


Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases (Part 3)


So in the part 2 article of this series we discussed how Aurora remedies the problem of amplified writes that results from the 6-way replication and how it completely depends on database redo logs and how its processing is offloaded to the storage service. By the end of the last part, it was clear that the log is the database.
The last part ended with a question of how Aurora maintains consistency in a distributed environment yet differing from traditional implementations that uses consensus algorithms for commits, reads, replication and membership changes which amplifies the cost of the underlying storage.
In this article we discuss how Aurora avoids using distributed consensus algorithms under most circumstances.
Making Writes Efficient
As we discussed in previous articles, the Aurora database volume is using a segmented storage model where storage in each data node is partitioned into \(10GB\) segments that individually store their portion of the database volume. Each of these segments is replicated 6-way across 3 AZs in what's called a Protection Group (PG).
The following diagram shows a rough view of an Aurora storage system where the storage volume is partitioned into 2 segments only.
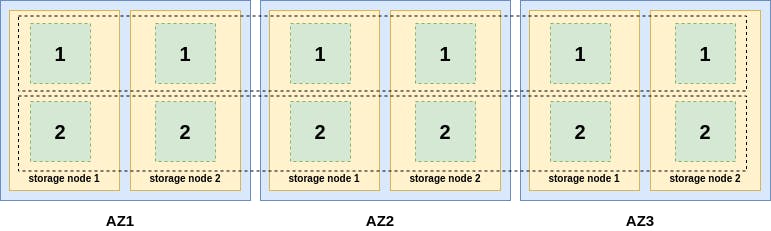
As we can see, each AZ contains 2 storage nodes, each storage nodes contains 2 segments and each segment is replicated 6-ways across the rest of the storage nodes. The dotted horizontal rectangles represent 2 protection groups because each data node has only 2 segments. Each protection group contains 6 segments that represent half of the storage volume. Note that data in segment 1 is different from data in segment 2, so PG1 contains different data than PG2.
In this section, we discuss how Aurora writes redo logs asynchronously and how it establishes local consistency points that are used for commits and regaining consistency upon crash recovery.
Writes in Aurora
As we discussed in the previous article, the only writes that crosses the network are database redo logs. Each log record has a unique identifier called Log Sequence Number (LSN) that generated by the database instance for each redo log record that it produces. Each log record maintains a back link to the previous log record by storing its LSN producing a log chain which is used to materialize data pages on demand by running the applicator which will apply the log chain on the current data page images producing its new image either in the background or on demand. The log chain is also useful for segments to determine gaps in the chain and gossip with other segments in the same protection group to fill in the gaps. As we can see from the previous figure that segments belonging to different protection groups contain different data which means that not all redo logs will go to all segments, rather they will be partitioned and shipped to target protection groups.
In many systems where data is being sent from one component to another, there is always the concern of throughput efficiency which is usually addressed by buffering a batch of writes then send it to the other component which doesn't only improve throughput on the side of the other component but also reduces network packets. We can reason that Aurora faces a similar decision in terms of redo log replication as redo logs are being sent from the database instance to the storage fleet. So we have either one of two choices:
- Send each redo log when generated without any batching. While this approach provides the minimum latency because log records don't have to wait and they are sent directly, it causes too much network packets and reduces write throughput in the storage fleet.
- Buffer a batch of redo logs and then send them. While this approach minimizes network packets and improves write throughput in the storage fleet, it increases latency and creates write jitter since log records will have to wait for new records to be received or for the buffer to timeout which is the worst during low load. The latency here is also greatly amplified due to the segmented storage model as opposed to an unsegmented one, because we explained, writes go to protection groups, so the buffer logic will be on a per protection group basis which increases the probability of a buffer latency since writes are being spread out across multiple protection groups.
Aurora combines the best of both worlds by sending the first redo log received and while the network operation completes, it keeps filling the buffer and then the subsequent write will send all records in the buffer, so it adaptive to load (will act as 1 during low load and will act roughly as 2 during high load). This ensures requests are sent without buffer latency and jitter while packing records together to minimize network packets.
In Aurora, all log writes, including those for commit redo log records, are sent asynchronously to storage nodes, processed asynchronously at the storage node and asynchronously acknowledged back to the database instance.
Storage Consistency Points and Commits
In the previous section we discussed how Aurora handles writes in an asynchronous fashion, but how does it guarantee consistency of the write quorum in such distributed storage configuration?
A traditional databases which is dealing with a local disk would just write redo logs in batches to the local disk and guarantee that they have been made durable. This is to say that if a traditional database failed to write to the local disk, it will know that and it will simple not acknowledge the write. On the other hand, Aurora uses a remote storage service, so if Aurora sends redo logs to be written in the storage service and it gets acknowledgements from the write quorum then it fails to acknowledge write back to the client, it won't be able to naturally clean up the records that were already written in the storage service. This a common problem in distributed systems and is usually solved by the use of consensus algorithm such as, 2PC or Paxos commit. The problem with those algorithms is that they are heavyweight and chatty by nature which incurs a immense network cost and their failure modalities is quite different from that of write quorums that Aurora uses which makes it harder to reason about availability and durability.
Aurora attempts to avoid the need of using such expensive algorithms. In Aurora, when segments receive log records, they may advance a Segment Complete LSN (SCL), representing the latest point in time for which it knows it has received all log records without any gaps. The assumption is that log records may be lost for any reason so storage nodes must be able to retrieve missing logs by gossiping with other members of the protection group using their SCLs.
The following diagram shows a gossip routine between segments in the same protection group in order to fill gaps in their log chains and increase their SCLs.
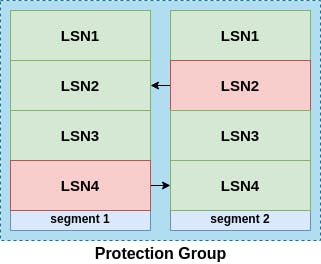
We can see that we have 1 protection group consisting of 2 segments where each segments should have received 4 log records but for some reason, segment 1 is missing log with LSN4, so its SCL is 3 and segment 2 is missing log record with LSN2, so its SCL is 1. Because the 2 segments belong to the same protection group, so they should contain the same data. Segment 1 uses its SCL to determine that it's complete till LSN3, so it needs to retrieve LSN4 and does so by gossiping with segment 2, then it advances its SCL to be 4. The same happens for segment 2 as it retrieves log record with LSN2 from segment 1 via gossiping and advances its SCL to be 4 as well.
When each segment persists a write, it acknowledges the write back to the database instance by sending its new SCL. Once the database instances observes an SCL advance on 4/6 segments of a certain protection group, it can consider the write durable and it advances a Protection Group Complete LSN (PGCL) that it maintains for each protection group in the volume. To understand this better, let's take a look at the following diagram that shows a database with two protection groups, PG1 and PG2, consisting of segments A1-F1 and A2-F2 respectively. In the figure, each solid cell represents a log record acknowledged by a segment, with the odd numbered log records going to PG1 and the even numbered log records going to PG2.
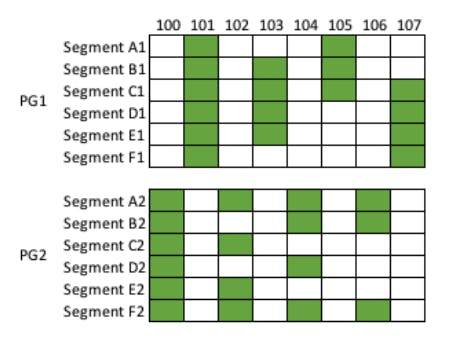
Here, PG1’s PGCL is 103 because 105 has not met write quorum, PG2’s PGCL is 104 because 106 has not met write quorum.
The database instance also maintains a Volume Complete LSN (VCL) that represents the completeness of the entire database volume (across all protection groups), so the database advances the VCL when there are no pending writes preventing the PGCL from advancing for one of its protection groups. So in the previous example, the VCL will be 104 which is the highest point at which all previous log records have met write quorum. The VCL is important to ensure crash recovery.
As we can see, the calculation of the SCL, PGCL and the VCL didn't require the use of any consensus algorithms, just bookkeeping on the side of the database instance and the storage nodes.
A commit is acknowledged by the database back to client when its able to confirm that all data relating to that transactions have been durably persisted. Aurora uses System Commit Number (SCN) to determine if a transaction should be acknowledged or not. A transaction is acknowledged if \(SCN \leq VCL\) which means that the database guarantees completeness up to when the transaction's data was persisted and only then it can acknowledges it back to the client.
How this internally works in Aurora is that it has a worker pool to handle client requests and once the request has been handled (redo logs are being sent to the storage service), the worker thread would stall the request and yield itself back to the common task worker pool. Another worker would spawn when the database advances its VCL and scans all the outstanding transactions' SCNs and acknowledge those with \(SCN \leq VCL\) as described above.
Crash Recovery in Aurora
Aurora is able to avoid distributed consensus during writes and commits by managing consistency points in the database instance rather than establishing consistency across multiple storage nodes. But as we could see from the previous discussions, the bookkeeping done by the database instance lives in its ephemeral state which is lost if the database crashes or is restarted. This make is essential that Aurora should be able to efficiently regain consistency on crash recovery, which is basically recomputing the PGCLs and the VCL from the SCLs stored at the data nodes. The following diragram shows a possible state that Aurora could be in before a crash occurs and the expected state immediately after a crash recovery.
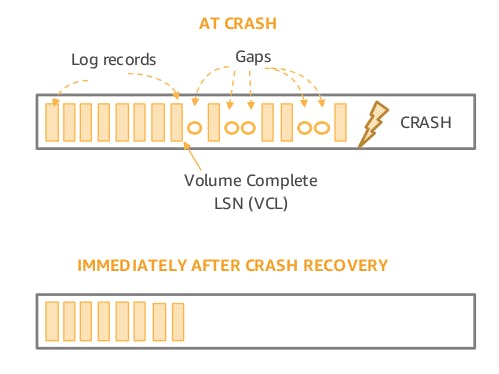
When opening a database volume, either for crash recovery or for a normal startup, the database instance must be able to reach at least a read quorum for each protection group comprising the storage volume. Then it uses the SCLs sent by the storage nodes to recompute the PGCL and the VCL. Now the database instance knows the point at which it guarantees completeness which is the VCL, then it issues a truncation operation that annuls all log records with \(LSN > VCL\) and thus regaining consistency. If Aurora is unable to establish write quorum for one of its protection groups, it initiates repair from the available read quorum to rebuild the failed segments.
Making Reads Efficient
Reads are one of the few operations in Aurora that would have to block waiting for I/O. In quorum systems, the read cost is amplified by the size of the read quorum, for example, a cache miss in Aurora would require at least 3 reads to achieve quorum and more likely 5 or 6 reads (remember that Aurora sends the read request to all nodes, not just 3 to mask out any interment failures or stall on any of the storage nodes). Also note that reads in Aurora would fetch actual data pages that will be transferred on the network unlike writes that only transferred redo logs which are much smaller. So it's clear that a system with such specs will compare poorly to traditional non-quorum databases.
In this section we discuss how Aurora avoids quorum reads and how reads are scaled across read replicas.
Avoiding quorum reads
Aurora uses what's called read views in order to support snapshot isolation using Multi-Version Concurrency Control (MVCC). A read view is a point in time before which a transaction can see all changes and after which it can only see changes done by that transaction only. Aurora MySQL does this by establishing the most recent SCN and a list of transactions active as of that LSN and make sure that any data pages seen by a read request be at the read view LSN and ignores any transactions either active as of that LSN or started after that LSN.
Aurora doesn't need to do quorum reads because through its bookkeeping of writes and consistency points, it knows which segments have the most recent durable version of a data page and can directly request it from that specific segment. It's clear here that avoiding amplification of reads by avoid quorum reads subjects Aurora to interment slow storage nodes, this is however is resolved by measuring the read latency on segments and choosing the segment which the least latency. A read request might also issue another read request to another segment to ensure up to date latency measurements. If a request is taking longer than expected, will issue a read to another storage node and accept whichever one returns first which caps the latency due to slow or unavailable segments without amplifying network I/Os the same way a quorum read would have done.
Scaling Reads Using Read Replicas
It's a common idea in database systems to scale reads by adding read replicas and Aurora is no exception. Having read replicas would require writers to replicate either logical statements or physical redo logs to read replicas to make them up to date. This can either be done synchronously if read replicas are intended for failover or asynchronously if replica lag and data loss on failover is acceptable.
Both synchronous and asynchronous replication have problems as follows:
- Synchronous replication: Introduces jitter and failures in the write path if replication failed.
- Asynchronous replication: Introduces data loss in case the writer failed after it acknowledged a write and before it replicated that write to the read replica.
Both types of replications would require a materialized database state in the read replica either by copying the database volume of by doubling the setup (having 2 volumes) which wastes a considerable portion of the resources in the read replica in serving writes generated via replication rather than serving read requests.
Because Aurora decouples the compute tier and the storage tier, both the writer and the replicas can share the storage volume. This allows Aurora to use asynchronous replication of redo logs from the writer to the reader but the reader only needs to apply the redo logs on pages in its cache, otherwise it can safely discard the redo logs because they will get applied to data pages inside the storage service in the write path and the read replicas can simply read them from the shared storage volume.
This minimizes replica lag, guarantees that there will be no data loss on failover and frees the resources on the reader to actually serve read requests. This also makes the number of read replicas scale up and down independently of the storage service which is extremely flexible for varying workloads.
Failures and Quorum Membership
As we saw from all the previous discussions that Aurora depends on quorums for write and read (in case the runtime state was lost). So managing quorum sets, quorum membership changes is essential. The thing with membership changes is that it fences out a member of the quorum which is an expensive process and this why systems are very conservative while performing quorum changes which ends up increasing latency and increasing the risk of breaking quorum.
In this section we discuss how how Aurora supports I/O processing, multiple faults, and member re-introduction while performing quorum membership changes.
Using Quorum Sets to Change Membership
Consider a protection group with the six segments A, B, C, D, E, and F. In Aurora, the write quorum is any four members out of this set of six, and the read quorum is any three members. Now let's assume that the host manager that monitors the database health stops receiving health checks from segment F and now wants to replace it with another segment G. However, F may be encountering a temporary failure and may come back quickly. It may be processing requests, but not be observable to this monitor. Or it may just be busy. At the same time, we do not want to wait to see if F comes back. It may be permanently down and so waiting extends the duration of impairment during which we may see additional faults and increased latency that may eventually ends up breaking quorum. On the other hand, we don't want to aggressively do expensive membership changes.
The following figure shows how Aurora combines the best of both worlds when it comes to performing quorum membership changes.

As we can see from the above diagram that rather than attempting to directly transition from \(ABCDEF\) to \(ABCDEG\), the transition happens in two steps. First, G is added to the quorum, moving the write set to \(4/6 \hspace{0.1cm} ABCDEF \hspace{0.2cm} \wedge \hspace{0.2cm} 4/6 \hspace{0.1cm} ABCDEG\). The read set is therefore \(3/6 \hspace{0.1cm} ABCDEF \hspace{0.2cm} \lor \hspace{0.2cm} 3/6 \hspace{0.1cm} ABCDEG\). If F comes back, a second membership change back to \(ABCDEF\) is made. If F continues to be down and once G has completed hydrating from its peers, a membership change to \(ABCDEG\) is made. Durable state is only discarded when a fully repaired quorum is achieved.
Let's now consider what happens if E also fails while we are replacing F with G and we wish to replace it with H. In this case, we would move to a write quorum set of \(((4/6 \hspace{0.1cm} ABCDEF \hspace{0.2cm} \wedge \hspace{0.2cm} 4/6 \hspace{0.1cm} ABCDEG) \hspace{0.2cm} \wedge \hspace{0.2cm} (4/6 \hspace{0.1cm} ABCDFH \hspace{0.2cm} \wedge \hspace{0.2cm} 4/6 \hspace{0.1cm} ABCDGH))\).
Quorum membership changes have the same failure characteristics as read and write I/Os. Using Boolean logic, we can prove that each transition is correct, safe and reversible.
Conclusion
This wraps it up for this series, I hope it was useful!