
Designing Data Intensive Applications: Ch.7 Transactions (intro to ACID transactions)


In the previous few articles, we discussed the concept of partitioning and learned how it can be utilized by to scale out data intensive applications.
In this article, we will start a new chapter where we will introduce an important concept in databases which is transactions, go over their use cases, discuss what type of safety guarantees they provide under the ACID definition. We will also discuss the meaning of transactional properties such as atomicity, consistency, isolation and durability.
The need for transactions
In any production system, lots of things can go wrong which can create very complex failure modes and error handling, some of the things that can go wrong in a data system are:
The database software or hardware may fail at any time (including in the middle of a write operation).
The application may crash at any time (including halfway through a series of operations).
Interruptions in the network can unexpectedly cut off the application from the database, or one database node from another.
Several clients may write to the database concurrently, overwriting each others’ changes.
Race conditions between clients can cause surprising bugs.
These types of failures can cause catastrophic results if not handled properly. The thing is that error handling is a lot of work, so transactions were introduced to try to make it easier and more convenient.
For decades, transactions have been the mechanism of choice for simplifying these issues. A transaction is a way for an application to group several reads and writes together into a logical unit. Conceptually, all the reads and writes in a transaction are executed as one operation: either the entire transaction succeeds (commit) or it fails (abort, rollback). If it fails, the application can safely retry. This makes error handling much simpler for an application, because it doesn’t need to worry about partial failure, i.e. the case where some operations succeed and some fail.
It's very important to note however, that transactional logic comes at a cost, it increases contention in the application and generally slows it down a bit. Ditching transactions can have very positive effects on the application's performance. So it's important to understand that transactions are not always the answer and that application developers have to really think if they do need transactions or other failure handling methods can be applied at a much lower cost.
To be able to tell if you need transactions or not, you need to understand what kind of safety guarantees transactions provide in he first place and what are the costs associated with them and then you can make informed decisions regarding the use of transactional logic in your application. So let's delve right in.
The slippery concept of a transaction
Almost all relational databases and even some non-relational ones have some definition for transactions. Most of them follow the system-R definition of a transaction. Quite recently, in the early 2000s, non-relational databases started to grain popularity and they started trying to redefine transactions by loosening some guarantees to make them more efficient or make them suitable for distributed setups or even drop them entirely.
This move started branding transactions as the type of guarantees needed for "serious applications" with "valuable data". If you ask anyone for an example of transactions, they will probably mention something related to banking!
The truth is not that simple: like every other technical design choice, transactions have advantages and limitations. In order to unpack those trade-offs, let’s go into the details of the guarantees that transactions can provide — both in normal operation, and in various extreme (but realistic) circumstances.
The meaning of ACID
The safety guarantees provided by transactions are often described by the well-known acronym ACID, which stands for Atomicity, Consistency, Isolation and Durability. However, in practice, one database’s implementation of ACID does not equal another’s implementation.
So let’s dig into the definitions of atomicity, consistency, isolation and durability, as this will let us refine our idea of transactions.
Atomicity
The term atomic is somewhat overloaded in computer science to refer to multiple things, albeit, similar. For example, in the context of multi-threading, if an operation is atomic, that means that while a thread is performing this operation, another thread can't see the intermediate state during performing said operation, it can only see the state before or after the operation was completed. In that context, it's used to refer to some sort of concurrency control between threads.
In the context of ACID, it refers more to the abortability of transactions. For example, if a transactions contains multiple write operations that need to be executed as a single unit, if those operations are to be a part of an ACID transactions, atomicty in this context refers to the fact that if a single write fails, the whole transaction will be aborted. This is an intrinsic property in transactions and basically it's what's giving it its advantage when it comes to simplified error handling because now the application need not worry about partially committed transactions.
Consistency
The term consistency is no different in the sense that's also very overloaded in computer science. It has a wide range of usage to describe a bunch of stuff, for example:
In replicated systems, consistency describes when replicas are consistent in the sense that they have the same state (for example, in asynchronous replication).
In the CAP theorem, consistency refers to linearizability.
In ACID context, it refers to the database being in a good state (consistent state so to speak). The thing here is that the definition of consistency in this context is somewhat loose and not dependent on the database itself, rather it's more dependent on a set of invariants put in place by the application itself. For example, in a banking application, the consistency invariants might be something like that all debtor and creditors are balanced. But the database itself can't guarantee this, it's up to the application, albeit that some guarantees can be actually handled by the database, like for example, enforcing data integrity guarantees like foreign key guarantees or unique value guarantees, etc. But at the end of the day, if you write bad data in the database, it will not do any effort to prevent you (of course if it doesn't violate the integrity rules you might have defined, but those are some what very basic).
Isolation
Isolation refers to the database ability of handling race conditions when the same set of records are accessed by multiple transactions concurrently. For example, in the following diagram:
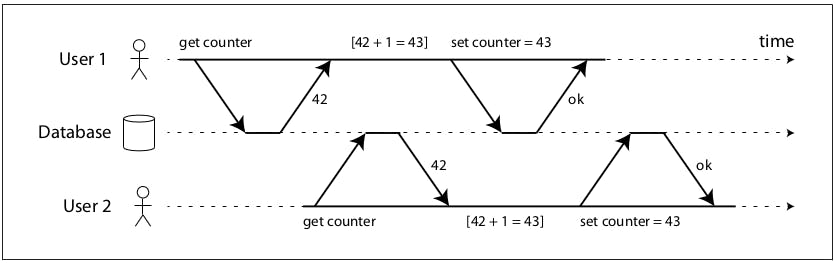
We can see 2 clients trying to increment a counter in the database by fetching the counter value, adding 1 and then writing the newly incremented value (assuming no single increment operation exists). The counter starts at 42, but instead of going to 44 because it got incremented twice, it's going instead to 43 due to a race condition resulting from the fact that both clients got the same value before the other client commits their incremented value.
Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other: they cannot step on each others’ toes. This context is usually formalized as serializability, which means that even though transactions were executed concurrently, they will appear as if they were executed serially (one at a time).
It's worth mentioning that serializability is rarely used because of its very bad performance implications, that's why many databases don't even bother implementing this kind of isolation level and some others changed the definition to mean something else, like for example referring to snapshot isolation as serialization (which is a weaker isolation level).
Durability
Durability is probably the easiest part of ACID to understand. In layman terms, it means that once the database confirms receiving data, it will never be lost (under defined operating conditions).
In replicated systems, this definition might differ a little bit to include having replicated received data to the write quorum nodes as well as the node that first received those writes.
Most systems guarantee durability by utilizing some sort of a write-ahead log which enables the system to commit data faster and be able to replay the WAL to recover from database crashes.
Summary
In this chapter, we introduced the concept of transactions and discussed some of the usecases where transactions can be useful and what type of safety guarantees they can provide. We mainly discussed the properties of ACID transactions and the meaning of atomicity, consistency, isolation and durability.
In the next article, we will go over database isolation levels and see how do they compare.