Designing Data Intensive Applications: Ch4. Encoding and Evolution

Lead Software Engineer at Instabug | Backend team. Passionate about large scale server side applications and distributed systems. Cairo University - Faculty of Engineering grad.
In the previous two articles of this series we discussed chapter 3 relating to storage and retrieval techniques, check them out here and here.
In this article we will talk about chapter 4 of the book which discusses Encoding and Evolution. Applications inevitably change over time. Features are added or modified as new products are launched, user requirements become better understood, or business circumstances change. This necessitates that developers should consider evolvability while building their applications to make them easy to adapt to changes.
In this chapter will concentrate on data encoding/decoding techniques and their evolvability properties. We will discuss standardized encoding techniques like JSON and XAML and binary encoding techniques like Thrift and Protocol Buffers.
Compatibility
The most common type of change that happens to an application during its life cycle is a change in the underlying data model. As we discussed in chapter 2, some data models like the relational model assume that all data conform to a rigid schema, so any changes in the data like adding a new field or changing the type of one field all translate into schema changes in the data store used. Other models like the document model however are schemaless, in the sense that changing the data can most likely be accommodated without any changes to the data store.
The other, also common type of change, is an application code change, like for example a change in an API contract. Those changes are also tricky to handle since the server and its consumers agree to a contract, breaking that contract will cause the consumers to not be able to understand the server anymore and vice versa. Sometimes, it's easy to change both the server and the consumers simultaneously, but in other cases, this is just not doable.
Which brings us to compatibility, there are two types of compatibility:
- Backward compatibility: Newer code can read data that was written by older code.
- Forward compatibility: Older code can read data that was written by newer code.
Backward compatibility is normally not hard to achieve as author of the newer code, you know the format of data written by older code, and so you can explicitly handle it (if necessary by simply keeping the old code to read the old data). Forward compatibility can be trickier, because it requires older code to ignore additions made by a newer version of the code.
Formats for Encoding Data
In this chapter we will look at several formats for encoding data, including JSON, XML, Protocol Buffers, Thrift, and Avro. In particular, we will look at how they handle schema changes and how they support systems where old and new data and code need to coexist.
When encoding data, you can either choose a language specific encoding, like for example if you're using Java, it provides java.io.Serializable which encodes entities in the memory in a byte format that can be sent over networks or written to disks or anything. The problem with this approach is those language dependent encodings assume a specific language on both ends, translating the serialization into a different language is often very hard.
The language specific approach is very limiting and thus not widely used. On the other hands, there are universal/standard formats that can be used which are called standardized encodings, like for example JSON, XML, HAML, CSV, etc. Those define a specific syntax that's standardized and implemented in almost all languages, so data encoded in a JSON format for example can be decoded by almost any language in existence. Some of those encodings are more popular to others, some of them are less verbose than others and some have problems that don't exist in others and vice versa, so preferences vary but they all have the same idea of sending textual data in a standardized format.
Binary encoding
For data that is used only internally within your organization, there is less pressure to use a lowest-common-denominator encoding format. For example, you could choose a format that is more compact or faster to parse. For a small dataset, the gains are negligible, but once you get into the terabytes, the choice of data format can have a big impact.
To understand binary encoding, let's take an example of a binary encoding technique called MessagePack, let's assume we have the following JSON data:
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
This will produce an encoding like this:
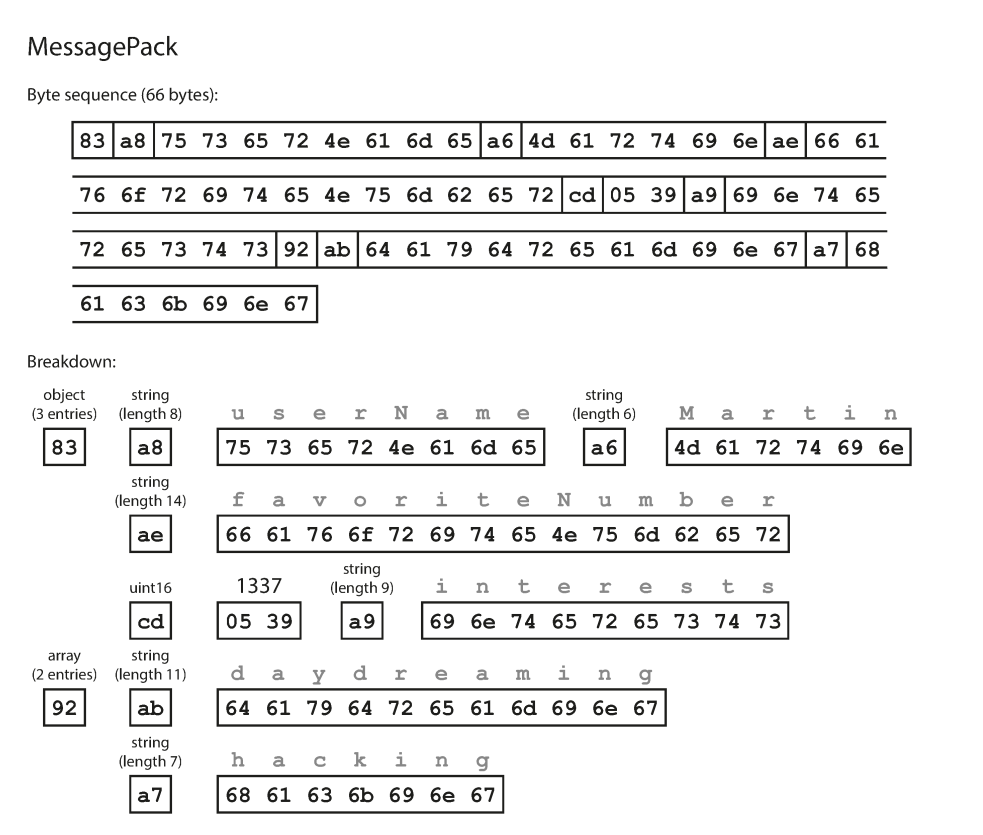
How does that work?
- The first byte,
0x83, indicates that what follows is an object (top four bits =0x80) with three fields (bottom four bits =0x03). - The second byte,
0xa8, indicates that what follows is a string (top four bits =0xa0) that is eight bytes long (bottom four bits =0x08). - The next eight bytes are the field name
userNamein ASCII. Remember that we already indicated its character size in the previous byte (8 characters indicated by the bottom four bits0x08. - The next seven bytes encode the six-letter string value
Martinwith a prefix0xa6, and so on.
The binary encoding is 66 bytes long, which is only a little less than the 81 bytes taken by the textual JSON encoding (with whitespace removed). All the binary encodings of JSON are similar in this regard. The difference here might look small, but in very large scale applications, such a small difference can reduce a lot of data transfer incurred costs.
In the following sections we will see how we can do much better, and encode the same record in just 32 bytes.
Thrift and Protocol Buffers
Thrift and Protocol Buffers are both binary encoding techniques developed by Facebook and Google respectively. They are able to do a much more compact binary representation of textual data, but the main difference from something like MessagePack is that they require a schema.
Let's take protocol buffers as an example to encode the same JSON data as in the previous example, the encoding will look like this:
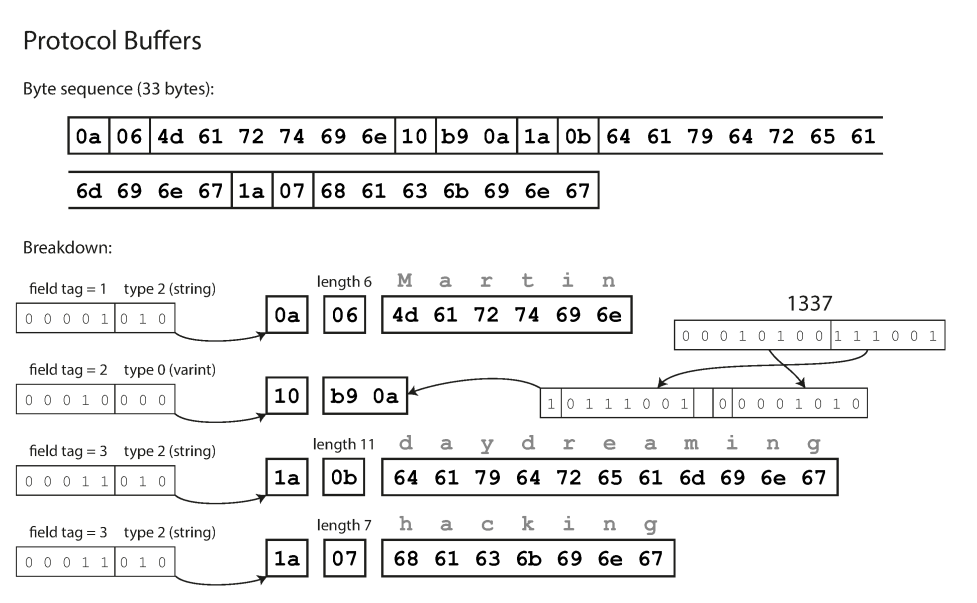
How does that work?
First of all as mentioned before, protocol buffers needs a schema, the schema for protocol buffers will look like so:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
As you may have already guessed, it did a very simple trick over MessagePack, it differed metadata encoding like for example, field names, types, the number of fields, etc. to the schema defined on both sides of the communication channel. So for example, instead of saying the field user_name, I can just say 1 which is a much more compact way.
Now let's take a look at how Protocol Buffers employs this schema to do better than MessagePack:
- The first byte,
0x0a, indicates that this is the field with tag = 1 has type string, (highest 4 bits =0x0) and (lowest 4 bits =0xa). - The next byte indicates the length of the value to come, which is 6 characters in case of the value
Martin, so0x06. - The next six bytes encode the six-letter string value
Martinand so on.
So here we saved:
- The first byte in MessagePack that indicated that the message is a struct with 3 fields.
- The eight bytes that represented the field name
userName.
As a matter of fact, if you count the bytes for the overall message, you would get 33 bytes only with Protocol Buffers as opposed to 66 bytes with MessagePack.
There is another econding called Avro which I am not going to discuss here to keep the article short that's even more compact as it gets to as low as 32 bytes for the example message.
Schema Evolution and Protocol Buffers
As explained above, Protocol Buffers introduced a schema to make encoding even more compact, but would this schema evolve or would it be a limiting factor? Let's check both aspects of the schema:
- Field tags: Each field in the schema has a unique tag, please don't think of it as an order or things will get really weird now, the tag is sent in the message and used on the other end to know which field is this one. If a field doesn't exist or doesn't have a value, it's simply omitted, so removing existing fields has no issues. If we add a new field, provided we use a unique tag (which enforced by syntax rules), this new field will start getting encoded and sent in the message normally, so the new code expecting this new field will be able to parse it, also the new code will be able to parse previously written data because its the same as deleting a field.
- Field types: Changing types is also possible but has some caveats, for example let's say you changed the type of an
int32field toint64, the encoding will work normally as it will fill the empty bits with zeros, but if an old code is reading new values, it will parseint64intoint32which will cause precision loss.
Summary
In this chapter we looked at several ways of turning data structures into bytes on the network or bytes on disk. We saw how the details of these encodings affect not only their efficiency, but more importantly also the architecture of applications and your options for deploying them.
In particular, many services need to support rolling upgrades, where a new version of a service is gradually deployed to a few nodes at a time, rather than deploying to all nodes simultaneously. Rolling upgrades allow new versions of a service to be released without downtime (thus encouraging frequent small releases over rare big releases) and make deployments less risky (allowing faulty releases to be detected and rolled back before they affect a large number of users). These properties are hugely beneficial for evolvability, the ease of making changes to an application.
We discussed several data encoding formats and their compatibility properties:
- Programming language–specific encodings are restricted to a single programming language and often fail to provide forward and backward compatibility.
- Textual formats like JSON, XML, and CSV are widespread, and their compatibility depends on how you use them. They have optional schema languages, which are sometimes helpful and sometimes a hindrance.
- Binary schema–driven formats like Thrift and Protocol Buffers allow compact, efficient encoding with clearly defined forward and backward compatibility semantics.




