
Designing Data Intensive Applications: Ch.7 Transactions (weak isolation levels)


In the previous article, we introduced database transactions, went over their main use cases and discussed what type of guarantees they entail under the ACID definition. And then we discussed the characteristics of ACID transactions such as atomicity, consistency, isolation and durability.
In this article, we will discuss some weak isolation levels that are utilized by many databases to implement concurrency control as opposed to enforcing total serializability which usually comes with a major performance penalty. We will mainly discuss read-committed and snapshot isolation levels and then discuss with detailed examples how they handle concurrency anomalies like dirty reads, dirty writes, inconsistent reads, write skew and phantoms writes.
Weak isolation levels
If two transactions don't operate on the same data set, then they can be run in parallel without any issues. Issues however start to arise when two transactions overlap in terms of the data set on which they simultaneously operate. This is generally known as race conditions.
Concurrency bugs are hard to find by testing, because those bugs are only triggered when you get unlucky with the timing. This may happen very rarely, and is usually difficult to reproduce. That's why databases try as much as possible to hide concurrency handling from applications developers to make their lives easier. They do that via something called transaction isolation. In theory, this should make your life easier by letting you pretend that no concurrency is happening: serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially, i.e. one at a time, without any concurrency.
But as we discussed in the previous article, serializable isolation has a very cost when it comes to performance which many application developers choose not to pay. So databases offer other types of isolation mechanisms that are weaker than serializable but don't incur such a high performance impact.
Those weaker isolation are actually more complex to understand when compared to something as straightforward as serializable and they can lead to subtle bugs that you have to be aware of when using those isolation levels, but nonetheless, they are a lot more used in practice due to their overall usefulness and low performance impact.
In this article, we will look at several weak (non-serializable) isolation levels that are used in practice, and discuss in detail what kinds of race conditions can and can't occur, so that you can decide what is appropriate to your application.
Read committed
The most basic level of transaction isolation is read committed. It makes two guarantees:
When reading from the database, you will only read data that has been committed, this is known as "no dirty reads".
When writing to the database, you will only overwrite data that has been committed, this is conversely known as "no dirty writes".
Now let's discuss each of these two guarantees in detail.
No dirty reads
A dirty read is what happens when a transaction is allowed to read a value written by another transaction before that transaction commits. Basically, it's allowing a transaction to see intermediate changes in the database, or a partially updated state of the database so to speak.
This can cause a ton of problems, they mainly arise from:
If a transaction is updating multiple objects, for example, inserting a record into the database while updating a counter in some other table. If other transactions are allowed to read the newly inserted record without guarantees that the the rest of the transaction committed (i.e. the counter might still not be updated yet), this cause issues with transactions making wrong decisions. For example, if this was an email inbox app, this will be showing an extra new email but the email counter will still be old.
If a transaction aborts after partially writing some values, if other transactions where allowed to read the partially written values before that transaction commits, it will be as if those transactions read data that never existed in the database in the first. For example, if a transaction to add money to a user account aborted but another transaction to use the account to purchase some goods did a dirty read and got the user balance before the original transaction aborts, then this user would be allowed to use credit that was never granted in the first place.
If we think about the 2 previous points thoroughly, we will be able to find out a ton of examples where dirty reads can be nothing short of catastrophic.
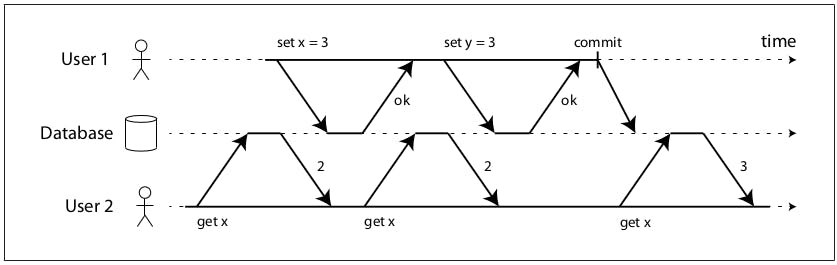
The previous diagram shows how a database prevents dirty reads, let's assume the value of x was 2 and then user 1 tries to set x to 3, when user 2 reads the value x, multiple times, before user 1 commits, it's still getting the old value which is 2, even though user 1 changed it to 3 as part of the transaction, but user 2 will only be able to get the new value if and only if user 1 commits (note that if user 1 aborts, it will never get the new value and it will keep getting the old value 2).
No dirty writes
A dirty write is what happens when a transaction is allowed to overwrite a value written by another transaction that hasn't committed yet. Transactions running at read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted.
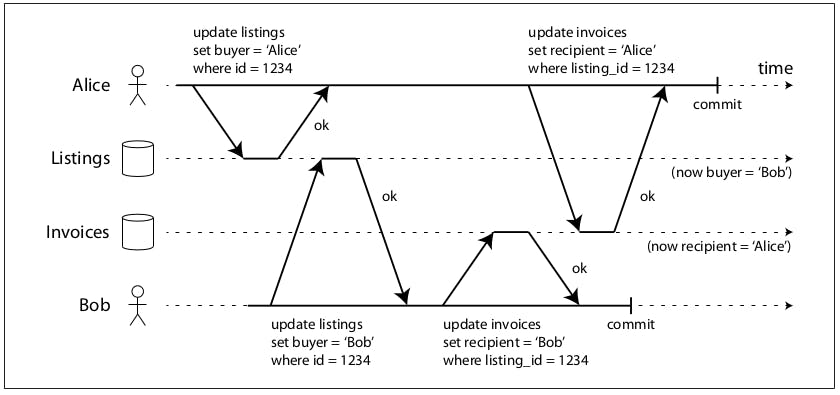
To understand better, let's take a look at the previous diagram, it mimics a car dealership website where users buy cars. Buying a car entails 2 database operations, one to update the car listing and another one to send an invoice to the buyer. In this example, a transaction to update the buyer for Alice was written, but another concurrent transaction to update the buyer for Bob was allowed to overwrite the partially written value, so now the buy was changed to Bob. Similarly, an invoice to be sent to Bob was written but was allowed to be overwritten by the other transaction, so now the invoice will be sent to Alice while Bob is the buyer.
This is the kind of mishap a read committed isolation level can help prevent. The correct behavior here is that second transaction fired by Bob should not be allowed to overwrite the values written by the first transaction fired by Alice until it commits or aborts, in which case, Alice will be the buyer and the invoice recipient.
Implementing read committed
Most commonly, databases prevent dirty writes by implementing row locks that writing transactions has to acquire and hold on to during the writing process. This effectively prevents any other transactions from overwriting those rows/documents being written by the transaction which is holding the needed row(s) locks. When the transaction commits or abort, those locks are released and then other transactions can acquire that lock and write new values.
As for dirty reads, they can also be prevented by using the same locking mechanism, so when a transaction wants to read a value, it has to acquire a lock briefly and releases it after it's done reading. This guarantees it will not read uncommitted values because if it was allowed to read the row, that means it has successfully acquired the lock which means it wasn't held by any other transactions including the one that wrote that value.
However, the approach of requiring read locks does not work well in practice, because one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed. So many databases implement a mechanism in which it will remember the current and the previous value of a specific row and it will keep serving the old value as long as the current transaction didn't complete yet, if it does eventually commits or aborts, then it will start serving the new value. This enables many read-only transactions to run concurrently without having to compete for locks (this is a minified version of what happens with snapshot Isolation).
Snapshot isolation and repeatable read
Overall, read committed seems that it's already preventing some mishaps but there are other problems that could still happen with read-committed isolation level.
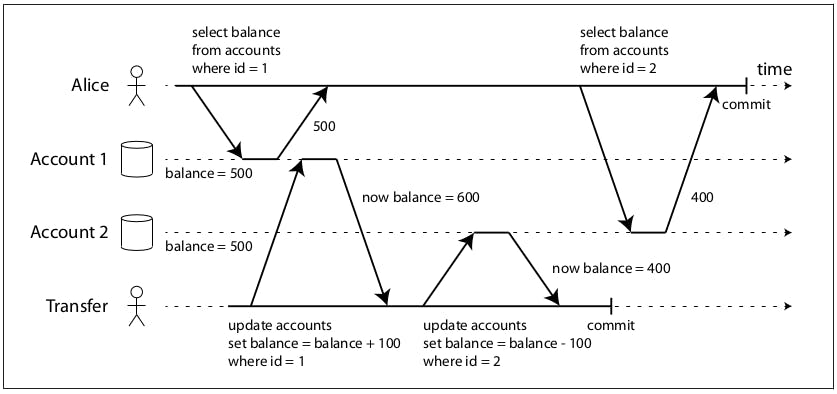
For example, the previous diagram, Alice has a $1000 split over 2 accounts and a transaction is being made to transfer a $100 from one account to another. What happens here is Alice reads the value of account 1 and she gets $500 and then the transaction performing the transfer completes and then Alice reads the value of account 2 and she gets $400, so it seem as though $100 has disappeared.
We first need to understand why a read-committed isolation level wouldn't prevent this. A read-committed isolation level would make sure that if a read was performed within the transaction bounds it wouldn't read uncommitted values. But in this case, the reads are performed outside the transaction boundaries (one read is before and another is after), so as far as read-committed isolation goes, those are not dirty reads.
It's very likely however that if Alice refreshes the page, it will read the correct values (400 and 600). But for some applications and some use cases, even a temporary inconsistency like this can be very damaging, for example:
During backups, a snapshot of the database has to be taken while other writes are still being performed, if the snapshot contained some old data and some new data, it will basically be corrupt once restored because those temporary inconsistencies will now be permanent.
In some use cases where analytics queries or data integrity queries are being run, those inconsistencies can cause false alerts or return nonsensical results.
Snapshot isolation, also known as multi-version concurrency control (MVCC), is the most common solution to this problem. The idea is that each transaction reads from a consistent snapshot of the database, that is, all the data that was committed in the database at a particular point in time. Even if the data is subsequently changed by another transaction, each transaction sees the old data from the time when that transaction started.
Snapshot isolation is perfect for long running queries like taking backups, but it's also very good for all sorts of queries, it's a lot easier to reason about because when the data a transaction is working with keeps on changing during the transaction run time, it just complicates things, but if the transaction is operating on a stable snapshot of the database, it makes everything a whole lot easier.
Implementing snapshot isolation
Snapshot isolation handles writes using locks pretty much like read-committed which means that a transaction that makes a write can block the progress of another transaction that writes to the same object.
For reads, it follows a similar but more general methodology to read-committed in the sense that locks are not required for reads. From a performance point of view, a key principle of snapshot isolation is readers never block writers, and writers never block readers. This allows a database to handle long-running read queries on a consistent snapshot at the same time as processing writes normally, without any lock contention between the two. So far it's quite similar to read-committed, but the difference is that read-committed needs to maintain at most 2 versions of the same object, the committed value and the yet-to-be committed value, but in snapshot isolation the database might actually need to maintain several versions of the same object in the database representing how it's changing by different transactions, that's why snapshot isolation enables consistent snapshot reads and that's why it's usually referred to as multi-version concurrency control.
Systems implementing snapshot isolation usually do the following:
For each transaction fired against the database, a transaction id (
txid) is assigned which is monotonically increasing which helps identify order of transactions.Writes made by a transaction are written to the database as a new snapshot of the current state. So for example if we insert a new record, a new snapshot for this object is created with the current values and it usually contains some metadata such as which transaction created it and whether it was deleted or not and by whom.
Updates to existing records are translated as marking older snapshots for deletion and creating a new snapshot with the updated value.
Deletions are not performed right away, we only just mark snapshots for deletion and a garbage collection process deletes those snapshots only if there are no other transactions are accessing them.
Since every transaction has available several snapshots of the same object, database define visibility rules to tell the database which snapshots are visible which are ignored, it goes as follows:
At the start of each transaction, the database makes a list of all the other transactions which are in progress (not yet committed or aborted) at that time. Any writes made by one of those transactions are ignored, even if the transaction subsequently commits.
Any writes made by aborted transactions are ignored.
Any writes made by transactions with a later transaction ID (i.e. which started after the current transaction started) are ignored, regardless of whether that transaction has committed.
All other writes are visible to the application’s queries.
Let's take a more detailed example to understand how snapshot isolation works.
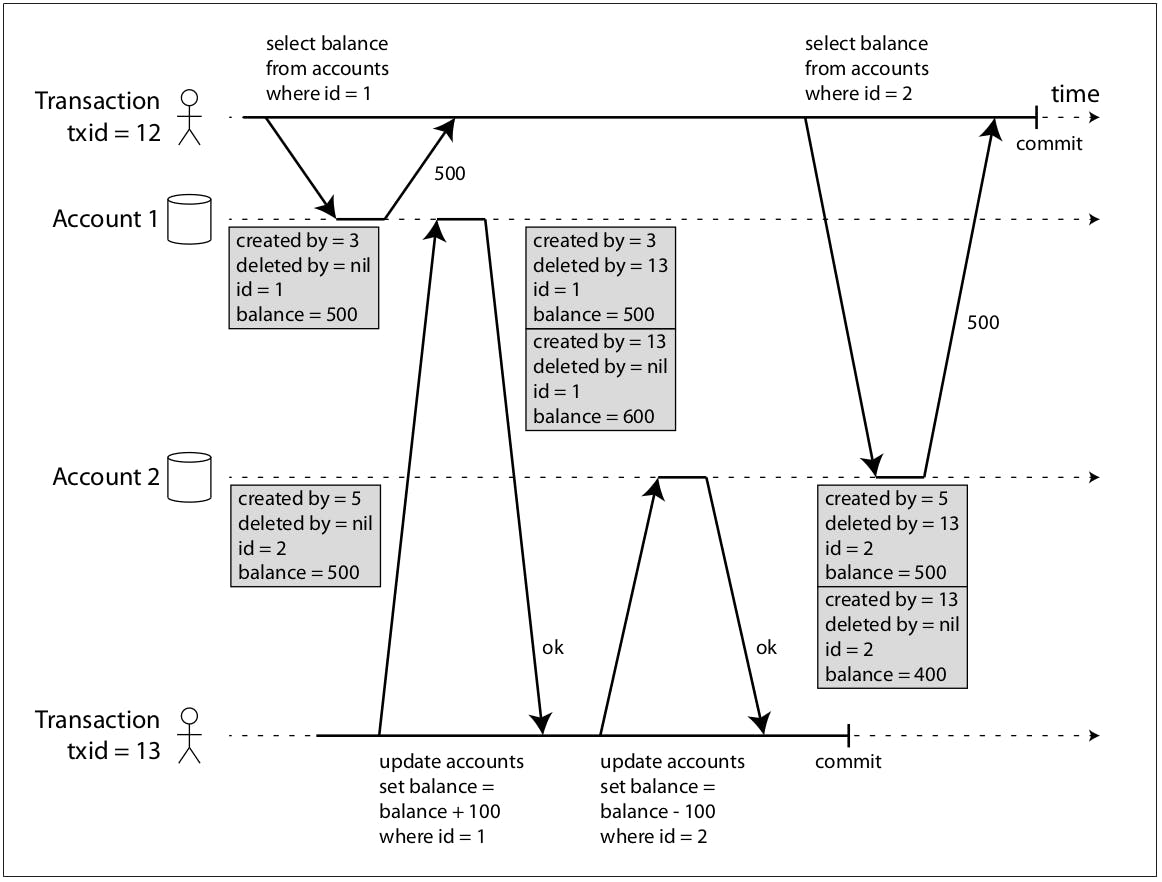
In the previous diagram, we have two accounts with ids 1 and 2 and we have two transactions with txid 12 and 13 and both transactions are updating the same set of records. What happens is the following:
We start with account 1 with balance equals $500 and it was created by a previous transaction with 3 and it wasn't deleted so far. And account 2 with balance equals to $500 as well and it was created by transaction with id 5 and it's also hasn't been deleted so far.
Transaction 12 fires a read query against account 1. In that time, there are no concurrently running transactions, so the snapshot created by transaction 3 is visible for transaction 12 and thus it reads the value $500.
Transaction 13 fires an update query to increase the balance of account 1 by $100, this is translated as marking the snapshot created by transaction 3 of account 1 for deletion by transaction 13 and creating a new snapshot by transaction 13 with the new updated value $600.
As part of the same transaction, transaction 13 fires another update to decrease the balance of account 2 by $100 to complete the transfer operation, and similarly, this is translated as marking the snapshot created by transaction 5 of account 2 for deletion by transaction 13 and creating a new snapshot by transaction 13 with the new updated value $400. And transactions 2 commits.
Now the interesting part, transaction 12 fires a read query to fetch the balance of account 2, but because transaction 12 has a smaller transaction id than transaction 13, any snapshots created by transaction 13 (basically any modifications done by transaction 13, whether deletes or inserts) are ignored, so transaction 12 can only see the snapshot created by transaction 5 which has the balance value equals $500 which is the same value as when transaction 12 first began before transaction 13 alters it. So, we can say that transaction 12 was successfully able to operate on a consistent snapshot of the database regardless of what other concurrent transactions may have been running. And this is what sets snapshot isolation apart from read-committed, because read-committed would have fetched the new value ($400) since transaction 13 has already committed, because in its definition it's not a dirty write.
Indexes and snapshot isolation
How do indexes work in a multi-version database? One option is to have the index simply point to all versions of an object, and an index query needs to filter out any object versions that are not visible to the current transaction. When garbage collection removes old object versions that are no longer visible to any transaction, the corresponding index entries can also be removed.
Another approach is append-only/copy-on-write indexes where every write transaction (or batch of transactions) creates a new B-tree root, and a particular root is a consistent snapshot of the database at the point in time when it was created. There is no need to filter out objects based on transaction IDs because subsequent writes cannot modify an existing B-tree, only create new tree roots. However, this approach also requires a background process for compaction and garbage collection.
Preventing lost updates
Read committed and snapshot isolation, as discussed so far, have been primarily about the guarantees of what a read-only transaction can see in the presence of concurrent writes. But there are some issues that might happen during concurrent writes are not handled by any of the isolation levels we discussed so far.
The easiest example to reason about is lost updates. This happens when we have 2 transactions concurrently writing the same object in read-modify-write cycle. For example, if each transaction reads a value, modifies it in some way and then writes it back to the database. If both transactions read before either of them commits its modifications, then later on when the transactions commit, the transaction that commits last will miss whatever updates done by the transaction that committed first.
Some examples the might require a read-modify-write cycle from the applications are:
Updating a counter value or an account balance.
Making a local change to a complex value, e.g. adding an element to a list within a JSON document.
Two users editing a wiki page at the same time, where each user saves their changes by sending the entire page contents to the server, overwriting whatever is currently in the database.
So for example if we have a JSON column with the following structure:
{
"name": "john doe",
"hobbies": ["swimming", "playing music"]
}
and one transaction is updating the hobbies list to add "programming" and another transaction is updating the hobbies list to add "cooking". What could happen if the 2 transactions ran concurrently, is that both both transactions will read the current JSON and transaction one will modify it look like so:
{
"name": "john doe",
"hobbies": ["swimming", "playing music", "programming"]
}
while transaction 2 will modify it like so:
{
"name": "john doe",
"hobbies": ["swimming", "playing music", "cooking"]
}
then let's assume that transaction 2 commits first and then transaction 1 commits, so the final result will be:
{
"name": "john doe",
"hobbies": ["swimming", "playing music", "programming"]
}
instead of:
{
"name": "john doe",
"hobbies": ["swimming", "playing music", "programming", "cooking"]
}
and thus the write of transaction 2 got lost.
Usually the solution for such problems is to either:
Eliminate the read-modify-write cycle by using atomic operations, for example if we are incrementing a counter value, we can use an atomic operation to increment instead of reading, adding 1 and writing the incremented value. What this does is acquire an exclusive lock during the increment process which doesn't allow other transactions to read the value before the incrementing is done. For example:
UPDATE counters SET value = value + 1 WHERE key = 'foo';
Some databases support a similar type of atomic operations called compare-and-set where an update is allowed to only happen if the value has not changed since you last read it. If the value has changed, then the update is not executed and thus has no effect, for example:
UPDATE wiki_pages SET content = 'new content' WHERE id = 1234 AND content = 'old content';
Explicit locking which is an attractive option specially if the read-modify-write cycle can't be replaced by an atomic operation either because it's way too complex or not supported in the database we are using. The lock allows the application to perform a read-modify-write cycle, and if any other transaction tries to concurrently read the same object, it is forced to wait until the first read-modify-write cycle has completed. For example:
BEGIN TRANSACTION; SELECT * FROM figures WHERE name = 'robot' AND game_id = 222 FOR UPDATE; -- this acquires an exclusive lock on the list of rows -- Do some logic UPDATE figures SET position = 'c4' WHERE id = 1234; COMMIT;
Same approach 2 but do it on the application level instead of the DB level (for example via using distributing locks in redis or something similar).
Automatically detecting lost updates
Atomic operations and locks are ways of preventing lost updates by forcing the read- modify-write cycles to happen sequentially. An alternative is to allow them to execute in parallel, and if the transaction manager detects that a lost update occurred, the transaction is aborted and must retry its read-modify-write cycle.
Lost update detection is a great feature, because it doesn’t require application code to use any special database features, for example, you may forget to use a lock or an atomic operation and thus introduce a bug, but lost update detection happens automatically and is thus less error-prone.
It's important to note that automatic lost updates detection is not available in MySQL's innodb which is one of the most commonly used engines in the industry. And in some definitions, a database has to prevent lost updates to qualify for snapshot isolation.
Things get way more complicated when the database is replicated, specially if it's a multi-leader replication. To learn more, refer back to conflict resolution in replicated systems here.
Preventing write skew and phantoms
In the previous sections we saw dirty writes and lost updates, two kinds of race conditions that can occur when different transactions concurrently try to write to the same objects. However, that is not yet the end of the list of potential race conditions that can occur between concurrent writes. In this section we will see some more subtle examples of conflicts.
To begin, imagine this example: you are writing an application for doctors to manage their on-call shifts at a hospital. The hospital usually tries to have several doctors on call at any one time, but it absolutely must have at least one doctor on call. And doctors are allowed to take themselves off-call if they are out sick or something provided that at least one doctor remains on-call at all times, otherwise the operation should fail.
Now imagine that Alice and Bob are the two doctors on-call for a particular shift. Both are feeling unwell, so they both decide to request leave. Unfortunately, they happen to click the button to go off-call at approximately the same time.
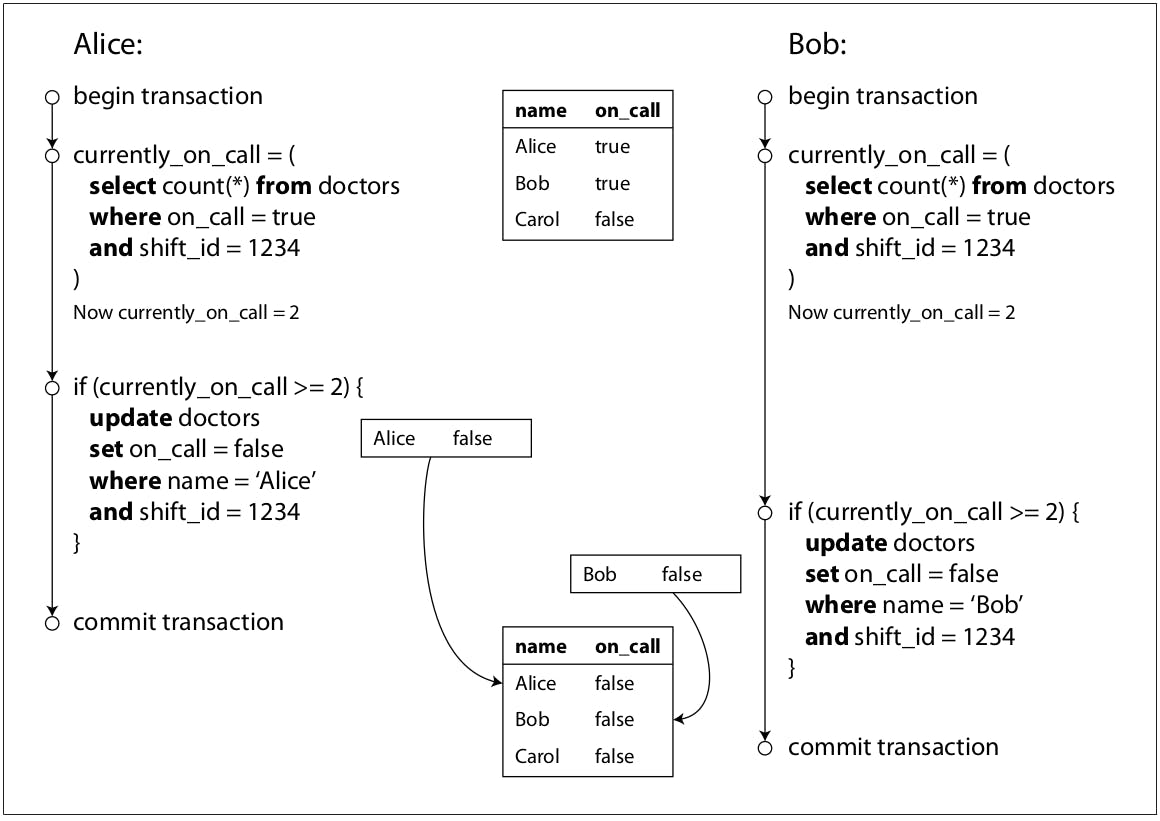
The previous diagram explains what happens:
Alice reads the current list of on-call doctors and she gets 2, so she decides that it's okay to take herself off-call and fires an update to switch her on-call status to false.
Bob also does the same read against the on-call table and because we are using snapshot isolation, writes done by Alice are still not visible to Bob, so he also reads the value 2 and proceeds to take himself off-call leaving no one on-call which violates the rules of the system.
Write skew
This anomaly is called write skew, it's neither a dirty write nor a lost update, because the two transactions are updating two different objects (Alice and Bob’s on-call record, respectively). You can think of write skew as a generalization of lost update. Write skew can occur if two transactions read the same objects, and then update some of those objects (different transactions may update different objects). In the special case where different transactions update the same object, you get a dirty write or lost update anomaly (depending on the timing).
We saw that there are various different ways of preventing lost updates. With write skew, our options are more restricted:
Atomic single-object operations don’t help, because multiple objects are involved.
The automatic detection of lost updates can't help either because multiple objects are involved and to be able to achieve this you will have to be using serializable isolation which might not be applicable for most applications.
Some databases allow you to configure constraints, which are then enforced by the database (e.g. uniqueness, foreign key constraints or restrictions on a particular value), but for the example shown here that doesn't help either, but you maybe able to use a trigger to materialized view to achieve this but in a very hacky manner.
The only viable option here is explicit locking either on the database or the application level as illustrated above.
There are many examples for applications that might be susceptible to write anomalies like write skew, such as booking systems, claiming a username, preventing double spending in financial systems, etc.
Phantoms
One example that's also more interesting is for example if we have a system where users choose their username and we can't have 2 users with the same username, so the application checks if the username doesn't exist and only if that's true grants the user this username. An anomaly that could happen here is:
Transaction 1 queries the database for users with the submitted username (to check if any exists), let's assume it returned an empty set.
Transaction 2 does the same and gets an empty set and proceeds to insert a user with the submitted username and commits.
Transaction 1 will insert a new user with the username thus violating the system rules.
This seems like a normal example, but the trick here is that this time we are checking the absence of a record (different than the doctor example where we checked the existence of records) and the anomaly here is that one transaction inserted an object matching the search condition of another transaction. This is called a phantom write, snapshot isolation avoids phantoms in read-only queries, but in read-write transactions like the examples we discussed, phantoms can lead to particularly tricky cases of write skew.
The trick in handling phantoms of this sort is that even if we use database locks while reading (the FOR UPDATE statement), if the query returns an empty set, it doesn't actually lock anything because there are no objects to which the database should attach the locks, so this solution doesn't work here. But fortunately, in this particular use case a unique constraints on the username records will simply solve this issue, but other use-cases might not be as lucky.
Materializing conflicts
If the problem of phantoms is that there is no object to which we can attach the locks, perhaps we can artificially introduce a lock object into the database?
Let's say for example that we have a meeting room booking system and the rule is not different bookings can overlap in the same meeting room. If we implement this system similar to the username claiming system, it will suffer from phantom writes and a unique constraints might not be easy to implement here.
One solution is to create a new table of all time slots available (say in 30 mins increments) for some period of time, for example, for the next 6 months. Then now when we perform the booking operation, we can select with an exclusive lock on this table the time slots we wish to book and if we manage to select them, then we perform the rest of the booking logic.
Note that the additional table isn’t used to store information about the booking, it’s purely a collection of locks which is used to prevent bookings on the same room and time range from being modified concurrently. This approach is called materializing conflicts, because it takes a phantom and turns it into a lock conflict on a concrete set of rows that exist in the database.
But as we can probably guess, this type of modeling is not always easy to do, for example, it has to deal with a discrete (somewhat) range, like what we did by splitting time into 30 mins increments, but if the range is more continuous, like for example, if the increment is a millisecond, that wouldn't be feasible. It also leaks concurrency handling logic to the application which complicates it a bit and makes it more error-prone but it is not always bad in my opinion because sometimes only a few parts of the application can benefit from something like that while the rest can work normally under concurrent workloads and changes like using serializable isolation would affect the entire database and thus slow down the entire application unnecessarily. One has to be careful with their choices here though.
Summary
In the article, we introduced some alternatives to using serializable isolation to achieve ACID properties. We mainly discussed weaker isolation levels like read-committed and snapshot isolation and learned how they compare. We also discussed how those isolation levels handle concurrency anomalies like dirty-reads, dirty-writes, inconsistent reads, write skew and phantom writes.