
Designing Data Intensive Applications: Ch5. Replication (Part 2: Problems with Replication Lag)


In the previous article we started discussing part 2 of Data Intensive Applications and we talked about single leader-based replication, how it works and it handles failures in leaders and replicas. We also discussed different methods for replication, such as statement and row based replication, WAL replication and trigger-based replication. We have also touched upon how we can use those replication techniques beyond conventional uses and introduced how replication can be useful for performing zero-downtime maintenance and online schema migrations.
In this article we will discuss some side effects of replicated systems, mainly related to the problems introduced by replication lag and we will try to enforce some consistency guarantees, like for example, being able to read your own writes, being able to serve monotonic and consistent prefix reads. Then we will move on to discuss some solutions for replication lag in modern database systems.
Problems with Replication
As we discussed in the previous article, replication doesn't only help with increasing availability (tolerating node failures), it's also very useful to scale the system for reads and to reduce latency via geographical replication.
A very common pattern in web system is read-scaling architectures in which there is a single writer and many replicas spread out over multiple geographical sites to be closest as possible to end users. This type of system is meant to support as many reads as possible. In such architecture it wouldn't make sense to use a fully synchronous system because we have many nodes and any node failure will just cause the entire system to be unresponsive (which has a high likelihood since we have more nodes). So in this type of architecture, a semi-synchronous or completely asynchronous replication is often used in order to be able to tolerate node failures.
Unfortunately, if an application reads from an asynchronous follower, it may see outdated information if the follower has fallen behind. This leads to apparent inconsistencies in the database: if you run the same query on the leader and a follower at the same time, you may get different results, because not all writes have been reflected in the follower. This inconsistency is just a temporary state, meaning that if you stop writing to the database and wait a while, the followers will eventually catch up and become consistent with the leader. For that reason, this effect is known as eventual consistency.
The term eventual consistency is deliberately vague as it doesn't tell us about any bounds for this inconsistency, it could be very small and could be very large. In normal operation, the delay between a write happening on the leader and being reflected on a follower—the replication lag—may be only a fraction of a second and not noticeable in practice. However, if the system is operating near capacity or if there is a problem in the network, the lag can easily increase to several seconds or even minutes.
When the lag is so large, the inconsistencies it introduces are not just a theoretical issue but a real problem for applications. In this section we will discuss examples of problems that are likely to occur when there is replication lag and outline some approaches to solving them.
Reading Your Own Writes
Being able to read your own writes, also sometimes known as, read-after-write consistency, means that the system user should be able to instantly view data they have written or updated themselves. They might not see what other users did, but they should see what they personally did.
For example, let's say our application supports a comments thread, if a user types up a comment, then refreshes the page, they should be able to see the comment they just submitted, otherwise, it would be understandably frustrating as they will think that the comment they submitted got lost or something.
To understand how can this happen, let's check the following diagram:
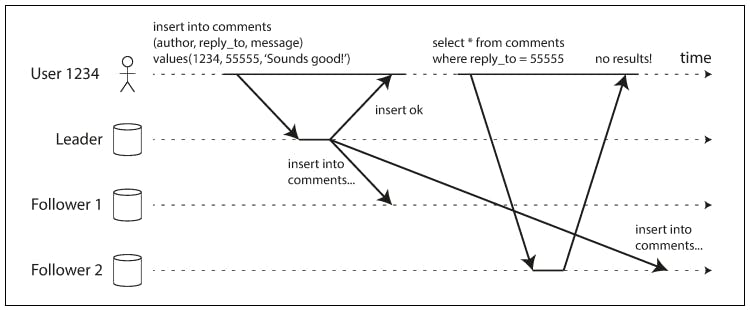
As shown in the previous diagram, the users write was received at the leader and an acknowledgment was sent back to the users, then asynchronous replication was initiated to replicate the newly written data to the 2 follower nodes. The data was received at one of the followers but not yet the other. Meanwhile, a read request was made to the system and it got routed to the other follower that didn't get the write yet which caused a record not found response.
How can we implement read-after-write consistency in a system with leader-based replication? There are various possible techniques. To mention a few:
- When reading something only the user can modify themselves, read it from the writer. For example, a comment can only be submitted or modified by the user themselves, so in that case read it from the writer. This guarantees that the read will always get a hit but it makes no promises about reads relating to fetching other people's comments. This approach is effective when there only a few areas in the application that fall under this category, for example, user posts, settings page, profile, etc. but if there are a lot of areas in the application that are only editable by the user themselves, this becomes ineffective but we don't want to read almost everything from the writer as it defeats the point of having replicas in the first place.
- Another approach is to remember when the last update by the user was made and read data from the writer within that time window only. For example, we can have a rule to always read data from the writer if a write occurred in the past 10 secs or so (you can tweak that number to suit your normal operational replication lag). The timestamp can be a logical timestamp, like for example an LSN (logical sequence number) or an actual timestamp in which case keeping accurate time is critical which is a hard problem in distributed system (synchronizing clocks is not simple).
The previous solutions have a bunch of complications however, for example:
- If your replicas are distributed across multiple datacenters (for geographical proximity to users or for availability), there is additional complexity. Any request that needs to be served by the leader must be routed to the datacenter that contains the leader.
- If the user is writing and reading data from different devices at once, for example submitting a comment from mobile and then viewing that comment from desktop. Things get more complicated if we want to keep a cross-device-read-after-write consistency. This is mainly because: approaches that require knowing the timestamp or the LSN of the last user update won't work on multiple devices unless this metadata is synced to a centralized place. Also if your replicas are distributed across different datacenters, there is no guarantee that connections from different devices will be routed to the same datacenter.
Monotonic Reads
Monotonic reads means that if a user makes multiple read requests to the system, they should always be seeing snapshots of the database that's monotonically increasing, i.e. they are always seeing newer states of the system which means that time is always moving forward.
To understand this better, let's consider the following example:
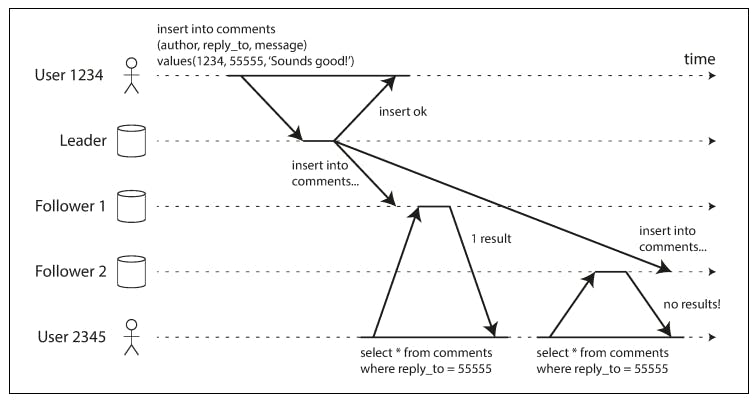
In the previous diagram, user1234 inserts a comment and the async replication is initiated. At the same time, user2345 initiates a reads that happens after the data written by user1234 was replicated to the first follower node. Luckily, the read was routed to follower 1 and the comment was returned, but then user2345 makes another read, but this time it was routed to follower 2 and the comment submitted by user1234 wasn't yet replicated to follower 2, so in this case, it doesn't return any data which is from the perspective of the user, the comment disappeared, like it was deleted.
Monotonic reads is a guarantee that this kind of anomaly does not happen. It’s a lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency. When you read data, you may see an old value; monotonic reads only means that if one user makes several reads in sequence, they will not see time go backward— i.e., they will not read older data after having previously read newer data.
One way of achieving monotonic reads is to make sure that each user always makes their reads from the same replica (different users can read from different replicas). For example, the replica can be chosen based on a hash of the user ID, rather than randomly. However, if that replica fails, the user’s queries will need to be rerouted to another replica.
Consistent Prefix Reads
Consistent prefix reads is a type of consistency guarantee that considers causality of writes. This basically looks at a sequence of writes as they are caused by each other and guarantees that if a sequence of writes were written in some order, they will have to be read in the same order by any number of readers.
Let's consider this example, assume that the following conversation happened:
Mr. Poons
How far into the future can you see, Mrs. Cake?
Mrs. Cake
About ten seconds usually, Mr. Poons.
In this case, those messages are causal, the message from Mrs. Cake is caused by the message sent by Mr. Poons. Now imagine that a listener is viewing this conversation, the following could happen:
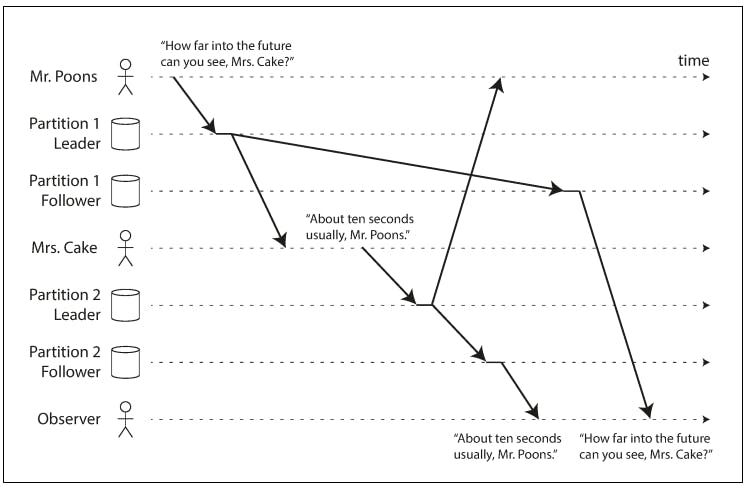
In this example, let's assume that the database is partitioned into 2 parts and each part has 2 nodes. Firs the message by Mr. Poons is written to the leader of part 1 and read by Mrs. Cake shortly after, meanwhile async replication to follower of part 1 has been initiated. Then Mrs Cake responded by a write that was first recorded in the leader of part 2 and shortly after read by Mr. Poons, also in the meantime async replication to follower of part 2 has been initiated.
From the POV of the observer, they got a message from follower of part 2 before the message from follower of part 1 because they replicate independently at different replication lags. And thus the observer got this conversation:
Mrs. Cake
About ten seconds usually, Mr. Poons.
Mr. Poons
How far into the future can you see, Mrs. Cake?
Which supports Mrs. Cake's claim that she can see ten seconds into the future, but violates the causality of writes and thus is not prefix-read consistent.
This is a particular problem in partitioned (sharded) databases, which we will be discussed later in Chapter 6. If the database always applies writes in the same order, reads always see a consistent prefix, so this anomaly cannot happen. However, in many distributed databases, different partitions operate independently, so there is no global ordering of writes: when a user reads from the database, they may see some parts of the database in an older state and some in a newer state.
One solution is to make sure that any writes that are causally related to each other are written to the same partition—but in some applications that cannot be done efficiently. There are also algorithms that explicitly keep track of causal dependencies, a topic that will be discussed later in the book.
Solutions for Replication Lag
When working with an eventually consistent system, it is worth thinking about how the application behaves if the replication lag increases to several minutes or even hours. If that's not a problem for your type of application, then great, less over-engineering is always better. But pretending that replication is synchronous or assuming that it's instant is a recipe for a lot of problems down the line.
As discussed in the previous sections, many of the solutions outlined are application-side, like for example, routing specific reads to the writer and so on. But it would be better if the database can handle that on its own and just do the right thing, wouldn't it? This is why transactions exist: they are a way for a database to provide stronger guarantees so that the application can be simpler.
Single-node transactions have existed for a long time. However, in the move to distributed (replicated and partitioned) databases, many systems have abandoned them, claiming that transactions are too expensive in terms of performance and availability, and asserting that eventual consistency is inevitable in a scalable system. There is some truth in that statement, but it is overly simplistic.
There are systems like Aurora (AWS's MySQL) that handle consistency in a replicated system via transactions, it supports snapshot isolation via Multi-Version Concurrency Control (MVCC). [For more check this article (sayedalesawy.hashnode.dev/amazon-aurora-des..).
Also there are other systems that fully support transactions for partitioned and distributed databases. I recommend checking the literature of Calvin here and a practical application of this in Google Spanner here.
Summary
Replication is often used to scale reads but replication lag is a problem that causes inconsistencies in this architecture. There are some common inconsistencies that can happen in replicated systems because of higher than usual replication lag, such as not being read-after-write consistent, not being able to serve monotonic reads or not being prefix-read consistent. We discussed each of these 3 anomalies and outlined some solutions to them. Then we discussed that those solutions are overly simplistic and advanced databases would have to workaround those inconsistencies and showed examples for databases that can do that.
In the next parts of this chapter, we will discuss topics like multi-leader and leaderless replicated systems.