksum.
- Photo Write: When uploading a photo into Haystack web servers provide the logical volume id, key, alternate key, cookie and data to Store machines. Each machine synchronously appends needle images to its physical volume files and updates in-memory mappings as needed. Note that there are no update requests, so any edits done to an image are essentially new images but using the same key and alternate key and Haystack can distinguish them by their differing offsets (the image with the highest offset is the most recent version).
- Photo Delete: Deleting a photo is straight-forward. A Store machine sets the delete flag in both the in-memory mapping and synchronously in the volume file. Note that the space that was occupied by the now deleted image is not yet reclaimed by the system as it's later reclaimed asynchronously by a compaction process that copies the data into a new file and removes the old file.
Crash Recovery
Store machines use an important optimization (the index file) when rebooting. While in theory a machine can reconstruct its in-memory mappings by reading all of its physical volumes, doing so is time consuming as the amount of data (terabytes worth) has to all be read from disk. Index files allow a Store machine to build its in-memory mappings quickly, effectively shortening restart time.
For performance reasons, Haystack doesn't update the index file synchronously with writes and deletes to have them complete faster and instead does so asynchronously which complicates the crash recovery process because when the system crashes and reads the index file, it could actually be looking a stall state of the system that it's missing some writes and deletes. So on reading the index file, Haystack knows reads all physical volumes after the last offset in the index file (those files are new) and updates their mapping data in the index file which solves the problem of missing writes. As for the missing deletes, after a Store machine reads the entire needle for a photo, that machine can then inspect the deleted flag in the image itself. If a needle is marked as deleted the Store machine updates its in-memory mapping accordingly and notifies the Cache that the object was not found.
Evaluation
Going back to the four design goals we mentioned, let's see if Haystack actually achieved them:
- High throughput and low latency: Haystack achieved high throughput and low latency by requiring at most one disk operation per read which is made possible by minimizing the metadata size and loading it in main memory. Based on benchmarks done in the paper, it's also able to achieve \(~4x\) more normalized reads rate per second per terabyte of usable storage.
- Fault-tolerant: Haystack achieved fault tolerance by replicating each image to 3 geographically distinct locations. This replication guarantees that when a host is down, it can be replaced by another host during its repair and maintains a zero downtime.
- Cost-effective: Haystack achieved cost effectiveness on both of the dimensions we mentioned as each usable terabyte costs \(∼28\%\) less and processes \(∼4x\) more reads per second than an equivalent terabyte on a NAS appliance.
- Simplicity: Haystack achieved simplicity by employing mostly straight forward approaches to solving problems which made it faster to develop and easier to operate and maintain.
Conclusion
This paper describes Haystack, an object storage system designed for Facebook’s Photos application. Haystack is designed to serve the long tail of requests seen by sharing photos in a large social network. The key insight is to avoid disk operations when accessing metadata. Haystack provides a fault-tolerant and simple solution to photo storage at dramatically less cost and higher throughput than a traditional approach using NAS appliances.