
Designing Data Intensive Applications: Ch.6 Partitioning (Part 2: Partitioning and Secondary Indexes)


In the previous article, we introduced the concept of data partitioning as a method to be able to further scale storage and query throughput. We went over one of the approaches that can be used to partition a key-value dataset and learned its uses cases, variations and limitations.
In this article, we introduce a new approach to partitioning data to serve a different use case because the partitioning schemes we have discussed so far rely on a key-value data model which only works well if data is always accessed by its primary key. But in some use cases, we need to make partitioned data searchable by other secondary keys, hence the need for secondary indexes.
In the remainder of this article, we will learn about how partitioning works with secondary indexes and discuss some of its variants, like document-based partitioning or term-based partitioning and learn about their upsides and downsides.
Partitioning and secondary indexes
As we have seen in the previous article, a key-value data model required that we designate one of the fields in a document as the primary key and all the variants of this approach rely on the primary key to spread out data across the system's partitions. If records are only ever accessed via their primary key, we can determine the partition from that key, and use it to route read and write requests to the partition responsible for that key.
The situation gets more complicated when we have secondary indexes on some other fields of the stored documents. A secondary index doesn’t identify a record uniquely, but rather, it’s a way of searching for occurrences of a particular value: like for example, in a database of cars, the primary key might be the license plate, but a secondary index might be created over other searchable attributes like the car make or color.
Secondary indexes are not a luxury in almost all systems, it's very important to serve most use cases, especially ones which complex access patterns. Secondary indexes are the reason for life for some systems like Elasticsearch for example.
The problem with secondary indexes is that they don’t map neatly to partitions. There are two main approaches to partitioning a database with secondary indexes: document-based partitioning and term-based partitioning.
Partitioning secondary indexes by document
For example, imagine you are operating a website for selling used cars where each car listing has a unique ID (let's call it document ID) and you partition the database by the document ID (for example, IDs 0 to 499 in partition 0, 500 to 999 in partition 1, etc).
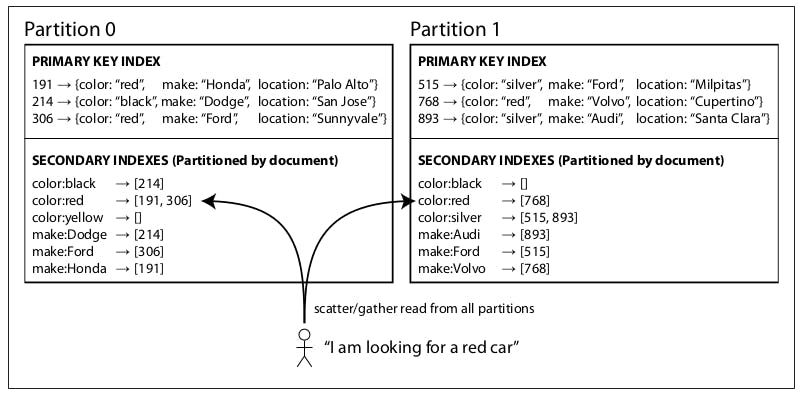
As we can see in the previous diagram, some documents are placed on each partition based on their document ID. In the document-based partitioning approach, each partition is completely separate: each partition maintains its own secondary indexes, covering only the documents in that partition. It doesn’t care what data is stored in other partitions. Similarly, any index maintenance operations are done locally on a specific partition when a new document is added/altered/removed.
However, reading from a document-partitioned secondary index is a little complicated because for example, say you want to fetch all red cars, unless you did something special with the document ID, there are no guarantees that all red cars belong to the same partition, like the in the previous diagram, we have red cars in both partitions 0 and 1. So such queries will have to be sent to all partitions in the system and combine all results when they come back.
This approach to querying a partitioned database is sometimes known as scatter/ gather, and it can make read queries on secondary indexes quite expensive. Even if you query the partitions in parallel, scatter/gather is prone to tail latency amplification (if a single node responds late, it can make the entire operation latent).
Partitioning secondary indexes by term
A different approach to partitioning the secondary index is doing it by term. The word term refers to a field in a document, like for example, color:red or make:Ford and so on. In this approach, rather than each partition having its secondary index (a local index), we can construct a global index that covers data in all partitions. However, we can’t just store that index on one node, since it would likely become a bottleneck and defeat the purpose of partitioning.
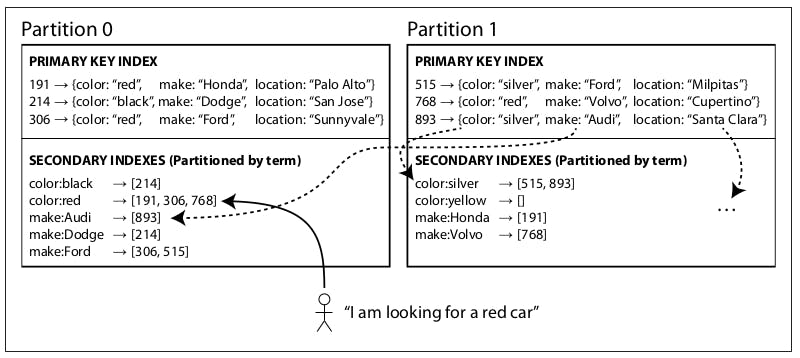
Like in the previous diagram, each secondary index on each partition is a global index, for example, all red cars from all partitions reside in the index on partition 0.
We call this term-based partitioning because the term we’re looking for determines the partition of the index. Here, a term would be color:red, for example, which we know can be found in partition 0.
The advantage of a global (term-partitioned) index over a document-partitioned index is that it can make reads more efficient: rather than doing scatter/gather over all partitions, a client only needs to make a request to the partition containing the term that it wants.
However, the downside of a global index is that writes are now slower and more complicated, because a write to a single document may now affect multiple partitions of the index (for example, if a red car was written in partition 1, it will have to update the color:red entry in the index on partition 0). This also complicates things more because now a single write is spanning multiple partitions and to guarantee that a document would appear immediately in the index we will need to perform a distributed transaction across all partitions affected by a write. In practice, updates to global secondary indexes are often asynchronous (that is, if you read the index shortly after a write, the change you just made may not yet be reflected in the index).
Summary
In this article, we introduced a new use case where partitioned data needs to be accessed by secondary fields rather than primary keys. And we went over the concept of a secondary index and how can it be partitioned either by document or by term and learned the ups and downs of each approach.