
Designing Data Intensive Applications: Ch2. Data Models and Query Languages | Part 1


In the previous article, we introduced a book called Designing Data Intensive Applications by Martin Kleppmann and we discussed chapter 1 of the book which discussed Reliable, Scalable and Maintainable Applications.
In this article, we will discuss a part of chapter 2 of the book which will talk about data models. Data models are perhaps the most important part of developing software and it's very important to realize that here we are talking about abstract data models not specific databases that adopt a data model over another.
The choice of a specific data model doesn't just affect how you develop software but it also affects how you think about the problem at hand and how to represent it in order to be able to effectively solve it.
As a matter of fact, in real life applications, things are way more complex than a single data model, applications usually have many data models layers on top of each other and this can be very clear even on a database level; for example, if a database uses a document model (represents data in the form of json or xml documents for example), the same database would have a completely different data model of storing this information internally on disk and the two data models are layered on top of each other and communicate in an abstract way using an API.
There are many different kinds of data models, and every data model embodies assumptions about how it is going to be used. Some kinds of usage are easy and some are not supported; some operations are fast and some perform badly; some data transformations feel natural and some are awkward.
In this article we will look at a range of general-purpose data models for data storage and querying. In particular, we will compare the relational model and the document model.
Relational Model Versus Document Model
The best-known data model today is probably that of SQL, based on the relational model proposed by Edgar Codd in 1970, yes, it's as old as 1970. In the relation model, a world is realized as a group of relations (called tables in SQL) where each relation is an unordered collection of tuples (rows in SQL).
The relational model then went on to dominate the world of database for many many years and although it was originally designed to deserve niche purposes like business data analytics, it turned out to be very generalizable and it's currently very widely used for numerous usecases.
The Birth of NoSQL
The term NoSQL doesn't really refer to any particular technology, it used as a nerdy twitter hashtag in 2009 during an open source meetup on distributed, non-relational databases, nevertheless, it struck a nerve with many people and it's currently used to refer to non-relational databases. The term was later retroactively reinterpreted as Not Only SQL.
But what's the appeal of a NoSQL data model? The main driving forces behind the appeal of a non-relational model are:
- A need for greater scalability than relational databases can easily achieve, including very large datasets or very high write throughput. This is mainly because a non-relational model is easily partitionable across multiple machines (it's worth mentioning that some databases that still use the relational model came super close to this, for example Vitess which is a great solution to partition a MySQL database).
- A widespread preference for free and open source software over commercial database products.
- Specialized query operations that are not well supported by the relational model. This can be very clear if you compare the set of operations a data store like MySQL can do as opposed to the very flexible aggregations data stores like Elasticsearch can perform.
- Frustration with the restrictiveness of relational schemas, and a desire for a more dynamic and expressive data model. Relational schemas are well-known for being very rigid and it becomes even harder to manipulate as your application grows (adding a column in a 2 billion records table for example).
Different applications have different requirements, and the best choice of technology for one use case may well be different from the best choice for another use case. It therefore seems likely that in the foreseeable future, relational databases will continue to be used alongside a broad variety of non-relational data stores—an idea that is sometimes called polyglot persistence (same application using different data models for different usecases within the same business domain).
The Object-Relational Mismatch
Most application development today is done in object-oriented programming languages where entities in the business domain are mapped to models. This leads to what's called an impedance mismatch resulting from the need of having a somewhat awkward translation layer between the database and the application to map those database tables and rows into models used in the application and vice versa.
There exists some really good translation layers, like ActiveRecord and Hibernate, which you might already know them as ORMs (Object-Relational-Mapper) which are responsible for mapping the database and the application models.
Example
Now let's consider an example of a business problem that we want to solve using both the relational and the non-relational model to be able to understand the difference a little more. The example in the book illustrates how a résumé (a LinkedIn profile) could be expressed in a relational schema.
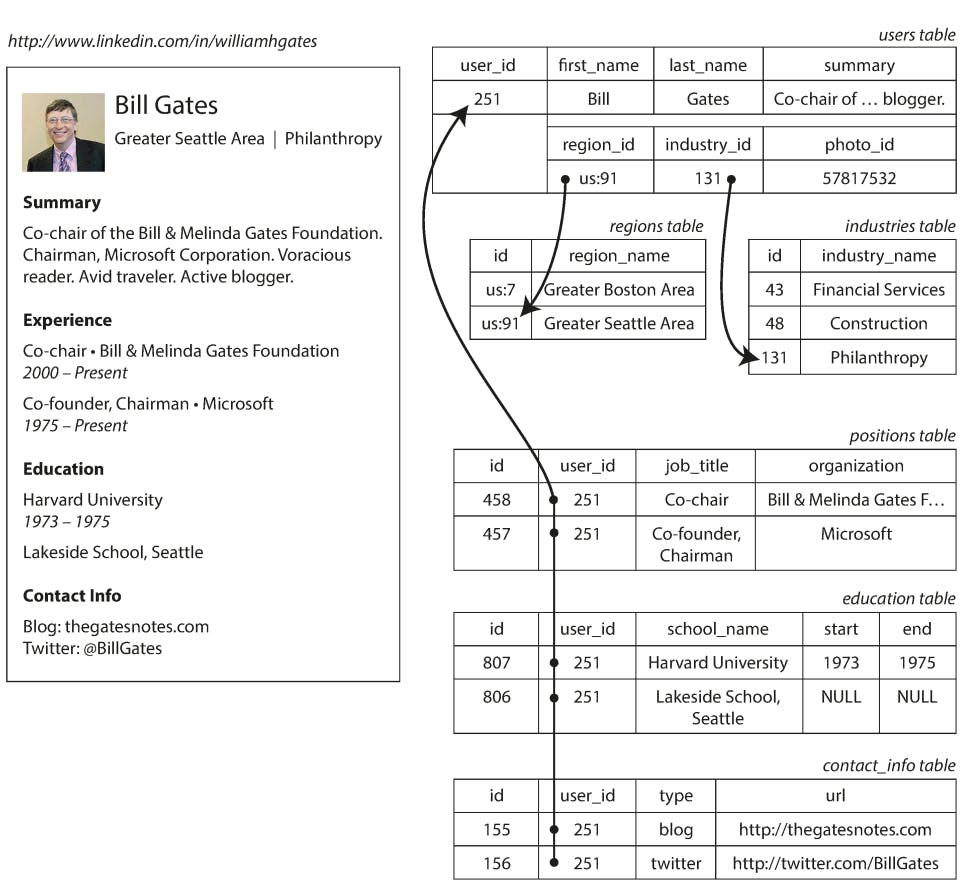
As we can see in the above figure, the resume got mapped out to a set of entities such as, user, region, industry, position, etc. and those entities are linked based on relations, some of those relations are one-to-one like for the user-region relation and some are many-to-one like the user-position relation.
If we think of a resume as a self-contained document, we can represent it in a document model as follows:
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{ "job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation" },
{ "job_title": "Co-founder, Chairman", "organization": "Microsoft" }
],
"education": [
{ "school_name": "Harvard University", "start": 1973, "end": 1975 },
{ "school_name": "Lakeside School, Seattle", "start": null, "end": null }
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
The JSON representation has better locality than the multi-table schema we discussed in the previous diagram. If you want to fetch a profile in the relational example, you need to either perform multiple queries (query each table by user_id) or perform a messy multi-way join between the users table and its subordinate tables. In the JSON representation, all the relevant information is in one place, and one query is sufficient.
Although this seems convenient, but we could argue that the document model introduces a duplication of data, for example, everyone that went to Harvard University will have this bit of information stored in its own document which might seem not that bad since it's just a single bit of info, but imagine those 2 scenarios:
- The university of Harvard decided to change its name for example, then we will have to change the name in all documents referencing "Harvard University" as opposed to updating the
school_namein theeducationtable in the relational model. This is a very common problem with any denormalized schema even if it's a relational schema but it's way more amplified in the document model. - Linkedin decided to not just represent education as a string but as an entity that you can click and it shows more info. If we try to fit this in the document model, the duplication of data is now way more evident and if anything change, which is now more likely, it will be very hard to propagate this change to all documents. This however would be very easy in the relational model (as simple as adding more columns to the
educationtable).
Relational Versus Document Databases Today
There are many differences to consider when comparing relational databases to document databases, including their fault-tolerance properties and handling of concurrency. In this chapter, we will concentrate only on the differences in the data model. The main arguments in favor of the document data model are schema flexibility, better performance due to locality and that for some applications it is closer to the data structures used by the application. The relational model counters by providing better support for joins, and many-to-one and many-to-many relationships.
Which data model leads to simpler application code?
If the data in your application has a document-like structure (i.e., a tree of one-to- many relationships, where typically the entire tree is loaded at once), then it’s probably a good idea to use a document model because in such cases having too many tables with complicated relationships can lead to a cumbersome application logic and might introduce a major performance hit.
The document model has a lot of limitations as well, for example:
- You can't refer directly to an item within a nested list, for example, you can't refer to the second item in the positions list of some user. This is usually okay if the nesting is not too deep to handle.
- The document model by nature has very week support for joins so if your application would rely on performing joins, then the document model is not the best in this case.
- If the nature of the application needs a lot of many-to-many relationships, your application will have a lot of data duplication with all the headache that comes with this which makes the document model way less appealing.
At the end, every model has its downsides and it's our job as developers to reason about those downsides and choose what works for us best based on our usecase. It's also not a matter of black or white, there are many ways to mix both models or even use both models actively in the same application to serve a variety of usecases.
Schema flexibility in the document model
Most document databases, and the JSON support in relational databases, do not enforce any schema on the data in documents. Document databases are sometimes called schemaless, but that’s misleading, as the code that reads the data usually assumes some kind of structure i.e., there is an implicit schema, but it is not enforced by the database.
The difference between the approaches is particularly noticeable in situations where an application wants to change the format of its data. For example, say you want to start storing location information of users moving forward, then you can just start writing new documents with this location information but in a relational model, this change will require a change in the database schema which is notoriously cumbersome (takes a lot of time, might require a downtime and sometimes not even possible using conventional methods).
Data locality for queries
In the document model, as shown in the previous example we discussed, everything related to a user account was saved in the same document, so it's way more efficient to fetch it in a single query instead of firing multiple queries for a relational schema or even performing complex joins.
The locality advantage only applies if you need large parts of the document at the same time. The database typically needs to load the entire document, even if you access only a small portion of it, which can be wasteful on large documents.
It’s worth pointing out that the idea of grouping related data together for locality is not limited to the document model. For example, Google’s Spanner database offers the same locality properties in a relational data model, by allowing the schema to declare that a table’s rows should be interleaved (nested) within a parent table. If you're more interested in this, you can check out my article on Google Spanner here .
What's Next?
In this article we have talked about what's a data model and how it's very important for an application development then we discussed in detail two of the most common data models out there, namely, the relational and the document data models.
In the next part of this article, we will talk more about query languages and how they differ and we will introduce some new graph-like data models as opposed to the models we have already discussed in this part of the article.