
Designing Data Intensive Applications: Ch1. Reliable, Scalable and Maintainable Applications


Welcome to a new series where we discuss a book called Designing Data Intensive Applications by Martin Kleppmann. This is book is widely considered as an encyclopedia of modern data engineering as it discusses a very broad scope that almost touches on every aspect of modern data systems. In this series, I will be summarizing this book, discussing more on the important topics and throwing in some personal knowledge from my experience with building data systems.
The book is split into 3 main parts, namely:
- Foundations of Data Systems: Which discusses topics such as general system properties, data models and query languages, storage systems, data encoding, etc.
- Distributed Data: Which discusses topics like data replication, partitioning, transactions, consistency and consensus, etc.
- Derived Data: Which discusses topics like batch and stream processing.
In this article, we will discuss chapter one which is a discussion regarding general systems properties like reliability, scalability and maintainability, explain what they mean and present different ways of thinking about them.
What is a Data Intensive Application?
The current trend in systems which has been there over the past few years is that systems are no longer CPU-intensive, i.e. the computations are not the limiting factor anymore, rather new systems tend to be dealing with massive amounts of data that needs to be index quickly, stored reliably and processed in a timely manner. This trend introduced data intensive systems.
A data-intensive application is typically built from standard building blocks that provide commonly needed functionality. For example, many applications need to:
- Persist data so that it or other applications can find it (databases).
- Remember the result of frequently done queries to serve them faster (caches).
- Store data in a way that allows keyword searches or aggregations (search indexes).
- Handle data ingestion asynchronously or send messages (stream processing and messaging queues).
- Periodically crunch large amounts of accumulated data (batch processing).
While the previously mentioned sounds obvious and probably any software engineer know one or two tools for each of the above, but the reality is not that simple. There are many database systems with different characteristics, because different applications have different requirements. There are various approaches to caching, several ways of building search indexes, and so on. When building an application, we still need to figure out which tools and which approaches are the most appropriate for the task at hand. And it can be hard to combine tools when you need to do something that a single tool cannot do alone.
Thinking About Data Systems
Firstly, people typically think of data systems as different categories, for example, caches and message queues. Although under hood, they may share the same infrastructure, for example a messaging queue tool like Sidekiq uses a cache like Redis under the hood. They have similar infrastructure but different access patterns and thus different usecases.
💡Trivia
How does Sidekiq uses Redis to build its queues? If you dig deep into this you will find the following:
// Sidekiq establishes it's queues as Redis lists
// Those lists usually have names with the following form:
// <sidekiq_namespace>:queue:<queue_name>
// So for example, a queue called `default`
// in a sidekiq instance running in production, will be named:
// `production:queue:default`
// Sidekiq employs many useful Redis commands to make this work
// maybe the most important one is `rpoplpush` which pops an element (a job)
// from one list and adds it to another list in an atomic fashion.
// This is used to move jobs around inside a sidekiq instance.
// There are many other interesting data structures that sidekiq uses from redis
// such as a `zset` which sidekiq uses to implement delayed jobs.
Secondly, increasingly many applications now have such demanding or wide-ranging requirements that a single tool can no longer meet all of its data processing and storage needs. Instead, the work is broken down into tasks that can be performed efficiently on a single tool, and those different tools are stitched together using application code.
This is the most common use case, usually no data system is simple enough to work with a single plug and play tool. For example, if you have an application that stores data in persistent MySQL, caches transient data in Redis, uses Sidekiq for ingestion and indexes data in Elasticsearch, it's usually the the application's responsibility to stitch those different data systems together to serve the requirement.
The following diagram shows an example of how the application code can stitch those data systems together.
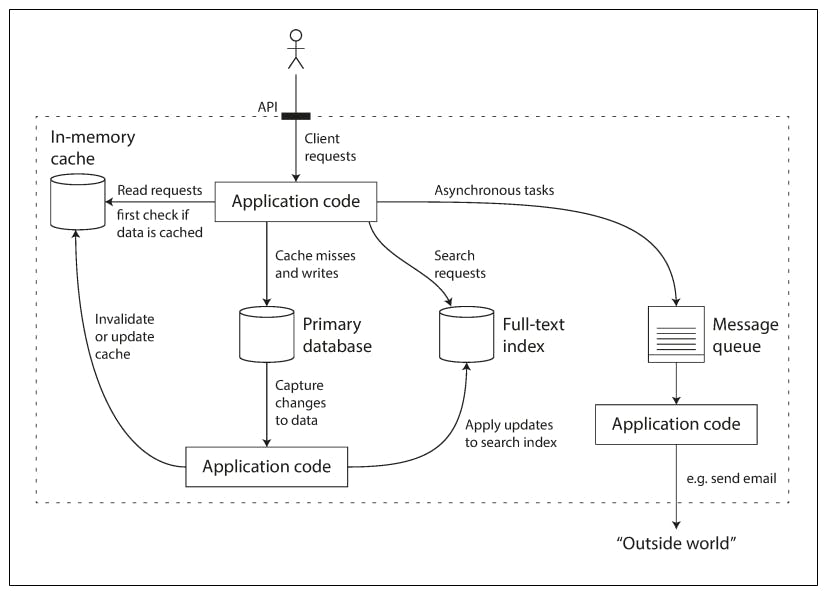
If you are designing a data system or service, a lot of tricky questions arise. How do you ensure that the data remains correct and complete, even when things go wrong internally? How do you provide consistently good performance to clients, even when parts of your system are degraded? How do you scale to handle an increase in load? What to build your application in such a way that adding new features in easy?
The answer to those questions generally fall into 3 main system properties, namely, Reliability, Scalability and Maintainability. So let's take a look at what each of those mean and how can we think about them.
Reliability
Reliability means that a system will continue to work correctly even when things go wrong. Things going wrong are usually referred to as faults. Many people call reliable systems as fault-tolerant which while it makes sense, it's slight misleading because a reliable system is not required to tolerate any fault ever. So where does it end?
We can think about reliability in terms of the following:
- The application performs the function that the user expected.
- It can tolerate the user making mistakes or using the software in unexpected ways.
- Its performance is good enough for the required use case, under the expected load and data volume.
- The system prevents any unauthorized access and abuse.
Being reliable is basically being able to tolerate faults that are reasonable which heavily depends on the nature of the application. For example, if your software might be affected by hardware faults resulting from extreme temperatures in a nuclear reactor, it will definitely have a much higher and a much different reliability metrics than a software that runs in a well cooled data center.
Also note that fault is different than failure. A fault is usually defined as one component of the system deviating from its spec, whereas a failure is when the system as a whole stops providing the required service to the user. It is impossible to reduce the probability of a fault to zero; therefore it is usually best to design fault-tolerance mechanisms that prevent faults from causing failures.
There are 3 main sources of faults that can affect a system, namely:
Hardware Faults:
All of our software systems run on hardware and a supporting infrastructure of power grids and communication cables that are susceptible to faults causing our software to fault as well. A very common example of this is hard disk failures in data centers, for example, hard disks are reported as having a mean time to failure (MTTF) of about 10 to 50 years. Thus, on a storage cluster with 10,000 disks, we should expect on average one disk to die per day.
Those types of faults are usually handled by trying to minimize the downtime of fixing those hardware faults (usually by replacing the faulty component). This is usually done via redundancy, for example, using RAID hard disks, having standby replicas that can take over the job of the faulty component until it's swapped for a functioning one, etc.
So other systems have an interesting take on solving hardware failures, like for example, the cloud provider AWS. Instead of shedding focus to being tolerant on hardware failures, they shed more focus on building systems that can tolerate the loss of entire machines or even entire availability zones (an AWS term of a group of data centers).
This concept is even extended to not only handle unexpected machine loss but to also make operations easier. For example, intentionally taking out a machine out of circulation to be fixed/patched/updated can be modeled as if that machine was lost and the software can deal with that loss thus making operations easier and minimizes downtime and maintenance windows.
If you are more interested in this, I recommend checking out my series on Amazon Aurora (AWS's managed MySQL) which takes about availability zones and how fault-tolerance within a super scale system like Aurora is achieved.
Software Errors:
Another type of faults that can cause a system to fail are of course, software errors. Those are usually 2 types:
- Systematic errors: Those are very hard to detect and usually lie dormant for a long time before they start affecting the system, like for the example, the leap second on June 30, 2012 Linux kernel bug.
- Application specific: Those are the bugs you make while building an application like code that causes a deadlock or unhandled faults, etc.
Software faults sometimes tend to have a cascading effect, i.e. when one part of a service breaks it cause other parts of the system to break as well or become degraded.
There is no quick solution to the faults in software. Lots of small things can help: carefully thinking about assumptions and interactions in the system; thorough testing; process isolation; allowing processes to crash and restart; measuring, monitoring and analyzing system behavior in production.
Human Errors:
Humans make mistakes and that's an inevitable fact. One study of large internet services found that configuration errors by operators were the leading cause of outages, whereas hardware faults (servers or network) played a role in only 10–25% of outages.
There are however a lot we can do to make systems reliable even when human error happens such as:
- Design systems in a way that minimizes opportunities for error, i.e. make it hard to make mistakes.
- Introduce some gradual roll-out techniques where changes are tested in a sandbox and get rolled out to only a small percentage of users before a full release.
- Test thoroughly at all levels, from unit tests to whole-system integration tests and manual tests.
- Set up detailed and clear monitoring, such as performance metrics and error rates.
💡Trivia
Sometimes it's actually better to cause systems to fault in order to discover unexpected problems or dispute any unfounded assumptions. Netflix for example takes this to the next level via chaos engineering. They have a tool called chaos monkey which induces random faults throughout the system. This helps Netflix engineers monitor how the system behaves under such faults which allows them to fix any unexpected behaviors before they actually naturally happen to real users.
Scalability
Even if a system is working reliably today, that doesn’t mean it will necessarily work reliably in the future. One common reason for degradation is increased load: perhaps the system has grown from 10,000 concurrent users to 100,000 concurrent users or perhaps it is processing much larger volumes of data than it did before.
Scalability describes the ability of a system to cope with increased load. Scalability is usually thrown around as a one-dimensional label, people say x doesn't scale but y scales but it's not that simple however. To be able to reason about a system's scalability, one has to first describe what a load means to be able to pin point bottlenecks in the system. Scalability makes you answer questions like: If the system grows in a particular way, what are our options for coping with the growth?
Describing Load
First, we need to succinctly describe the current load on the system; only then can we discuss growth questions (what happens if our load doubles?). Load can be described with a few numbers which we call load parameters. The best choice of parameters depends on the architecture of your system: it may be requests per second to a web server, the ratio of reads to writes in a database, the number of simultaneously active users in a chat room, the hit rate on a cache or something entirely different.
The book goes over a concrete example on a scalability problem that twitter faced. It's as follows:
Back in 2012, twitter published some data about their load handling which indicated 2 main activites:
- Post tweet: A user can publish a new message to their followers (4.6k requests/sec on average, over 12k requests/sec at peak).
- Home timeline: A user can view tweets posted by the people they follow (300k requests/sec).
So now that we have described the load, we can describe the bottleneck in the system. Writing 12k tweets to a database is not really a bottleneck in itself, but due to the way twitter is designed, it causes a massive fan-out because every twitter user follows many people and has a lot of followers and those tweets that he posts will have to make it to his followers timeline.
There are 2 ways to tackle this:
- Posting a tweet simply inserts the new tweet into a global collection of tweets and when a user requests their home timeline, look up all the people they follow, find all the tweets for each of those users, and merge them (sorted by time). In a relation database, this might look like this:
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user
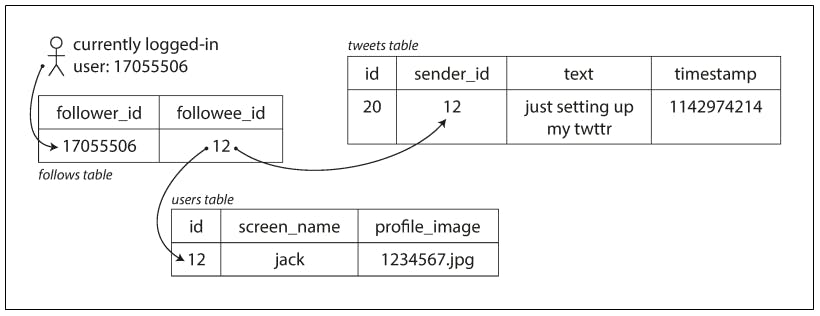
- Maintain a cache for each user’s home timeline—like a mailbox of tweets for each recipient user and when a user posts a tweet, look up all the people who follow that user, and insert the new tweet into each of their home timeline caches.
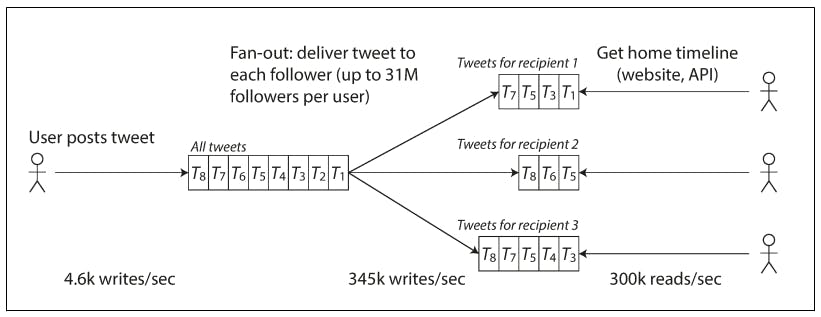
We can see the clear difference between both approaches, the first approach minimizes write latency because we do a single write and it defers the heavy load in the read time, while the second approach does the opposite but it partially remedies the expensive writes by writing the fan-out into in memory caches instead of a database.
Twitter started with the first approach but it didn't scale because as we can see from the data, their read load is 60 times larger than their write load. So they transitioned to the second approach to be able to scale.
Describing Performance
The other main aspect to reason about a scalability problem is to describe the system performance. Describe the load is not enough, because what does it mean to have 300k twitter timeline reads? How can we tell if it's bad or good? How can we tell if the system is actually scaling well when it hits 400k reads?
To describe load, you can look at a system in 2 ways:
- When you increase a load parameter and keep the system resources (CPU, memory, network bandwidth, etc.) unchanged, how is the performance of your system affected?
- When you increase a load parameter, how much do you need to increase the resources if you want to keep performance unchanged?
There are many ways to describe performance and it's dependent on the nature of the system, for example, interactive applications like APIs can measure performance by measuring response times on the other hand batching processing systems that usually take long to process a batch of data wouldn't make much use of a response time metric since it's a background process, but another metric that might be useful is to measure it's throughput (how many jobs it can process per time unit).
The book then goes to explain that raw response times usually mean nothing and some mathematical approximations that might be done on those raw response times might be wildly inaccurate, for example, averages are well-known to be susceptible to skew. The book suggests using percentiles when we analyze response times, for example, the p95th percentile indicates that value at which 95% of all requests respond faster. The choice of which percentile to monitor is application dependent.
There are more details in the book about this example, but the main take here is that we couldn't initially, right of the bat, claim that this system doesn't scale. We only became able to make informed decisions when we described the load and pin pointed the bottlenecks.
Approaches for Coping with Load
Another take away point from the previous example is that making systems scale is usually heavily dependent on the nature of the application.
There are some common techniques however, for example:
- Scaling (vertical or horizontal).
- Elastic systems that can add more resources when it needs.
- Parallelized systems that split a workload across multiple instances of the same application.
The book introduces more ideas that can help build scalable systems throughout the coming chapters.
Maintainability
It is well known that the majority of the cost of software is not in its initial development, but in its ongoing maintenance—fixing bugs, keeping its systems operational, investigating failures, adapting it to new platforms, modifying it for new use cases, repaying technical debt and adding new features.
All of us have probably worked on legacy systems before and understand the pain associated with that. So how can we make new systems maintainable and not have it turn into a legacy system that's painful for others later on? The book discusses 3 main design principles:
1. Operability: Making Life Easy for Operations
One area where a legacy system might be such a pain is operations. If a system is hard to operate, i.e. monitor, upgrade, roll out changes to, etc. it will be such a pain to operation teams.
Good operability means making routine tasks easy, allowing the operations team to focus their efforts on high-value activities. Data systems can do various things to make routine tasks easy, including:
- Providing visibility into the runtime behavior and internals of the system, with good monitoring.
- Avoiding dependency on individual machines (allowing machines to be taken down for maintenance while the system as a whole continues running uninterrupted).
- Providing good documentation and an easy-to-understand operational model (If we do x, y will happen).
2. Simplicity: Managing Complexity
Small software projects can have delightfully simple and expressive code, but as projects get larger, they often become very complex and difficult to understand. This complexity slows down everyone who needs to work on the system, further increasing the cost of maintenance. A software project mired in complexity is sometimes described as a big ball of mud.
Making a system simpler does not necessarily mean reducing its functionality; it can also mean removing accidental complexity. Moseley and Marks define complexity as accidental if it is not inherent in the problem that the software solves (as seen by the users) but arises only from the implementation.
One of the best tools we have for removing accidental complexity is abstraction. A good abstraction can hide a great deal of implementation detail behind a clean, simple-to-understand facade. However, finding good abstractions is very hard. In the field of distributed systems, although there are many good algorithms, it is much less clear how we should be packaging them into abstractions that help us keep the complexity of the system at a manageable level.
3. Evolvability: Making Change Easy
It’s extremely unlikely that your system’s requirements will remain unchanged for‐ ever. They are much more likely to be in constant flux: you learn new facts, previously unanticipated use cases emerge, business priorities change, users request new features, etc.
Evolvability makes it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. Also known as extensibility, modifiability or plasticity.
This aspect is more concerned with processes practiced in the software development cycle rather than any software architectures. A good example for this is Test Driven Development (TDD) and refactoring.