
Designing Data Intensive Applications: Ch.6 Partitioning (Part 3: Rebalancing Partitions and Request Routing)


In the previous two articles, we introduced the concept of partitioning as a means to further scale out a system. We went over concepts like partitioning a key-value data set and discussed how partitioning works with secondary indexes.
In this article, we will discuss how partitioned databases deal with the changing nature of query throughput and data set sizes via performing rebalancing and we will go over some of the rebalancing approaches that can be used, like the hash mod N, fixed partitions, and dynamic partitioning.
Then we will discuss how partitioned systems perform request routing either by using distributed consensus algorithms or authoritative medata mapping services like ZooKeeper.
Rebalancing partitions
Over time, things change in a database, for example:
Query throughput increases which warrants adding more compute power to handle the load.
The dataset size increases which might require adding extra disk storage or needing to keep a partition size constant by moving some data into a new partition.
A machine might fail which requires re-assigning its shard of the data to other healthy machines in the system.
All of these call for data to be moved from one node to another. The process of moving data around between nodes in the cluster is called rebalancing.
In terms of rebalancing, it doesn't really matter what kind of partitioning scheme was originally used to partition the data, a rebalancing process has to meet the following minimum requirements:
After rebalancing, the load (data storage, read and write requests) should be shared fairly between the nodes in the cluster.
While rebalancing is happening, the database should continue accepting reads and writes.
Don’t move more data than necessary between nodes, to avoid overloading the network.
Strategies for rebalancing
Now let's go over some of the strategies we could use to rebalance data across the nodes in the cluster.
Hash mod N
This is a very obvious method of partitioning data by the hash of the partitioning key as we discussed in a previous article. To recap, in this method, we assign data based on the range that the hash of the partitioning key falls in, so for example, assign a key to partition \(0\) if \(0 \leq hash(key) < b_0\) and to partition \(1\) if \(b_0 \leq hash(key) < b_1\)and so on.
Perhaps you wondered why we don’t just use mod (the % operator in many programming languages). For example, \(hash(key) mod 10\) would return a number between \(0\) and \(9\). If we have 10 nodes, numbered 0 to 9, that seems like an easy way of assigning each key to a node.
The major problem with the \(mod \space N\)approach is if the number of nodes in the cluster \(N\) changes, there will be lots of unnecessary data moving. For example, if the \(hash(key) = 123456\) and the number of nodes is 10, then this key will go to node number 6, but if the number changes to 11, it goes to node number 2 and if the number grew again to say 12, it goes to node number 0, etc.
This makes rebalancing excessively expensive which violates rule number 3 in the criteria we defined earlier. Thus we need a different approach that doesn't end up moving data around unnecessarily.
Fixed number of partitions
In this strategy, we try to separate the number of nodes and the key assignment to avoid problems like in the previous approach where the key assignment constantly changes when the number of nodes in the cluster changes.
So, we will create more partitions than there are nodes in the cluster, for example:

In the previous diagram, the cluster originally had 4 nodes but data was partitioned into 20 partitions such that each node is handling 5 partitions. Assigning a specific key to a partition is now completely independent from the number of nodes in the clusters, for example, if we assign keys using the mod technique we discussed in the previous approach, the partition in which a key will end up is a function of the number of partitions (not the number of nodes), so if we keep the number of partitions constants, this assignment should not change as we change the number of nodes.
Now, let's observe how this system adapts to adding a node. The new node will have to steal some of the partitions that were assigned to other partitions prior to it joining the cluster so that now each node is handling 4 partitions.
The key concept to notice here is that the number of partitions is still fixed, it's still 20, but the number of nodes is what's changing. Also, when moving data, we are moving entire partitions (not individual documents are being moved around). This change of node-partition assignment is not immediate — it takes some time to transfer a large amount of data over the network — so the old assignment of partitions is used for any reads and writes that happen while the transfer is in progress. This is the method used for systems like Cassandra and Elasticsearch.
In such systems, changing the number of partitions is not allowed, it requires migrating to a new cluster with a different number of partitions which is an expensive operation. This limitation makes things easier, but it makes it a little inflexible, so be careful while choosing the number of partitions to account for future growth, but also beware that there is an overhead in the management of each partition, so it's counterproductive to choose too high a number.
Dynamic partitioning
A fixed number of partitions works quite well in conjunction with hash partitioning, because the hash function ensures that the keys are distributed uniformly across the whole range of possible hashes.
However, for databases that use key range partitioning like the ones we discussed in previous articles (to recap: we assign a key based on which range the key falls in, for example, assign a book record based on the first character of its title), fixed partition boundaries would be very inconvenient: if you get the boundaries wrong, you could end up with all of the data in one partition, and all of the other partitions being empty.
For that reason, key-range-partitioned databases implement a dynamic rebalancing strategy where the number of partitions changes dynamically to evenly spread the load. For example, when a partition grows to exceed a certain threshold, say 10GB, it gets split into 2 smaller partitions. Conversely, if lots of data gets deleted and the partition shrinks below a specific threshold, it gets merged with another partition to minimize overhead. This is very similar to B-tree operations at the top level.
Again, each partition is assigned to one node and each node can handle multiple partitions. So when a partition grows and gets split into 2 partitions, one of those partitions might get moved to another node to spread the load (same as the previous approach).
An advantage of dynamic partitioning is that the number of partitions adapts to the total data volume. If there is only a small amount of data, a small number of partitions is sufficient, so overheads are small; if there is a huge amount of data, the size of each partition is limited to a configurable maximum. This introduces a corner case though, when the database is empty, it will always have a single partition which makes the first split of data quite hard because all writes have to be processed by a single node while the other nodes sit idle. Some databases get around this by allowing what's called a pre-splitting which allows database users to set an initial number of partitions for an empty database.
Dynamic partitioning is not only for key-range-partitioned data, but can equally well be used with hash-partitioned data.
Operations: automatic or manual rebalancing
There is one important question about rebalancing that we have glossed over: Does the rebalancing happen automatically or manually?
There is a full range between fully automatic rebalancing (the system decides to automatically move partitions from one node to another without any admin intervention) and fully manual rebalancing (nothing happens unless an admin initiates the rebalancing). Some systems have it in between as they suggest an ideal balance of partitions but nothing gets executed unless an admin manually commits.
Fully automated rebalancing seems like the convenient approach, but it can be extremely dangerous because rebalancing is a very expensive approach that strains the network, origin nodes and destination nodes until it's done. So if it was executed at a time that the system is already suffering or under load, it can make a bad situation worse. Also, if the system is using automatic failure detection in combination with automatic rebalancing, this can cause very unpredictable rebalancing decisions if the system thinks that a latent node is unhealthy and initiates a rebalance.
For that reason, it can be a good thing to have a human in the loop for rebalancing. It’s slower than performing it fully automatically, but it can help prevent operational surprises.
Request routing
Now it's time to answer the lingering question of how can a client know which node has the key it's looking for. Especially now that rebalancing moves partitions from one node to another node, thus changing the IP from which that partition was initially accessible. This suggests that someone needs to be on top of those changes to be able to answer the question: If I want to read or write the key “foo”, which IP address and port number do I need to connect to?
This is an instance of a more general problem called service discovery, which isn’t limited to just databases. Any piece of software that is accessible over a network has this problem, especially if it is aiming for high availability (running in a redundant configuration on multiple machines).
This can be done in one of the following 3 methods illustrated in the following diagram:
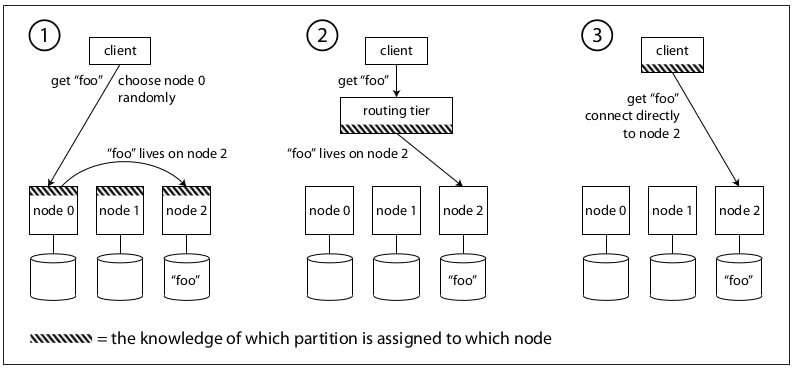
Allow clients to contact any node (via a round-robin load balancer perhaps). If that node coincidentally owns that partition, it can serve this request or it can forward it to the appropriate node (provided that it nodes which one, maybe via sharding key or something similar).
Send all requests to a routing tier first which determines which node should handle this request and then forwards to the appropriate node directly. This is called a partition-aware load balancer and it doesn't handle any requests, it just forwards the request to the correct node.
Require that clients be aware of the partitioning and the assignment of partitions to nodes in which case they can directly connect to the appropriate nodes without a middleman.
In all cases, the key problem is: how does the component making the routing decision (which may be one of the nodes, the routing tier, or the client) learn about changes in the assignment of partitions to nodes?
This can be modeled as a distributed consensus problem in which nodes of the system perform a set of protocols to agree on a node, but those are very complex to implement, however they are more reliable and many systems are moving towards this direction nowadays.
The other method is having an authoritative service for maintaining this metadata, like ZooKeeper which in this case will maintain a mapping of partitions to nodes. Other actors, such as the routing tier or the partitioning-aware client, can subscribe to this information in ZooKeeper. Whenever a partition changes ownership or a node is added or removed, ZooKeeper notifies the routing tier so that it can keep its routing information up-to-date.
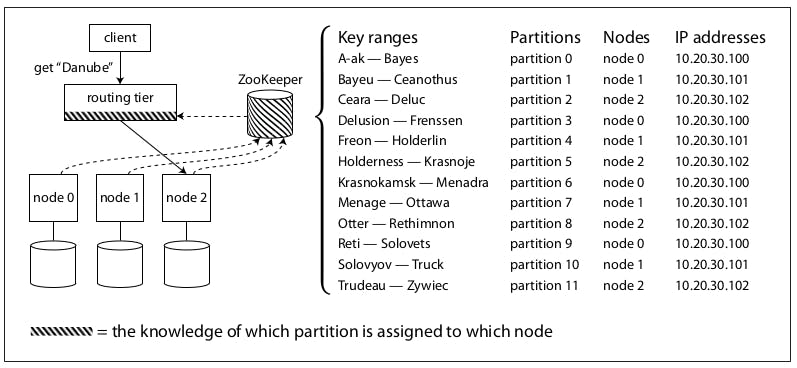
The previous diagram illustrates this further, as we can see we have a ZooKeeper deployed which maintains all needed metadata, like key ranges, partitions, nodes and IP addresses. So basically, it can answer the question of which node to talk to fetch a specific key. In this architecture, we are keeping the routing tier as is and it's communicating with ZooKeeper to route the client request to the correct node. Also, ZooKeeper will always be listening to any changes that might occur for any reason and update its mapping.
As I said before, many systems that started this way, like for example databases like ClickHouse or message queue systems like Kafka ended up trying to ditch ZooKeeper in favor of their version of achieving consensus because it turns out that having a single authoritative service is not very reliable.
Summary
In this article, we discussed how partitioned databases deal with the changing nature of query throughput and data set sizes via performing rebalancing and we discussed some of the approaches that can be used, like the hash mod N, fixed partitions, and dynamic partitioning. Then we discussed how partitioned systems can perform request routing either by using distributed consensus algorithms or authoritative medata mapping services.