Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases (Part 2)

Lead Software Engineer at Instabug | Backend team. Passionate about large scale server side applications and distributed systems. Cairo University - Faculty of Engineering grad.
So in the part-1 article we discussed some of the design decisions made by the AWS team while building Aurora, mainly, decoupling the compute and the storage tiers and achieving high availability and durability via 6-way replication across 3 AZs.
By the end of the last article it was clear that the replication approach used for Aurora while it's very good for providing durability against some of the most unlikely scenarios (for example the loss of an entire AZ), it introduces an untenable performance burden in terms of network IOs and synchronous stalls. In this article we will discuss how Aurora mitigates those problems to achieve high throughput while enjoying all the resiliency guarantees we discussed in part 1.
The Burden of Amplified Writes
As we previously discussed, Aurora uses a segmented storage model where the node storage is split into smaller segments each of size $10GB$ and those segments are replicated 6-way across 3 Availability Zones which if done conventionally would be extremely bad in terms of performance because each application write corresponds to a variety of IOs that MySQL will have to perform and mirror to other replicas.
To understand this better, let's take the following design as an example.
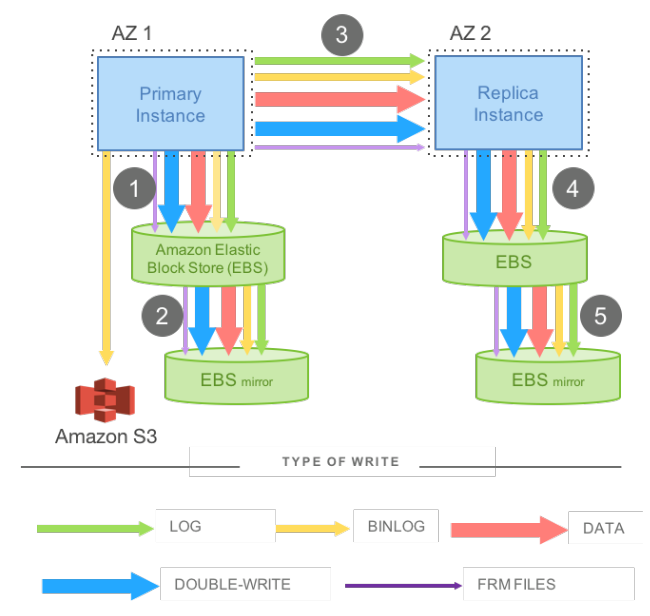
Here we have a synchronous mirrored MySQL setup consisting of a main instance and another active-standby instance that each can be in a different AZ for better availability. So let's assume that the first instance is in AZ1 and the second instance is in AZ2 and each instance uses an EBS volume that's also replicated inside the same AZ for better durability. As we can see, a write operation will have to be written to the first EBS volume, then replicated to the EBS replica within the same AZ and then the write (along with all the extra MySQL IOs) are mirrored to the instance in AZ2 and the same process takes place. Note that the whole thing is synchronous because for a write to be acknowledged, it has to be written in instance 1 and mirrored successfully to instance 2, even if the mirroring happens asynchronously, it will have to wait for the slowest write before it can acknowledge it. So from a distributed systems perspective, we have a write quorum of 4/4 because if any of the 4 writes to the EBS volumes fails, it will break quorum and the write will not be acknowledged.
The other important thing to note here is that a simple application write produced a lot more IOs from MySQL's side. As we can see from the previous figure, there are many types of data that will have to be mirrored:
- Redo log: Which are data structures used by MySQL to encode transactions. You can think of a redo log as an encoding for modifications that can be applied to a data page's before-image to produce its after-image (after that modification was applied). The redo logs are written to the Write Ahead Buffer (WAL).
- Binlog: Which is a log of statements that were executed which is useful for point-in-time restoration.
- Data: The actual data pages that MySQL writes to the objects it exposes such as, heap files and b-trees.
- Double-write: Which is a second temporary write of the data page that's used in case writing the main page was interrupted by an unexpected crash which solves a common problem known as torn pages which happens when only part of the page was written to disk.
- FRM files: Which contains metadata.
So it's clear that replicating all of the above data streams 4-ways, let alone, 6-ways in Aurora would be a massive performance hit.
Offloading Redo Processing to Storage
As discussed before, when a traditional MySQL database modifies a data page, it produces a redo log and writes it into the WAL. The redo log is generated such as that when it's applied to the before-image of the data page we can obtain the after-image. So basically transactions only wait to commit the redo logs while the actual writing of pages can be deferred to happen later in the background (known as flushing pages because data pages are cached first and flushed periodically to reduce disk IOs).
Considering that redo logs provide the needed degree of durability because it guarantees that if we start from scratch and apply all the redo logs of a certain data page we will end up with the most recent version of this data page, then we can solely depend on it for replication. So in Aurora, only redo logs cross the network, no pages are ever written from the database tier, not for background writes, not for checkpointing and not for cache eviction. This dramatically reduces the network cost and allows Aurora to push the log application process to the storage tier where data pages can be generated in the background (data page materialization) or on demand when pages that are not current are read.
Because regenerating data pages from its history since the beginning of time is prohibitively expensive, Aurora has a background log applicator that materializes the data pages in the background so they can be as near to up to date as possible. Note that the background materialization of data pages is merely a performance improvements for reads and completely optional for correctness since writes are considered durable once the redo logs have been persisted. You can think of this as a cache for data pages that can be flushed or lost at anytime and can be easily regenerated from its source of truth which is the redo logs, so it's not an understatement when the paper states that "The Log is the Database".
So a sample Aurora design looks like so:
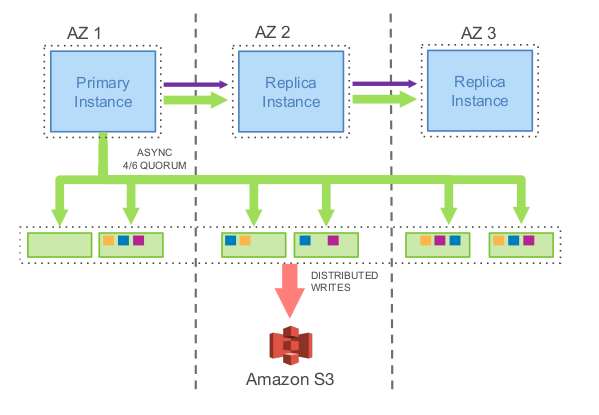
It consists of a primary instance in one AZ and 2 replica instances in 2 different AZs for the compute tier which is connected to 6 storage nodes that are spared across the 3 AZs in pairs. Note that the green arrows between instances in the compute tier represent redo logs crossing the network while the purple lines are the FRM metadata files (note that nothing else crosses the network).
When a write operation is performed against Aurora, it would send the redo log records to all 6 storage nodes and waits for 4 of them succeed to satisfy the write quorum and consider the redo log records in question durable. The replicas later use the redo log records to apply changes to their buffer caches and materialize the data page as mentioned above.
To measure the effect of the previous optimization, the paper reviews a benchmark of a write-only $100GB$ workload that was executed by both the previously mentioned configurations (the traditional synchronous mirrored MySQL Vs. Aurora) for 30 mins on an r3.8xlarge EC2 instance and the result were as follows:
| Configuration | Transactions | IOs/Transaction |
| Mirrored MySQL | 780,000 | 7.4 |
| Aurora with Replicas | 27,378,000 | 0.95 |
Over the 30 mins period, Aurora was able to sustain 35 times more transactions than mirrored MySQL. The number of IOs per transaction on the database node in Aurora was 7.7 times fewer than in mirrored MySQL despite amplifying writes 6 times with Aurora as opposed to only 4 in the mirrored MySQL setup. The network cost is also dramatically reduced.
Replicating redo logs only is also very useful for crash recovery. When a normal MySQL instance crashes, when it's rebooted, it does crash recovery on startup by replaying the persisted redo logs, while In Aurora, durable redo log application happens at the storage tier, continuously, asynchronously and distributed across the storage fleet in the sense that when data pages are read and they turn out to not be current (there are updates are not yet flushed to the data page) they get materialized on demand and this happens across multiple nodes during processing foreground requests so nothing special is required on start up which minimizes downtime. Note that when Aurora crashes, it doesn't really apply the entire redo log, rather it can start from the latest snapshot (usually saved in AWS S3) and apply redo logs starting there which reduces the effect of crash recovery on read throughput.
Storage Service Design Points
A core design objective of the storage tier is to minimize the latency of foreground write requests by doing as much work as possible in the background. This can be seen in some tasks such as garbage collection of old page versions, in the sense that Aurora would trade CPU for disk because for example it might delay the process of garbage collection if the disk is okay to allow the CPU to do more foreground work and thus reducing the overall latency at peak times but take any chance to perform background work when CPU is not being fully utilized. But if the disk is getting filled and the CPU is being utilized for foreground processing, Aurora would use a form of back pressure to throttle the foreground requests in order to perform the now more urgent background tasks.
We can reason that this has minimal to no effect on the overall latency of the system because we have a write quorum of 4/6, so a node that's currently being throttled can be modeled as a slow node that won't affect the speed at which a write quorum is obtained because another node would simply respond faster effectively taking its place and because writes are randomly spread out across nodes, the chance of more than 1 or 2 throttled nodes is sufficiently unlikely.
Let's take a look at the various activities that take place inside storage nodes.
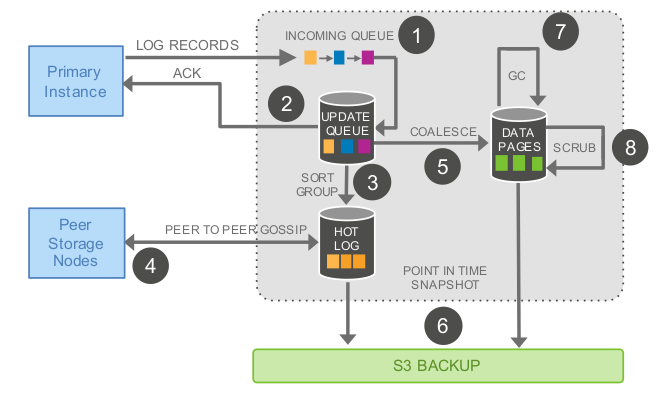
- Receive redo log record and add to an in-memory queue.
- Persist log records on disk and acknowledge them.
- Organize log records and identify gaps in the redo logs since some batches may be lost.
- Gossip with other storage nodes to fill in gaps in the redo log chain.
- Materialize the redo log records into new data pages.
- Periodically back up log records and new pages to S3.
- Periodically garbage collect old versions.
- Periodically validate CRC codes on pages to identify faulty pages (the paper doesn't mention what happens if a faulty page was detected however).
Note that only steps 1 and 2 are synchronous and in the foreground path so they are the only 2 steps that can potentially impact latency of a given storage node (ignoring throttling that might happen due to background processes).
Moving forward
Now that we have a good idea on Aurora handled the burden of amplified writes generated from its durable replication strategy, another question poses itself, which is how does Aurora guarantee that the durable state, the runtime state and the replica state are always consistent without having to use expensive 2PC (two-phase-commit) protocols that are chatty by nature and intolerant of failures which we will discuss in the part 3 of this article.
References
Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases




